python 项目目录结构设置
为项目设置目录结构是为了将功能类似的文件放置在同一目录内,增强项目的可读性和可维护性。如果一个python项目功能单一,代码量很小,那就没必要设置的这么复杂。
下图是一个示例项目的目录结构:
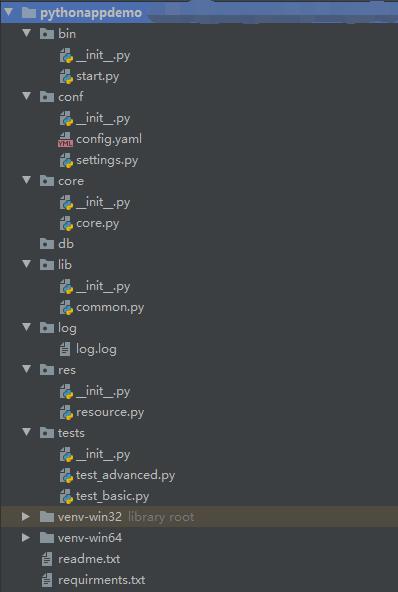
1,bin目录:是整个应用程序的执行文件目录,其中start.py文件是启动入口
2,conf目录:是整个应用程序的配置文件目录,config.yaml是其中一个配置文件
3,core目录:是整个应用程序的核心模块,core.py是核心业务逻辑脚本文件
4,db目录:是整个应用程序的数据库文件目录
5,lib目录:是整个应用程序的通用功能脚本和第三方应用文件存放目录
6,log目录:是整个应用程序的日志文件目录
7,res目录:是整个应用程序的图标、图片、ui等目录
8,tests目录:是整个应用程序的测试文件目录
9,venv-win32目录:是整个应用程序的32位虚拟环境目录,用于运行和打包32应用程序
10,venv-win64目录:是整个应用程序的64位虚拟环境目录,用于运行和打包64应用程序
11,readme.txt:项目说明文档
12,requirements.txt:用于存放整个应用依赖的外部Python包列表
相关推荐
-
python实现树形打印目录结构
本文实例为大家分享了python树形打印目录结构的具体代码,供大家参考,具体内容如下 前言 这两天整理数据文件的时候发现,一层层的点击文件夹查看很繁琐,于是想写一个工具来递归打印出文件目录的树形结构,网上找了一些资料几乎都是使用的os.walk, 调试了以后发现返回的貌似的是一个"生成器",只需要for循环即可,可是这样得到的好像是BFS的结构,并不是我想要的树形结构,最后终于发现了os.listdir这个函数,可是使用它来写一个深度优先搜索,只要递归调用就能解决我的问题. 代码 #!
-
python ftp 按目录结构上传下载的实现代码
具体代码如下所示: #!/usr/bin/python # coding=utf-8 from ftplib import FTP import time import os def __ftp_upload(ftp,local,remote,isDel=False): if os.path.isdir(local): for f in os.listdir(local): if os.path.isdir(local+f): try: ftp.cwd(remote+f) except: ftp
-
python 拷贝特定后缀名文件,并保留原始目录结构的实例
如下所示: #!/usr/bin/python # -*- coding: UTF-8 -*- import os import shutil def cp_tree_ext(exts,src,dest): """ Rebuild the director tree like src below dest and copy all files like XXX.exts to dest exts:exetens seperate by blank like "jpg
-
在Python中移动目录结构的方法
来源:http://stackoverflow.com/questions/3806562/ways-to-move-up-and-down-the-dir-structure-in-python #Moving up/down dir structure print os.listdir('.') # current level print os.listdir('..') # one level up print os.listdir('../..') # two levels up # m
-
Python复制目录结构脚本代码分享
引言 有个需要,需要把某个目录下的目录结构进行复制,不要文件,当目录结构很少的时候可以手工去建立,当目录结构复杂,目录层次很深,目录很多的时候,这个时候要是还是手动去建立的话,实在不是一种好的方法,弄不好会死人的.写一个python脚本来处理吧. 首先了解 写python脚本前,先了解几个东西 复制代码 代码如下: #!/usr/bin/python 这个东西写过脚本的人都知道,用来标明该脚本的执行器,类似的还有 复制代码 代码如下: #!/bin/bash 通过bash来执行 #!
-
Python提取Linux内核源代码的目录结构实现方法
今天用Python提取了Linux内核源代码的目录树结构,没有怎么写过脚本程序,我居然折腾了2个小时,先是如何枚举出给定目录下的所有文件和文件夹,os.walk可以实现列举,但是os.walk是只给出目录名和文件名,而没有绝对路径.使用os.path.listdir可以达到这个目的,然后是创建目录,由于当目录存在是会提示创建失败的错误,所以我先想删除所有目录,然后再创建,但是发现还是有问题,最好还是使用判断如果不存在才创建目录,存在时就不创建,贴下代码: # @This script can b
-
python 项目目录结构设置
为项目设置目录结构是为了将功能类似的文件放置在同一目录内,增强项目的可读性和可维护性.如果一个python项目功能单一,代码量很小,那就没必要设置的这么复杂. 下图是一个示例项目的目录结构: 1,bin目录:是整个应用程序的执行文件目录,其中start.py文件是启动入口 2,conf目录:是整个应用程序的配置文件目录,config.yaml是其中一个配置文件 3,core目录:是整个应用程序的核心模块,core.py是核心业务逻辑脚本文件 4,db目录:是整个应用程序的数据库文件目录 5,li
-
Xcode中iOS应用开发的一般项目目录结构和流程简介
项目所需的平台路径 1.开发平台路径: /Developer/Platforms 此路径下一般有三个目录,分别是mac电脑.模拟器.iphone真机 MacOSX.platform iPhoneSimulator.platform iPhoneOS.platform 每个目录下都有一个/Developer/usr/bin目录,放置开发中需要的程序 总的目录比如:/Developer/Platforms/*/Developer/usr/bin/ 注意:*代表上面上个目录中的一个,具体是哪个看目标平
-

详解如何构建Angular项目目录结构
在上一篇博客中我们已经通过Angular CLI命令行工具创建出来一个全新的Angular项目,要想写项目,首先我们要先搞清楚项目的目录结构是怎样的,每个文件又有什么意义,文件中的代码又起到什么作用. 首先看一下整体的目录结构: 可以看到,命令行工具自动生成了很多文件和目录,我们来说说这些目录是干什么的 首层目录: node_modules 第三方依赖包存放目录 e2e 端到端的测试目录 用来做自动测试的 src 应用源代码目录 .angular-cli.json Angular命令行工具的配置
-
Go项目的目录结构详解
项目目录结构如何组织,一般语言都是没有规定.但Go语言这方面做了规定,这样可以保持一致性. 1.一般的,一个Go项目在GOPATH下,会有如下三个目录: 复制代码 代码如下: |--bin |--pkg |--src 其中,bin存放编译后的可执行文件:pkg存放编译后的包文件:src存放项目源文件.一般,bin和pkg目录可以不创建,go命令会自动创建(如 go install),只需要创建src目录即可. 对于pkg目录,曾经有人问:我把Go中的包放入pkg下面,怎么不行啊?他直接把Go包的
-
浅谈Visual Studio 2019 Vue项目的目录结构
Visual Studio 2019 Vue项目 创建成功后可看到如下结构 Visual Studio 2019配置vue项目 具体文件结构如下图 模版使用 入口文件: public/index.html 和 src/main.js 总结 到此这篇关于Visual Studio 2019 Vue项目 目录结构的文章就介绍到这了,更多相关visual studio 2019 vue项目内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
Java项目的目录结构详解
一个java web项目 目录分为两个部分 ① Web应用的根目录下子目录WEB-INF,里面内容不能被客户端访问的,包括专用Web应用程序软件,包括Servlet类文件.部署描述符web.xml.外部库以及其他任何由此应用程序使用的专用文件. ② 所有位于WEB-INF之外的文件都被看作是公共的,客户端是可以访问到的.资源包括HTML页面.JSP页面和图像等. 一.Common包 Common用来封装一些常用的公共方法. 二.Dao包 Dao主要用来封装对数据库的新增,删除,查询,修改.叫做数
-
Android编程入门之HelloWorld项目目录结构分析
本文实例讲述了Android编程入门之HelloWorld项目目录结构.分享给大家供大家参考,具体如下: 我们介绍了如何搭建Android开发环境及简单地建立一个HelloWorld项目,本篇将通过HelloWorld项目来介绍Android项目的目录结构.本文的主要主题如下: 1.HelloWorld项目的目录结构 1.1.src文件夹 1.2.gen文件夹 1.3.Android 2.1文件夹 1.4.assets 1.5.res文件夹 1.6.AndroidManifest.xml 1.7
-
Python项目打包成二进制的方法
Python项目打包 python本身是一种脚本语音,发布的话,直接发布源代码就可以了,但是,可能有些公司并不想发布源代码,那么,就涉及到打包了,网上有很的打包教程,其实我也没有认真去研究,因为我只想简单点,所以,我打算直接编译成pyc二进制文件来发布,就可以了. 问题 编译成二进制文件(*.pyc)之后,文件名都变了,模块之间怎么引用? 网上的例子,大都是对单个文件编译的介绍,对整个目录编译的话,也都是输出到相应的文件夹下,需要单独抽取出来,发布. 解决问题 一般编译之后的文件命名为:比如我的
-
关于vscode 默认添加python项目的源目录路径到执行环境的问题
目录 背景 原因: 解决方案: 背景 在vscode刚刚装好的时候,对于开发人员来说可能需要写一些模块的测试,而这个模块可能又引用了其他模块, 如果是同级目录的话可能会出现ModuleNotFoundError: No module named 错误 图文件结构和代码所示,ddd.py文件和ccc.py文件 分别在test1和test2目录下,ccc.py文件需要调用ddd.py文件的函数. 原因: 在test2的ccc.py文件中执行print(sys.path) 查看路径 ['g:\\go_