T-SQL查询为何慎用IN和NOT IN详解
目录
- 前言
- 【测试一:in子查询】
- 【测试二:not in子查询】
- 总结:
前言
今天突然想到之前在书上看到的一个例子,竟然想不起来了.
于是翻书找出来,测试一下.
-- drop table father,son create table father(fid int,name varchar(10),oid int) create table son(sid int,name varchar(10),fid int) insert into father(fid,name,oid) values(1,'father',5),(2,'father',9),(3,'father',null),(4,'father',0) insert into son(sid,name,fid) values(1,'son',2),(2,'son',2),(3,'son',3),(4,'son',null),(5,'son',null) select * from father select * from son
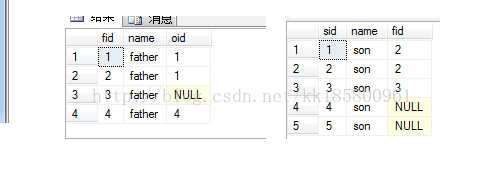
in和exists差异开始测试吧,现在测试使用in、not in 可能带来的“错误”。之所以错误,是因为我们总是以自然语言去理解SQL,却忽略了数学中的逻辑语法。不废话了,测试看看吧!
【测试一:in子查询】
--返回在son中存在的所有father的数据 --正确的写法: select * from father where fid in(select fid from son) --错误的写法: select * from father where fid in(select oid from son)
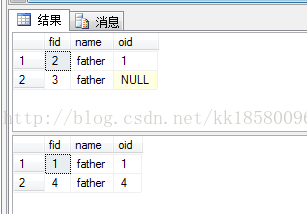
说明:
两个查询都执行没有出错,但是第二个tsql的子查询写错了。子查询(select oid from son)实际单独执行会出错,因为表son不存在字段oid,但是在这里系统不会提示错误。而且father表有4行数据,所有子查询扫描了4次son表,但是第二个查询中,实际也只扫描了1次son表,也就是son表没有用到。
即使这样写也 不会出错: select*fromfatherwherefidin(selectoid)
这个查询的意思是,表father中每行的fid与oid比较,相同则返回值。
实际查询是这样的: select * from father where fid = oid
测试一中,fid in(select fid from son)子查询中包含null值,所以 fid in(null)返回的是一个未知值。但是在刷选器中,false和unknown的处理方式类似。因此第一个子查询返回了正确的结果集。
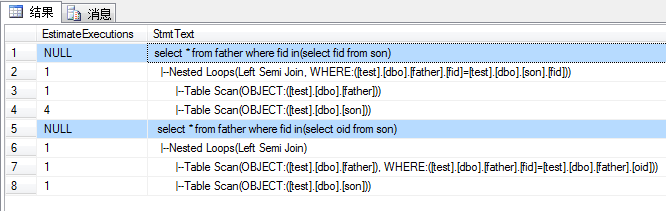
【测试二:not in子查询】
--返回在son中不存在的所有father的数据 --错误的写法: select * from father where fid not in(select fid from son) --错误的写法: select * from father where fid not in(select oid from son) --正确的写法: select * from father where fid not in(select fid from son where fid is not null)
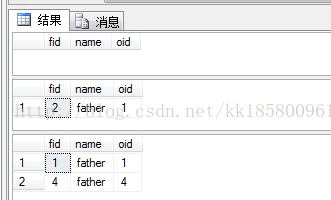
说明:
查看select fid from son,子查询中有空值null,子查询中的值为(2,3,null),谓词fid in(2,3,null)永远不会返回false,只反会true或unknown,所以谓词fidnot in(2,3,null)只返回not true 或not unknown,结果都不会是true。所以当子查询存在null时,not in和not exists 在逻辑上是不等价的。
总结:
In 或 not in在SQL语句中经常用到,尤其当子查询中有空值的时候,要谨慎考虑。因为即使写了“正确”的脚本,但是返回结果却不正确,也不出错。在不是很理解的情况下,最好使用 exists和 not exists来替换。而且exists查询更快一些,因为只要在子查询找到第一个符合的值就不继续往下找了,所以能用exists就用吧。
select *fromfatherawhereexists(select 1fromsonbwherea.fid=b.fid) select * from father awherenotexists(select 1fromsonbwherea.fid=b.fid)
到此这篇关于T-SQL查询为何慎用 IN和NOT IN详解的文章就介绍到这了,更多相关T-SQL查询慎用 IN和NOT IN内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SQL查询中in和exists的区别分析
select * from A where id in (select id from B); select * from A where exists (select 1 from B where A.id=B.id); 对于以上两种情况,in是在内存里遍历比较,而exists需要查询数据库,所以当B表数据量较大时,exists效率优于in. 1.select * from A where id in (select id from B); in()只执行一次,它查出B表中的所有id字段并缓存
-
在SQL查询中使用LIKE来代替IN查询的方法
如下: 复制代码 代码如下: SELECT * FROM Orders WHERE OrderGUID IN('BC71D821-9E25-47DA-BF5E-009822A3FC1D','F2212304-51D4-42C9-AD35-5586A822258E') 可以看出直接在IN后面跟ID的集合需要将每一个ID都用单引号引起来.在实际应用中会遇到这么一种情况,在界面中收集的是一串GUID的拼接字符串,中间以逗号隔开,如果作为参数传到一个存储过程中执行,最终生成的语句会是下面这样: 复制代码
-

mysql查询条件not in 和 in的区别及原因说明
先写一个SQL SELECT DISTINCT from_id FROM cod WHERE cod.from_id NOT IN (37, 56, 57) 今天在写SQL的时候,发现这个查的结果不全,少了NULL值的情况,not in 的时候竟然把null也排除了 用 in 的时候却没有包含null 感觉是mysql设计的不合理 因为一直认为in 和 not in 正好应该互补才是,就像这样查的应该是全部的一样: SELECT DISTINCT from_id FROM cod WHERE c
-
T-SQL查询为何慎用IN和NOT IN详解
目录 前言 [测试一:in子查询] [测试二:not in子查询] 总结: 前言 今天突然想到之前在书上看到的一个例子,竟然想不起来了. 于是翻书找出来,测试一下. -- drop table father,son create table father(fid int,name varchar(10),oid int) create table son(sid int,name varchar(10),fid int) insert into father(fid,name,oid) valu
-
Mysql系列SQL查询语句书写顺序及执行顺序详解
目录 1.一个完整SQL查询语句的书写顺序 2.一个完整的SQL语句执行顺序 3.关于select和having执行顺序谁前谁后的说明 1.一个完整SQL查询语句的书写顺序 -- "mysql语句编写顺序" 1 select distinct * 2 from 表(或结果集) 3 where - 4 group by -having- 5 order by - 6 limit start,count -- 注:1.2属于最基本语句,必须含有. -- 注:1.2可以与3.4.5.6中任一
-
SQL行转列和列转行代码详解
行列互转,是一个经常遇到的需求.实现的方法,有case when方式和2005之后的内置pivot和unpivot方法来实现. 在读了技术内幕那一节后,虽说这些解决方案早就用过了,却没有系统性的认识和总结过.为了加深认识,再总结一次. 行列互转,可以分为静态互转,即事先就知道要处理多少行(列);动态互转,事先不知道处理多少行(列). --创建测试环境 USE tempdb; GO IF OBJECT_ID('dbo.Orders') IS NOT NULL DROP TABLE dbo.Orde
-
Sql Server 开窗函数Over()的使用实例详解
利用over(),将统计信息计算出来,然后直接筛选结果集 declare @t table( ProductID int, ProductName varchar(20), ProductType varchar(20), Price int) insert @t select 1,'name1','P1',3 union all select 2,'name2','P1',5 union all select 3,'name3','P2',4 union all select 4,'name4
-
SQL Server中identity(自增)的用法详解
一.identity的基本用法 1.含义 identity表示该字段的值会自动更新,不需要我们维护,通常情况下我们不可以直接给identity修饰的字符赋值,否则编译时会报错 2.语法 列名 数据类型 约束 identity(m,n) m表示的是初始值,n表示的是每次自动增加的值 如果m和n的值都没有指定,默认为(1,1) 要么同时指定m和n的值,要么m和n都不指定,不能只写其中一个值,不然会出错 3.实例演示 不指定m和n的值 create table student1 ( sid int p
-
SQL bool盲注和时间盲注详解
目录 一.bool盲注和时间盲注常用函数 二.bool盲注和时间盲注payload 1.SQL注入点探测 2.猜解数据库名 3.猜解表名 4.猜解字段名 5.猜解数据 今天继续给大家介绍Linux运维相关知识,本文主要内容是SQL bool盲注和时间盲注. 免责声明:本文所介绍的内容仅做学习交流使用,严禁利用文中技术进行非法行为,否则造成一切严重后果自负!再次强调:严禁对未授权设备进行渗透测试! 一.bool盲注和时间盲注常用函数 1.休眠函数sleep()是SQL语句中用于休眠的函数,时间盲注
-
MyBatis-Plus实现条件查询的三种格式例举详解
目录 常规格式 链式编程格式 lambda格式(推荐) 条件查询null判定 常规格式 常规格式即创建一个Wrapper的实现类QueryWrapper对象,将其传给selectList方法内部 QueryWrapper qw = new QueryWrapper(); //lt是小于,id小于5 qw.lt("id",5); List<User> users = userDao.selectList(qw); System.out.println(users); qw中的
-
SQL行列转换超详细四种方法详解
目录 前言 1.使用join拼接 2.自然拼接 3.使用union拼接 4.经典sum+if 总结 前言 本文详细的介绍了多个方法实现列转行,行转列,并提供了案例的材料,有需要的小伙伴可以自行获取与学习~ 数据准备 CREATE TABLE `score` ( `id` varchar(255), `subject` char(10), `score` int ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `score`(`id`,`subj
-
SQL数据去重的3种方法实例详解
目录 1.使用distinct去重 2.使用group by 3.使用ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST 3.1 ROW_NUMBER() OVER 3.2 GROUP BY 和 COLLECT_SET/COLLECT_LIST distinct与group by的去重方面的区别 使用去重distinct方法的示例详解 总结 1.使用distinct去重 distinct用来查询不重复记录的条数,用count(disti
-
基于SQL中SET与SELECT赋值的区别详解
最近的项目写的SQL比较多,经常会用到对变量赋值,而我使用SET和SELECT都会达到效果.那就有些迷惑,这两者有什么区别呢?什么时候哪该哪个呢?经过网上的查询,及个人练习,总结两者有以下几点主要区别:假定有设定变量: 复制代码 代码如下: DECLARE @VAR1 VARCHAR(1) DECLARE @VAR2 VARCHAR(2) 1.SELECT可以在一条语句里对多个变量同时赋值,而SET只能一次对一个变量赋值,如下: 复制代码 代码如下: SELECT @VAR1='Y',@VAR2