python中k-means和k-means++原理及实现
目录
- 前言
- k-means原理
- k-means++原理
- k-means及k-means++代码实现
- k-means实现
- k-means++实现
- 参考文档
前言
k-means算法是无监督的聚类算法,实现起来较为简单,k-means++可以理解为k-means的增强版,在初始化中心点的方式上比k-means更友好。
k-means原理
k-means的实现步骤如下:
- 从样本中随机选取k个点作为聚类中心点
- 对于任意一个样本点,求其到k个聚类中心的距离,然后,将样本点归类到距离最小的聚类中心,直到归类完所有的样本点(聚成k类)
- 对每个聚类求平均值,然后将k个均值分别作为各自聚类新的中心点
- 重复2、3步,直到中心点位置不在变化或者中心点的位置变化小于阈值
优点:
- 原理简单,实现起来比较容易
- 收敛速度较快,聚类效果较优
缺点:
- 初始中心点的选取具有随机性,可能会选取到不好的初始值。
k-means++原理
k-means++是k-means的增强版,它初始选取的聚类中心点尽可能的分散开来,这样可以有效减少迭代次数,加快运算速度,实现步骤如下:
- 从样本中随机选取一个点作为聚类中心
- 计算每一个样本点到已选择的聚类中心的距离,用D(X)表示:D(X)越大,其被选取下一个聚类中心的概率就越大
- 利用轮盘法的方式选出下一个聚类中心(D(X)越大,被选取聚类中心的概率就越大)
- 重复步骤2,直到选出k个聚类中心
- 选出k个聚类中心后,使用标准的k-means算法聚类
这里不得不说明一点,有的文献中把与已选择的聚类中心最大距离的点选作下一个中心点,这个说法是不太准确的,准的说是与已选择的聚类中心最大距离的点被选作下一个中心点的概率最大,但不一定就是改点,因为总是取最大也不太好(遇到特殊数据,比如有一个点离某个聚类所有点都很远)。
一般初始化部分,始终要给些随机。因为数据是随机的。
尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
现在重点是利用轮盘法的方式选出下一个聚类中心,我们以一个例子说明K-means++是如何选取初始聚类中心的。
假如数据集中有8个样本,分布分布以及对应序号如下图所示:
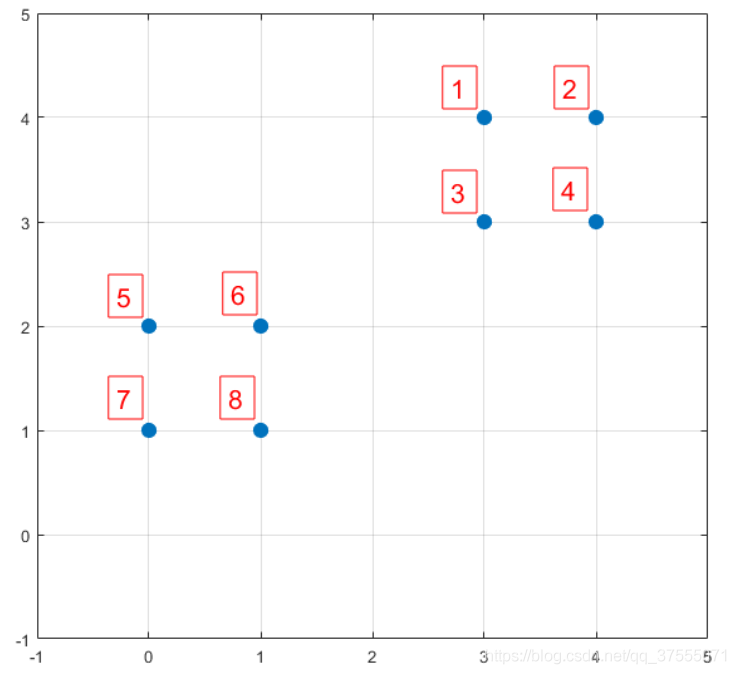
我们先用 k-means++的步骤1选择6号点作为第一个聚类中心,然后进行第二步,计算每个样本点到已选择的聚类中心的距离D(X),如下所示:
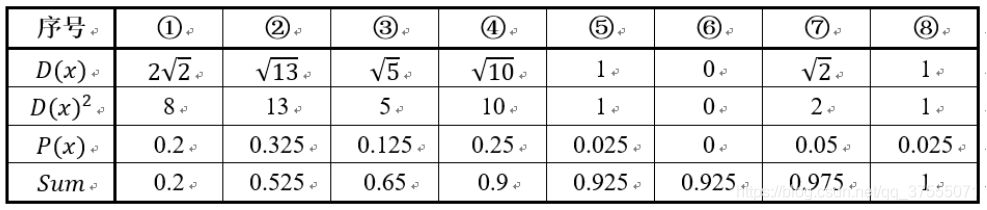
- D(X)是每个样本点与所选取的聚类中心的距离(即第一个聚类中心)
- P(X)每个样本被选为下一个聚类中心的概率
- Sum是概率P(x)的累加和,用于轮盘法选择出第二个聚类中心。
然后执行 k-means++的第三步:利用轮盘法的方式选出下一个聚类中心,方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。
在上图1号点区间为[0,0.2),2号点的区间为[0.2, 0.525),4号点的区间为[0.65,0.9)
从上表可以直观的看到,1号,2号,3号,4号总的概率之和为0.9,这4个点正好是离第一个初始聚类中心(即6号点)较远的四个点,因此选取的第二个聚类中心大概率会落在这4个点中的一个,其中2号点被选作为下一个聚类中心的概率最大。
k-means及k-means++代码实现
这里选择的中心点是样本的特征(不是索引),这样做是为了方便计算,选择的聚类点(中心点周围的点)是样本的索引。
k-means实现
# 定义欧式距离
import numpy as np
def get_distance(x1, x2):
return np.sqrt(np.sum(np.square(x1-x2)))
import random
# 定义中心初始化函数,中心点选择的是样本特征
def center_init(k, X):
n_samples, n_features = X.shape
centers = np.zeros((k, n_features))
selected_centers_index = []
for i in range(k):
# 每一次循环随机选择一个类别中心,判断不让centers重复
sel_index = random.choice(list(set(range(n_samples))-set(selected_centers_index)))
centers[i] = X[sel_index]
selected_centers_index.append(sel_index)
return centers
# 判断一个样本点离哪个中心点近, 返回的是该中心点的索引
## 比如有三个中心点,返回的是0,1,2
def closest_center(sample, centers):
closest_i = 0
closest_dist = float('inf')
for i, c in enumerate(centers):
# 根据欧式距离判断,选择最小距离的中心点所属类别
distance = get_distance(sample, c)
if distance < closest_dist:
closest_i = i
closest_dist = distance
return closest_i
# 定义构建聚类的过程
# 每一个聚类存的内容是样本的索引,即对样本索引进行聚类,方便操作
def create_clusters(centers, k, X):
clusters = [[] for _ in range(k)]
for sample_i, sample in enumerate(X):
# 将样本划分到最近的类别区域
center_i = closest_center(sample, centers)
# 存放样本的索引
clusters[center_i].append(sample_i)
return clusters
# 根据上一步聚类结果计算新的中心点
def calculate_new_centers(clusters, k, X):
n_samples, n_features = X.shape
centers = np.zeros((k, n_features))
# 以当前每个类样本的均值为新的中心点
for i, cluster in enumerate(clusters): # cluster为分类后每一类的索引
new_center = np.mean(X[cluster], axis=0) # 按列求平均值
centers[i] = new_center
return centers
# 获取每个样本所属的聚类类别
def get_cluster_labels(clusters, X):
y_pred = np.zeros(np.shape(X)[0])
for cluster_i, cluster in enumerate(clusters):
for sample_i in cluster:
y_pred[sample_i] = cluster_i
#print('把样本{}归到{}类'.format(sample_i,cluster_i))
return y_pred
# 根据上述各流程定义kmeans算法流程
def Mykmeans(X, k, max_iterations,init):
# 1.初始化中心点
if init == 'kmeans':
centers = center_init(k, X)
else: centers = get_kmeansplus_centers(k, X)
# 遍历迭代求解
for _ in range(max_iterations):
# 2.根据当前中心点进行聚类
clusters = create_clusters(centers, k, X)
# 保存当前中心点
pre_centers = centers
# 3.根据聚类结果计算新的中心点
new_centers = calculate_new_centers(clusters, k, X)
# 4.设定收敛条件为中心点是否发生变化
diff = new_centers - pre_centers
# 说明中心点没有变化,停止更新
if diff.sum() == 0:
break
# 返回最终的聚类标签
return get_cluster_labels(clusters, X)
# 测试执行
X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]])
# 设定聚类类别为2个,最大迭代次数为10次
labels = Mykmeans(X, k = 2, max_iterations = 10,init = 'kmeans')
# 打印每个样本所属的类别标签
print("最后分类结果",labels)
## 输出为 [1. 1. 1. 0. 0.]
# 使用sklearn验证 from sklearn.cluster import KMeans X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]]) kmeans = KMeans(n_clusters=2,init = 'random').fit(X) # 由于center的随机性,结果可能不一样 print(kmeans.labels_)
k-means++实现
## 得到kmean++中心点
def get_kmeansplus_centers(k, X):
n_samples, n_features = X.shape
init_one_center_i = np.random.choice(range(n_samples))
centers = []
centers.append(X[init_one_center_i])
dists = [ 0 for _ in range(n_samples)]
# 执行
for _ in range(k-1):
total = 0
for sample_i,sample in enumerate(X):
# 得到最短距离
closet_i = closest_center(sample,centers)
d = get_distance(X[closet_i],sample)
dists[sample_i] = d
total += d
total = total * np.random.random()
for sample_i,d in enumerate(dists): # 轮盘法选出下一个聚类中心
total -= d
if total > 0:
continue
# 选取新的中心点
centers.append(X[sample_i])
break
return centers
X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]])
# 设定聚类类别为2个,最大迭代次数为10次
labels = Mykmeans(X, k = 2, max_iterations = 10,init = 'kmeans++')
print("最后分类结果",labels)
## 输出为 [1. 1. 1. 0. 0.]
# 使用sklearn验证 X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]]) kmeans = KMeans(n_clusters=2,init='k-means++').fit(X) print(kmeans.labels_)
参考文档
K-means与K-means++
K-means原理、优化及应用
到此这篇关于python中k-means和k-means++原理及实现的文章就介绍到这了,更多相关python k-means和k-means++ 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python利用K-Means算法实现对数据的聚类案例详解
目的是为了检测出采集数据中的异常值.所以很明确,这种情况下的簇为2:正常数据和异常数据两大类 1.安装相应的库 import matplotlib.pyplot as plt # 用于可视化 from sklearn.cluster import KMeans # 用于聚类 import pandas as pd # 用于读取文件 2.实现聚类 2.1 读取数据并可视化 # 读取本地数据文件 df = pd.read_excel("../data/output3.xls", heade
-
利用Python如何实现K-means聚类算法
目录 前言 算法原理 目标函数 算法流程 Python实现 总结 前言 K-Means 是一种非常简单的聚类算法(聚类算法都属于无监督学习).给定固定数量的聚类和输入数据集,该算法试图将数据划分为聚类,使得聚类内部具有较高的相似性,聚类与聚类之间具有较低的相似性. 算法原理 1. 初始化聚类中心,或者在输入数据范围内随机选择,或者使用一些现有的训练样本(推荐) 2. 直到收敛 将每个数据点分配到最近的聚类.点与聚类中心之间的距离是通过欧几里德距离测量得到的. 通过将聚类中心的当前估计值设置为属于
-
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心. 3.对每个点确定其聚类中心点. 4.再计算其聚类新中心. 5.重复以上步骤直到满足收敛要求.(通常就是确定的中心点不再改变. 优点: 1.是解决聚类问题的一种经典算法,简单.快速 2.对处理大数据集,该算法保持可伸缩性和高效率 3.当结果簇是密集的,它的效果较好 缺点 1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用 2.必须事先给出k(要生成的簇的数
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
Python用K-means聚类算法进行客户分群的实现
一.背景 1.项目描述 你拥有一个超市(Supermarket Mall).通过会员卡,你用有一些关于你的客户的基本数据,如客户ID,年龄,性别,年收入和消费分数. 消费分数是根据客户行为和购买数据等定义的参数分配给客户的. 问题陈述:你拥有这个商场.想要了解怎么样的顾客可以很容易地聚集在一起(目标顾客),以便可以给营销团队以灵感并相应地计划策略. 2.数据描述 字段名 描述 CustomerID 客户编号 Gender 性别 Age 年龄 Annual Income (k$) 年收入,单位为千
-
Python实现k-means算法
本文实例为大家分享了Python实现k-means算法的具体代码,供大家参考,具体内容如下 这也是周志华<机器学习>的习题9.4. 数据集是西瓜数据集4.0,如下 编号,密度,含糖率 1,0.697,0.46 2,0.774,0.376 3,0.634,0.264 4,0.608,0.318 5,0.556,0.215 6,0.403,0.237 7,0.481,0.149 8,0.437,0.211 9,0.666,0.091 10,0.243,0.267 11,0.245,0.057 12
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args] 本文想要聊聊比较特殊的"-m"选项: 关于它的典型用法.原理解析与发展演变的过程. 首先,让我们用"--help"来看看它的解释: -m mod run library module as a script (ter
-
python中的函数递归和迭代原理解析
这篇文章主要介绍了python中的函数递归和迭代原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.递归 1.递归的介绍 什么是递归? 程序调用自身的编程技巧称为递归( recursion).递归做为一种算法在程序设计语言中广泛应用. 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大
-
python实现单链表中删除倒数第K个节点的方法
本文实例为大家分享了python实现单链表中删除倒数第K个节点的具体代码,供大家参考,具体内容如下 题目: 给定一个链表,删除其中倒数第k个节点. 代码: class LinkedListAlgorithms(object): def __init__(self): pass def rm_last_kth_node(self, k, linked_list): # 删除倒数第 K 个节点,针对单链表的 if linked_list.is_empty(): print 'The given li
-
Python实现从N个数中找到最大的K个数
提出问题: 如何在某集合里面找出最大或最小的K个元素. 解决思路: 找出最大或最下的K个元素,可以使用Python库中的heapq模块,该模块提供两个函数nlargest()求最大K个和nsmallest()求最小K个. 下面我们举例说明: import heapq nums=[12,-9,-3,32,9,56,23,0,11,34] print(heapq.nlargest(4,nums)) #-->最大的4个 print(heapq.nsmallest(4,nums)) #-->最小的4个
-
python中opencv K均值聚类的实现示例
目录 K均值聚类 K均值聚类的基本步骤 K均值聚类模块 简单例子 K均值聚类 预测的是一个离散值时,做的工作就是“分类”. 预测的是一个连续值时,做的工作就是“回归”. 机器学习模型还可以将训练集中的数据划分为若干个组,每个组被称为一个“簇(cluster)”.这种学习方式被称为“聚类(clusting)”,它的重要特点是在学习过程中不需要用标签对训练样本进行标注.也就是说,学习过程能够根据现有训练集自动完成分类(聚类). 根据训练数据是否有标签,可以将学习划分为监督学习和无监督学习. K近邻.
-
for循环在Python中的工作原理详细
例如: 作用于列表 >>> for elem in [1,2,3]: ... print(elem) ... 1 2 3 作用于字符串 >>> for c in "abc": ... print(c) ... a b c 作用于字典 >>> for k in {"age":10, "name":"wang"}: ... print(k) ... age name 可能有人不
-
python中k-means和k-means++原理及实现
目录 前言 k-means原理 k-means++原理 k-means及k-means++代码实现 k-means实现 k-means++实现 参考文档 前言 k-means算法是无监督的聚类算法,实现起来较为简单,k-means++可以理解为k-means的增强版,在初始化中心点的方式上比k-means更友好. k-means原理 k-means的实现步骤如下: 从样本中随机选取k个点作为聚类中心点 对于任意一个样本点,求其到k个聚类中心的距离,然后,将样本点归类到距离最小的聚类中心,直到归类
-
Python找出最小的K个数实例代码
题目描述 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 这个题目完成的思路有很多,很多排序算法都可以完成既定操作,关键是复杂度性的考虑.以下几种思路当是笔者抛砖引玉,如果读者有兴趣可以自己再使用其他方法一一尝试. 思路1:利用冒泡法 临近的数字两两进行比较,按照从小到大的顺序进行交换,如果前面的值比后面的大,则交换顺序.这样一趟过去后,最小的数字被交换到了第一位:然后是次小的交换到了第二位,...,依次直到第k个数,停
-
利用python numpy+matplotlib绘制股票k线图的方法
一.python numpy + matplotlib 画股票k线图 # -- coding: utf-8 -- import requests import numpy as np from matplotlib import pyplot as plt from matplotlib import animation fig = plt.figure(figsize=(8,6), dpi=72,facecolor="white") axes = plt.subplot(111) a
-
Python实现查找最小的k个数示例【两种解法】
本文实例讲述了Python实现查找最小的k个数.分享给大家供大家参考,具体如下: 题目描述 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 解法1 使用partition函数可以知道,使用==O(N)==的时间复杂度就可以找出第K大的数字,并且左边的数字比这个数小,右边的数字比这个数字大.因此可以取k为4,然后输出前k个数字,如果需要排序的话再对结果进行排序 # -*- coding:utf-8 -*- class So