详解Python中的四种队列
队列是一种只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
在Python文档中搜索队列(queue)会发现,Python标准库中包含了四种队列,分别是queue.Queue / asyncio.Queue / multiprocessing.Queue / collections.deque。
collections.deque
deque是双端队列(double-ended queue)的缩写,由于两端都能编辑,deque既可以用来实现栈(stack)也可以用来实现队列(queue)。
deque支持丰富的操作方法,主要方法如图:
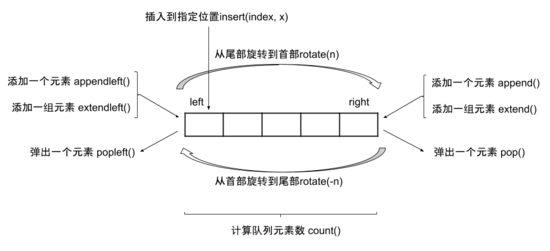
相比于list实现的队列,deque实现拥有更低的时间和空间复杂度。list实现在出队(pop)和插入(insert)时的空间复杂度大约为O(n),deque在出队(pop)和入队(append)时的时间复杂度是O(1)。
deque也支持in操作符,可以使用如下写法:
q = collections.deque([1, 2, 3, 4]) print(5 in q) # False print(1 in q) # True
deque还封装了顺逆时针的旋转的方法:rotate。
# 顺时针 q = collections.deque([1, 2, 3, 4]) q.rotate(1) print(q) # [4, 1, 2, 3] q.rotate(1) print(q) # [3, 4, 1, 2] # 逆时针 q = collections.deque([1, 2, 3, 4]) q.rotate(-1) print(q) # [2, 3, 4, 1] q.rotate(-1) print(q) # [3, 4, 1, 2]
线程安全方面,collections.deque中的append()、pop()等方法都是原子操作,所以是GIL保护下的线程安全方法。
static PyObject *
deque_append(dequeobject *deque, PyObject *item) {
Py_INCREF(item);
if (deque_append_internal(deque, item, deque->maxlen) < 0)
return NULL;
Py_RETURN_NONE;
}
通过dis方法可以看到,append是原子操作(一行字节码)。

综上,collections.deque是一个可以方便实现队列的数据结构,具有线程安全的特性,并且有很高的性能。
queue.Queue & asyncio.Queue
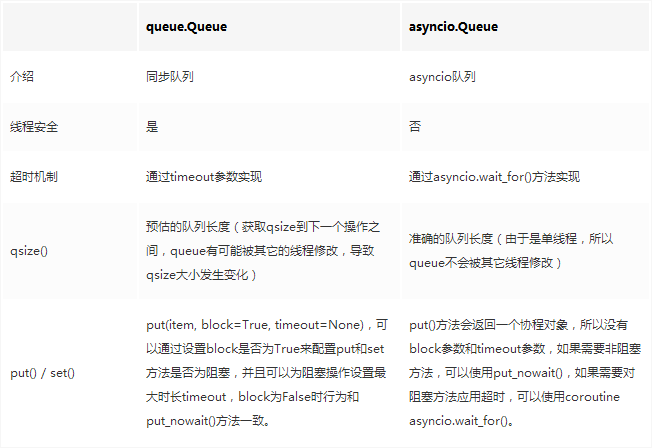
queue.Queue和asyncio.Queue都是支持多生产者、多消费者的队列,基于collections.deque,他们都提供了Queue(FIFO队列)、PriorityQueue(优先级队列)、LifoQueue(LIFO队列),接口方面也相同。
区别在于queue.Queue适用于多线程的场景,asyncio.Queue适用于协程场景下的通信,由于asyncio的加成,queue.Queue下的阻塞接口在asyncio.Queue中则是以返回协程对象的方式执行,具体差异如下表:
multiprocessing.Queue
multiprocessing提供了三种队列,分别是Queue、SimpleQueue、JoinableQueue。
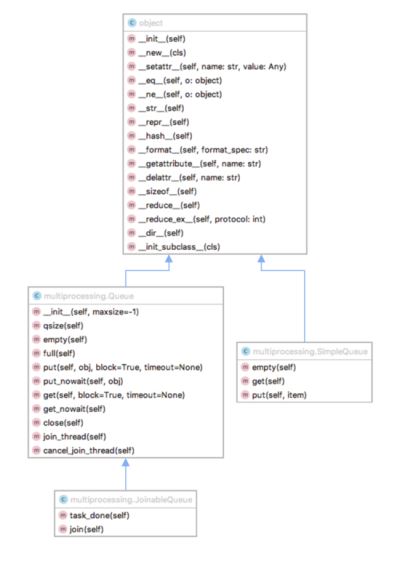
multiprocessing.Queue既是线程安全也是进程安全的,相当于queue.Queue的多进程克隆版。和threading.Queue很像,multiprocessing.Queue支持put和get操作,底层结构是multiprocessing.Pipe。
multiprocessing.Queue底层是基于Pipe构建的,但是数据传递时并不是直接写入Pipe,而是写入进程本地buffer,通过一个feeder线程写入底层Pipe,这样做是为了实现超时控制和非阻塞put/get,所以Queue提供了join_thread、cancel_join_thread、close函数来控制feeder的行为,close函数用来关闭feeder线程、join_thread用来join feeder线程,cancel_join_thread用来在控制在进程退出时,不自动join feeder线程,使用cancel_join_thread有可能导致部分数据没有被feeder写入Pipe而导致的数据丢失。
和threading.Queue不同的是,multiprocessing.Queue默认不支持join()和task_done操作,这两个支持需要使用mp.JoinableQueue对象。
SimpleQueue是一个简化的队列,去掉了Queue中的buffer,没有了使用Queue可能出现的问题,但是put和get方法都是阻塞的并且没有超时控制。
总结
通过对比可以发现,上述四种结构都实现了队列,但是用处却各有偏重,collections.deque在数据结构层面实现了队列,但是并没有应用场景方面的支持,可以看做是一个基础的数据结构。queue模块实现了面向多生产线程、多消费线程的队列,asyncio.queue模块则实现了面向多生产协程、多消费协程的队列,而multiprocessing.queue模块实现了面向多成产进程、多消费进程的队列。
以上所述是小编给大家介绍的Python中的四种队列,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Python中线程的MQ消息队列实现以及消息队列的优点解析
"消息队列"是在消息的传输过程中保存消息的容器.消息队列管理器在将消息从它的源中继到它的目标时充当中间人.队列的主要目的是提供路由并保证消息的传递:如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它.相信对任何架构或应用来说,消息队列都是一个至关重要的组件,下面是十个理由: Python的消息队列示例: 1.threading+Queue实现线程队列 #!/usr/bin/env python import Queue import threading import
-
Python队列、进程间通信、线程案例
进程互斥锁 多进程同时抢购余票 # 并发运行,效率高,但竞争写同一文件,数据写入错乱 # data.json文件内容为 {"ticket_num": 1} import json import time from multiprocessing import Process def search(user): with open('data.json', 'r', encoding='utf-8') as f: dic = json.load(f) print(f'用户{user}查看
-
python实现进程间通信简单实例
本文实例讲解了python实现两个程序之间通信的方法,具体方法如下: 该实例采用socket实现,与socket网络编程不一样的是socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)的第一个参数是socket.AF_UNIX 而不是 socket.AF_INET 例中两个python程序 s.py/c.py 要先运行s.py 基于fedora13/python2.6测试,成功实现! s.py代码如下: #!/usr/bin/env python im
-
详解Python的collections模块中的deque双端队列结构
deque 是 double-ended queue的缩写,类似于 list,不过提供了在两端插入和删除的操作. appendleft 在列表左侧插入 popleft 弹出列表左侧的值 extendleft 在左侧扩展 例如: queue = deque() # append values to wait for processing queue.appendleft("first") queue.appendleft("second") queue.appendl
-
python队列Queue的详解
Queue Queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构,即队列,用来在生产者和消费者线程之间的信息传递 基本FIFO队列 class Queue.Queue(maxsize=0) FIFO即First in First Out,先进先出.Queue提供了一个基本的FIFO容器,使用方法很简单,maxsize是个整数,指明了队列中能存放的数据个数的上限.一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉.如果maxsize小
-

Python基于list的append和pop方法实现堆栈与队列功能示例
本文实例讲述了Python基于list的append和pop方法实现堆栈与队列功能.分享给大家供大家参考,具体如下: #coding=utf8 ''''' 堆栈: 堆栈是一个后进先出(LIFO)的数据结构. 在栈上"push"元素是个常用术语,意思是把一个对象添加到堆栈中. 删除一个元素,可以把它"pop"出堆栈. 队列: 队列是一种先进先出(FIFO)的数据类型. 新的元素通过"入队"的方式添加进队列的末尾, "出对"就是从
-
利用Python学习RabbitMQ消息队列
RabbitMQ可以当做一个消息代理,它的核心原理非常简单:即接收和发送消息,可以把它想象成一个邮局:我们把信件放入邮箱,邮递员就会把信件投递到你的收件人处,RabbitMQ就是一个邮箱.邮局.投递员功能综合体,整个过程就是:邮箱接收信件,邮局转发信件,投递员投递信件到达收件人处. RabbitMQ和邮局的主要区别就是RabbitMQ接收.存储和发送的是二进制数据----消息. rabbitmq基本管理命令: 一步启动Erlang node和Rabbit应用:sudo rabbitmq-serv
-
python队列queue模块详解
队列queue 多应用在多线程应用中,多线程访问共享变量.对于多线程而言,访问共享变量时,队列queue是线程安全的.从queue队列的具体实现中,可以看出queue使用了1个线程互斥锁(pthread.Lock()),以及3个条件标量(pthread.condition()),来保证了线程安全. queue队列的互斥锁和条件变量,可以参考另一篇文章:python线程中同步锁 queue的用法如下: import Queque a=[1,2,3] device_que=Queque.queue(
-
详解Python中的四种队列
队列是一种只允许在一端进行插入操作,而在另一端进行删除操作的线性表. 在Python文档中搜索队列(queue)会发现,Python标准库中包含了四种队列,分别是queue.Queue / asyncio.Queue / multiprocessing.Queue / collections.deque. collections.deque deque是双端队列(double-ended queue)的缩写,由于两端都能编辑,deque既可以用来实现栈(stack)也可以用来实现队列(queue
-
详解python中的三种命令行模块(sys.argv,argparse,click)
Python作为一门脚本语言,经常作为脚本接受命令行传入参数,Python接受命令行参数大概有三种方式.因为在日常工作场景会经常使用到,这里对这几种方式进行总结. 命令行参数模块 这里命令行参数模块平时工作中用到最多就是这三种模块:sys.argv,argparse,click.sys.argv和argparse都是内置模块,click则是第三方模块. sys.argv模块(内置模块) 先看一个简单的示例: #!/usr/bin/python import sys def hello(name,
-
详解java中的四种代码块
在java中用{}括起来的称为代码块,代码块可分为以下四种: 一.简介 1.普通代码块: 类中方法的方法体 2.构造代码块: 构造块会在创建对象时被调用,每次创建时都会被调用,优先于类构造函数执行. 3.静态代码块: 用static{}包裹起来的代码片段,只会执行一次.静态代码块优先于构造块执行. 4.同步代码块: 使用synchronized(){}包裹起来的代码块,在多线程环境下,对共享数据的读写操作是需要互斥进行的,否则会导致数据的不一致性.同步代码块需要写在方法中. 二.静态代码块和构造
-
详解SpringMVC中的四种跳转方式、视图解析器问题
目录 一.视图解析器: 1.springmvc核心配置文件,添加视图解析器: 2.视图解析器的使用: 3.视图解析器类InternalResourceViewResolver源码解析: 二.SpringMVC四种跳转方式: 1.跳转方式案例: 一.视图解析器: 1.springmvc核心配置文件,添加视图解析器: <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www
-
详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系. 这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化. 其余还包含了pandas的数据分析模块以及matplotlib的画图模块. 若是没有安装这三个相关的非标准库使用pip的方式安装一下即可. pip install pandas -i https://pypi.tuna.tsinghua.e
-
详解Python中4种超参自动优化算法的实现
目录 一.网格搜索(Grid Search) 二.随机搜索(Randomized Search) 三.贝叶斯优化(Bayesian Optimization) 四.Hyperband 总结 大家好,要想模型效果好,每个算法工程师都应该了解的流行超参数调优技术. 今天我给大家总结超参自动优化方法:网格搜索.随机搜索.贝叶斯优化 和 Hyperband,并附有相关的样例代码供大家学习. 一.网格搜索(Grid Search) 网格搜索是暴力搜索,在给定超参搜索空间内,尝试所有超参组合,最后搜索出最优
-
详解Python中list[::-1]的几种用法
本文主要介绍了Python中list[::-1]的几种用法,分享给大家,具体如下: s = "abcde" list的[]中有三个参数,用冒号分割 list[param1:param2:param3] param1,相当于start_index,可以为空,默认是0 param2,相当于end_index,可以为空,默认是list.size param3,步长,默认为1.步长为-1时,返回倒序原序列 举例说明 param1 = -1,只有一个参数,作用是通过下标访问数据,-1为倒数第一个
-
详解Python中的GIL(全局解释器锁)详解及解决GIL的几种方案
先看一道GIL面试题: 描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因. GIL:又叫全局解释器锁,每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行,目的是解决多线程同时竞争程序中的全局变量而出现的线程安全问题.它并不是python语言的特性,仅仅是由于历史的原因在CPython解释器中难以移除,因为python语言运行环境大部分默认在CPython解释器中. 通过
-
详解python中读取和查看图片的6种方法
目录 1 OpenCV 2 imageio 3 PIL 4 scipy.misc 5 tensorflow 6 skimage 本文主要介绍了python中读取和查看图片的6种方法,分享给大家,具体如下: file_name1='test_imgs/spect/1.png' # 这是彩色图片 file_name2='test_imgs/mri/1.png' # 这是灰度图片 1 OpenCV 注:用cv2读取图片默认通道顺序是B.G.R,而不是通常的RGB顺序,所以读进去的彩色图直接显示会出现变
-
一文详解Python中实现单例模式的几种常见方式
目录 Python 中实现单例模式的几种常见方式 元类(Metaclass): 装饰器(Decorator): 模块(Module): new 方法: Python 中实现单例模式的几种常见方式 元类(Metaclass): class SingletonType(type): """ 单例元类.用于将普通类转换为单例类. """ _instances = {} # 存储单例实例的字典 def __call__(cls, *args, **kwa