java实现大文本文件拆分
本文实例为大家分享了java实现大文本文件拆分的具体代码,供大家参考,具体内容如下
生成大文件
public static void createBigFile() throws IOException {
File file = new File("/Users/yangpeng/Documents/temp/big_file.csv");
FileWriter fileWriter = new FileWriter(file);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
String str = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa1";
for (int i = 0; i < 1000000; i++) {
bufferedWriter.write(str);
bufferedWriter.newLine();
}
bufferedWriter.flush();
bufferedWriter.close();
}
文件拆分
此处没有给出根据文件大小计算需要拆分的文件数量,所以这里是给定一个拆分文件数量
思路
思路:给定带拆分数量,计算出每个文件的平均字节数,然后循环文件数进行每个文件的拆分。拆分第一个文件时,根据平均字节数往后取给定的大约行字节数的字节,然后循环字节判断是否为\r或者\n,如果字节为\r或者\n则代表到达行末尾,记录行尾字节位置。知道了开头字节位置与结束字节位置,就可以将此位置之间的数据生成子文件了。继续循环拆分下个文件,基于上个文件记录的结束字节位置继续计算当前文件的结束位置,直到到达拆分文件的数量或者大文件读取完毕。
举个栗子:
有一个3行记录的文件,假设每行记录行字节包含换行符的字节数为100,也就是说这个文件的总字节数为300。

我现在要将这个文件拆分成2个。按照上面的思路,首先我需要计算出文件的平均值300/2=150,这里计算出的平均值并不是拆分出来的子文件一定是150,因为这个数字位置的字节有可能在一行的中间,那么我要基于这个数字算出下个换行符出现的位置当做我这个子文件的结束位。

所以我给定一个行字节数100+150=250,这个150到250之间的字节我认为有换行符,所以我轮询这100字节,判断是否为换行符,结果我轮到到50的位置发现了换行。

那么我这个第一个文件的结束位置是150+50=200,然后将0到200之间的字节生成第一个文件。然后基于这个200的位置继续拆分下个文件,由于200+150已经大于了源文件的大小,所以直接将200到300的数据生成一个子文件。所以最终的结果是一二行为一个子文件,三行为第二个子文件。
代码
考虑到性能与内存占用的问题,此处实现采用NIO
public static void splitFile(String filePath, int fileCount) throws IOException {
FileInputStream fis = new FileInputStream(filePath);
FileChannel inputChannel = fis.getChannel();
final long fileSize = inputChannel.size();
long average = fileSize / fileCount;//平均值
long bufferSize = 200; //缓存块大小,自行调整
ByteBuffer byteBuffer = ByteBuffer.allocate(Integer.valueOf(bufferSize + "")); // 申请一个缓存区
long startPosition = 0; //子文件开始位置
long endPosition = average < bufferSize ? 0 : average - bufferSize;//子文件结束位置
for (int i = 0; i < fileCount; i++) {
if (i + 1 != fileCount) {
int read = inputChannel.read(byteBuffer, endPosition);// 读取数据
readW:
while (read != -1) {
byteBuffer.flip();//切换读模式
byte[] array = byteBuffer.array();
for (int j = 0; j < array.length; j++) {
byte b = array[j];
if (b == 10 || b == 13) { //判断\n\r
endPosition += j;
break readW;
}
}
endPosition += bufferSize;
byteBuffer.clear(); //重置缓存块指针
read = inputChannel.read(byteBuffer, endPosition);
}
}else{
endPosition = fileSize; //最后一个文件直接指向文件末尾
}
FileOutputStream fos = new FileOutputStream(filePath + (i + 1));
FileChannel outputChannel = fos.getChannel();
inputChannel.transferTo(startPosition, endPosition - startPosition, outputChannel);//通道传输文件数据
outputChannel.close();
fos.close();
startPosition = endPosition + 1;
endPosition += average;
}
inputChannel.close();
fis.close();
}
public static void main(String[] args) throws Exception {
Scanner scanner = new Scanner(System.in);
scanner.nextLine();
long startTime = System.currentTimeMillis();
splitFile("/Users/yangpeng/Documents/temp/big_file.csv",5);
long endTime = System.currentTimeMillis();
System.out.println("耗费时间: " + (endTime - startTime) + " ms");
scanner.nextLine();
}
使用NIO可以高效的实现文件拆分,我的文件为100W行大小为1.02G的文本文件,拆分成5个子文件总耗时1224ms
后如下是使用jvisualvm监控的程序内存:
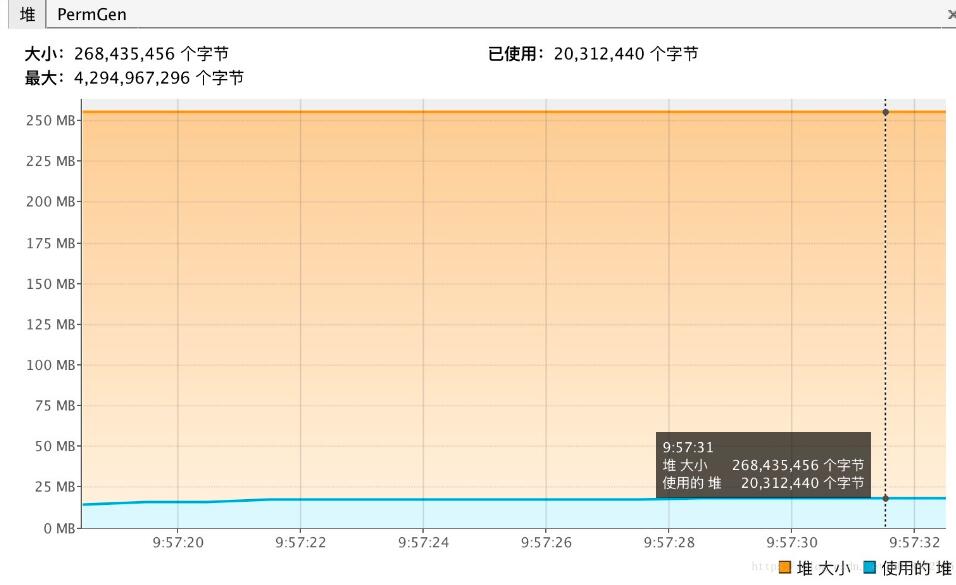
可以看到拆分期间内存浮动基本在1M左右。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

如何实用Java实现合并、拆分PDF文档
前言 处理PDF文档时,我们可以通过合并的方式,来任意组几个不同的PDF文件或者通过拆分将一个文件分解成多个子文件,这样的好处是对文档的存储.管理很方便.下面将通过Java程序代码介绍具体的PDF合并.拆分的方法. 工具:Free Spire.PDF for Java 2.0.0 (免费版) 注:2.0.0版本的比之前的1.1.0版本在功能上做了很大提升,支持所有收费版的功能,只是在文档页数上有一定限制,要求不超过10页,但是对于常规的不是很大的文件,这个类库就非常实用. jar文件导入: 方法
-
java IO流将一个文件拆分为多个子文件代码示例
文件分割与合并是一个常见需求,比如:上传大文件时,可以先分割成小块,传到服务器后,再进行合并.很多高大上的分布式文件系统(比如:google的GFS.taobao的TFS)里,也是按block为单位,对文件进行分割或合并. 看下基本思路: 如果有一个大文件,指定分割大小后(比如:按1M切割) step 1: 先根据原始文件大小.分割大小,算出最终分割的小文件数N step 2: 在磁盘上创建这N个小文件 step 3: 开多个线程(线程数=分割文件数),每个线程里,利用RandomAccessF
-
java实现大文本文件拆分
本文实例为大家分享了java实现大文本文件拆分的具体代码,供大家参考,具体内容如下 生成大文件 public static void createBigFile() throws IOException { File file = new File("/Users/yangpeng/Documents/temp/big_file.csv"); FileWriter fileWriter = new FileWriter(file); BufferedWriter bufferedWri
-
Python实现文本文件拆分写入到多个文本文件的方法
引言 将一个txt文本文件中的内容行拆分固定的行数,自动分批写入到多个文本文件. 比如:一个源txt文件有5100行数据,每1000行插入到一个txt文件,最后获得6个txt文件(5个文本文件有1000行数据,第6个文本文件有100行数据). 步骤 1.先建立一个目录用于存放分割后的txt文件(这里的目录名为:dataText) 2.修改拆分的数目(这里是每5000行数据存入一个txt文件) 3.运行python文件,查看生成的txt文件 代码 open_diff = open('data.tx
-
Java 十大排序算法之归并排序刨析
目录 归并排序原理 归并排序API设计 归并排序代码实现 归并排序的时间复杂度分析 归并排序原理 1.尽可能的一组数据拆分成两个元素相等的子组,并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是1为止. ⒉将相邻的两个子组进行合并成一个有序的大组. 3.不断的重复步骤2,直到最终只有一个组为止. 归并排序API设计 类名 Merge 构造方法 Merge():创建Merge对象 成员方法 1.public static void sort(Comparable[] a):对数组内的元素进行
-
Java实现大文件的分割与合并的方法详解
目录 一.题目描述-合并多个文本文件 1.题目 2.解题思路 3.代码详解 二.题目描述-对大文件进行分割处理 1.题目 2.解题思路 3.代码详解 三.题目描述-分割后又再次合并 1.题目 2.解题思路 3.代码详解 4.多学一个知识点 一.题目描述-合并多个文本文件 1.题目 题目:做一个合并多个文本文件的工具. 2.解题思路 创建一个类:TextFileConcatenation 使用TextFileConcatenation继承JFrame构建窗体 读取文本文件时,用的是Buffered
-
java 文件大数据Excel下载实例代码
java 文件大数据Excel下载实例代码 excel可以用xml表示.故可以以此来实现边写边下载文件 package com.tydic.qop.controller; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.I
-
完美解决java读取大文件内存溢出的问题
1. 传统方式:在内存中读取文件内容 读取文件行的标准方式是在内存中读取,Guava 和Apache Commons IO都提供了如下所示快速读取文件行的方法: Files.readLines(new File(path), Charsets.UTF_8); FileUtils.readLines(new File(path)); 实际上是使用BufferedReader或者其子类LineNumberReader来读取的. 传统方式的问题: 是文件的所有行都被存放在内存中,当文件足够大时很快就会
-
java中关于文本文件的读写方法实例总结
本文实例总结了java中关于文本文件的读写方法.分享给大家供大家参考,具体如下: 写文本数据 方法 一: import java.io.*; public class A { public static void main(String args[]) { FileOutputStream out; PrintStream ps; try { out = new FileOutputStream("a.txt"); ps = new PrintStream(out); ps.print
-
python实现大文本文件分割
本文实例为大家分享了python实现大文本文件分割的具体代码,供大家参考,具体内容如下 开发环境 Python 2 实现效果 通过文件拖拽或文件路径输入,实现自定义大文本文件分割. 代码实现 #coding:gbk import os,sys,shutil is_file_exits=False while not is_file_exits: files_list=[] if(len(sys.argv)==1): print('请输入要切割的文件完整路径:') files_path=raw_i
-
Java实现大文件的切割与合并操作示例
本文实例讲述了Java实现大文件的切割与合并操作.分享给大家供大家参考,具体如下: 这里实现对大文件的切割与合并. 按指定个数切(如把一个文件切成10份)或按指定大小切(如每份最大不超过10M),这两种方式都可以. 在这里我只是给大家写下我自己的一点简单的代码: package io2; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io
-
用Python实现大文本文件切割的方法
在实际工作中,有些场景下,因为产品既有功能限制,不支持特大文件的直接处理,需要把大文件进行切割处理. 当然可以通过UltraEdit编辑工具,或者从网上下载一些文件切割器之类的.但这些要么手工操作太麻烦,要么不能满足自定义需求. 而且,对程序员来说,DIY一个轮子还是有必要的. Python作为快速开发工具,其代码表达力强,开发效率高,因此用Python快速写一个,还是可行的. 需求描述: 输入:给定一个带列头的csv文件,或者txt文件,或者其他文本文件. 输出:指定单文件内部行数的一系列可区