详解SQL中Group By的用法
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
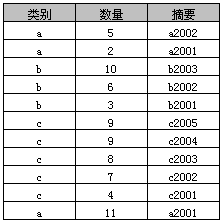
3、简单Group By
示例1
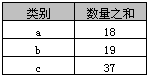
select 类别, sum(数量) as 数量之和 from A group by 类别
返回结果如下表,实际上就是分类汇总。
4、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和 from A group by 类别 order by sum(数量) desc
返回结果如下表
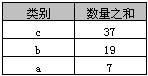
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
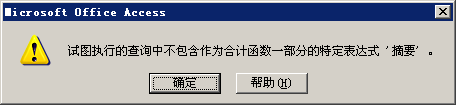
select 类别, sum(数量) as 数量之和, 摘要 from A group by 类别 order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
6、Group By All
示例4
select 类别, 摘要, sum(数量) as 数量之和 from A group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表
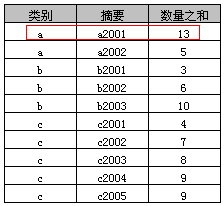
“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和 from A group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
函数
作用
支持性
sum(列名)
求和
max(列名)
最大值
min(列名)
最小值
avg(列名)
平均值
first(列名)
第一条记录
仅Access支持
last(列名)
最后一条记录
仅Access支持
count(列名)
统计记录数
注意和count(*)的区别
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
•where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
•having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A
group by 类别
having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A
where 数量 gt;8
group by 类别
having SUM(数量) gt; 10
9、Compute 和 Compute By
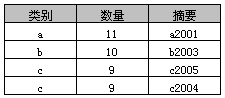
select * from A where 数量 > 8
执行结果:
示例10:Compute
select *from A where 数量>8 ompute max(数量),min(数量),avg(数量)
执行结果如下:

compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
select *from A where 数量>8 order by 类别 compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
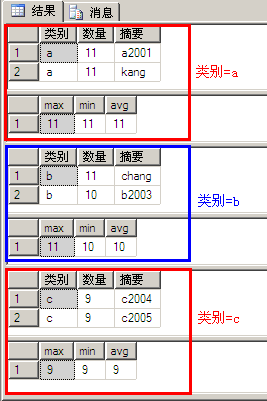
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
•compute子句必须与order by子句用一起使用
•compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
相关推荐
-
浅析SQL语句中GROUP BY的用法
GROUP BY 是分组查询, 一般 GROUP BY 是和 聚合函数配合使用,你可以想想 你用了GROUP BY 按 ITEM.ITEMNUM 这个字段分组,那其他字段内容不同,变成一对多又改如何显示呢,比如下面所示 A B 1 abc 1 bcd 1 asdfg select A,B from table group by A 你说这样查出来是什么结果, A B abc 1 bcd asdfg 右边3条如何变成一条,所以需要用到聚合函数,比如 select A
-

mysql筛选GROUP BY多个字段组合时的用法分享
想实现这样一种效果如果使用group by一个条件的话,得到的结果会少了很多,如何多个条件组合筛选呢 复制代码 代码如下: group by fielda,fieldb,fieldc... 循环的时候可以通过判断后一个跟前面一个是否相同来分组,一个示例 复制代码 代码如下: $result = mysql_query("SELECT groups,name,goods FROM table GROUP BY groups,name ORDER BY name"); $arr = arr
-
mssql CASE,GROUP BY用法
复制代码 代码如下: --create database dbTemp use dbTemp create table test ( Pid int identity(1,1) not null primary key, Years datetime, IsFirstSixMonths int default(0), --0表示上半年1表示下半年-- TotalCome int ) insert test select '2007-1-1',0,50 union select '2007-3-1
-
总结下sqlserver group by 的用法
今天用实例总结一下group by的用法. 归纳一下:group by:ALL ,Cube,RollUP,Compute,Compute by 创建数据脚本 Create Table SalesInfo (Ctiy nvarchar(50), OrderDate datetime, OrderID int ) insert into SalesInfo select N'北京','2014-06-09',1001 union all select N'北京','2014-08-09',1002
-
MySQL中distinct与group by语句的一些比较及用法讲解
在数据表中记录了用户验证时使用的书目,现在想取出所有书目,用DISTINCT和group by都取到了我想要的结果,但我发现返回结果排列不同,distinct会按数据存放顺序一条条显示,而group by会做个排序(一般是ASC). DISTINCT 实际上和 GROUP BY 操作的实现非常相似,只不过是在 GROUP BY 之后的每组中只取出一条记录而已.所以,DISTINCT 的实现和 GROUP BY 的实现也基本差不多,没有太大的区别,同样可以通过松散索引扫描或者是
-
详解SQL中Group By的用法
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组. 1.概述 "Group By"从字面意义上理解就是根据"By"指定的规则对数据进行分组,所谓的分组就是将一个"数据集"划分成若干个"小区域",然后针对若干个"小区域"进行数据处理. 2.原始表 3.简单Group By 示例1 select 类别, sum(数量) as 数量之和 from A group by 类别 返回结果如下表
-
详解SQL中Group By的使用教程
1.概述 "Group By"从字面意义上理解就是根据"By"指定的规则对数据进行分组,所谓的分组就是将一个"数据集"划分成若干个"小区域",然后针对若干个"小区域"进行数据处理. 2.原始表 3.简单Group By示例1 select 类别, sum(数量) as 数量之和from Agroup by 类别 返回结果如下表,实际上就是分类汇总. 4.Group By 和 Order By示例2 sele
-
详解SQL之CASE WHEN具体用法
简单CASE WHEN函数: CASE SCORE WHEN 'A' THEN '优' ELSE '不及格' END CASE SCORE WHEN 'B' THEN '良' ELSE '不及格' END CASE SCORE WHEN 'C' THEN '中' ELSE '不及格' END 等同于,使用CASE WHEN条件表达式函数实现: CASE WHEN SCORE = 'A' THEN '优' WHEN SCORE = 'B' THEN '良' WHEN SCORE = 'C' THE
-
一文详解SQL 中的三值逻辑
目录 1. 前言 2. 两种 Null 3. 为什么是 is Null 而不是 = Null ? 4. 第三个真值 “unknown” 5. 包含三值逻辑的真值表 6. “排中律” 不再成立 7. CASE 表达式和 NULL 8. NOT IN 和 NOT EXISTS 不是等价的 9. 限定谓词和 NULL 10. 限定谓词和极值函数不是等价的 11. 聚合函数和 Null 1. 前言 大多数编程语言都是基于二值逻辑的,即逻辑真值只有真和假两个.而 SQL 语言则采用一种特别的逻辑体系——三
-
详解Java8中Optional的常见用法
目录 一. 简介 二.Java8 之前,空指针异常判断 三.Optional的使用 1.创建Optional实例 2.访问 Optional 对象的值 3.返回默认值 4.返回异常 (常用) 5.转换值 6.过滤值 一. 简介 Opitonal是java8引入的一个新类,目的是为了解决空指针异常问题.本质上,这是一个包含有可选值的包装类,这意味着 Optional 类既可以含有对象也可以为空. Optional 是 Java 实现函数式编程的强劲一步,并且帮助在范式中实现.但是 Optional
-
带例子详解Sql中Union和Union ALL的区别
目录 前言 提前准备 测试 Union Union ALL Union Union All union Union All 最后 前言 一段时间没有用Union和Union,再用的时候忘了怎么用了...所以做一篇文章来记录自己学Union和Union的经历. 提前准备 在Sql Server 创建两张表,下面是创建表sql语句. create table Student1( Id varchar(50) not null, Name varchar(50) not null, Age int n
-
一文详解Python中logging模块的用法
目录 一.低配logging 1.v1 2.v2 3.v3 二.高配logging 1.配置日志文件 2.使用日志 三.Django日志配置文件 一.低配logging 日志总共分为以下五个级别,这个五个级别自下而上进行匹配 debug-->info-->warning-->error-->critical,默认最低级别为warning级别. 1.v1 import logging logging.debug('调试信息') logging.info('正常信息') logging
-
详解Vue中watch的高级用法
假设有如下代码: <div> <p>FullName: {{fullName}}</p> <p>FirstName: <input type="text" v-model="firstName"></p> </div> new Vue({ el: '#root', data: { firstName: 'Dawei', lastName: 'Lou', fullName: '' },
-
详解sql中的参照完整性(一对一,一对多,多对多)
一.参照完整性 参照完整性指的就是多表之间的设计,主要使用外键约束. 多表设计: 一对多.多对多.一对一设计 1.一对多 关联主要语句: constraint cus_ord_fk foreign key (customer_id) REFERENCES customer(id) 创建客户表--订单表 一个客户可以订多份订单,每份订单只能有一个客户. -- 关联(1对N) create table customer( id int PRIMARY KEY auto_increment, name
-
详解Python中openpyxl模块基本用法
Python操作EXCEL库的简介 1.1 Python官方库操作excel Python官方库一般使用xlrd库来读取Excel文件,使用xlwt库来生成Excel文件,使用xlutils库复制和修改Excel文件,这三个库只支持到Excel2003. 1.2 第三方库openpyxl介绍 第三方库openpyxl(可读写excel表),专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易. 注意:如果文字编码是"gb2312" 读取后就会显示乱码,请