使用JavaIO流和网络制作一个简单的图片爬虫
目录
- Java IO流和网络的简单应用
- Java IO 流和 URL 类
- Java IO流
- URL 类
- Java 爬虫
- Client
- DataProcessUtil
- DownLoadUtil
- Window
- 运行结果
- 基本原理
- 总结
Java IO流和网络的简单应用
最近看到了 URL 类的用法,简单的做了一个Java 版的爬虫。发现还挺有趣的,就拿出来分享一下。通过关键字爬取百度图片,这个和我们使用搜索引擎搜索百度图片是一样的,只是通过爬虫可以学习技术的使用。(这个程序只是用来学习使用的,没有其它用途!)
Java IO 流和 URL 类
Java IO流
Java 的 IO 流是实现输入/输出的基础,它可以方便的实现数据的输入/输出操作,在 Java 中把不同的输入/输出源(键盘、文件、网络连接等)抽象表述为”流“(Stream),通过流的方法运行Java 程序使用相同的方式来访问不同的输入/输出源。
因为 IO流 已经对各种输入输出源做了一个抽象处理,所以我们可以使用相对一致的代码处理各种的源,只需要把它们作为输入输出流来进行处理就行了,这就是面向抽象的好处。
URL 类
URI 和 URL
先来了解一下什么是 URL 吧,说 URL 之前先简单了解URI。
**URI,统一资源标识符(Uniform Resource Identifier)**是采用一种特定语法标识一个资源的字符串。所标识的资源可能是服务器上的一个文件或者其它任何内容。URI 的语法是由一个模式和一个模式特定部分组成,模式和模式特定部分用一个冒号分隔,如下所示:
模式:模式特定部分
URI 中的模式特定部分没有特定的语法,很多都采用一种层次结构形式,如:
//authority/path?query
**URL,统一资源定位符(Uniform Resource Location)**是URI的一个子集,它除了标识一个资源外 ,还会为资源提供一个特定的网络位置,客户端可以用它来获取这个资源的一个表示。
注意:URL和URI并不是完全相同的,通用的URI可以告诉你一个资源是什么,但是无法告诉你它在哪里,以及如何得到这个资源。
在Java中,这二者都有相应的实现,java.net.URI 类(只标识资源)与 java.net.URL 类(既能标识资源,又能获取资源)
URL 中的网络位置通常包括用来访问服务器的协议(FTP、HTTP等)、服务器的主机名或IP地址,以及文件在该服务器上的路径。典型的 URL 类似于 https://www.baidu.com/。它表示百度服务器上的一个 html 文件(百度搜索的首页),它可以通过 HTTP 协议访问虽然没有直接在 URL 后面加上 html 文件的名字。如果使用 tomcat 的话,通常是 http://127.0.0.1:8080/foods/index.html 这种形式,其实二者是相同的。
好了,简单的了解就到此为止了,感兴趣的话,可以查阅相关书籍了解更详细的知识,上面只是提到一些基础的概念。
URL类
java.net.URL类是对统一资源定位符的抽象表示。它不依赖于继承来配置不同类型的URL的实例,而使用了策略设计模式。协议处理器就是策略,URL 类构成上下文,通过它来选择不同的策略。(值得一提的是:
java 的 IO流也是使用了一种设计模式:装饰器模式。
例如如下代码:
DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(new File())))。
URL 类包含很多的构造方法,我也只是第一次使用,就使用了最简单的一种形式:(刚开始学习,根本不需要了解这么多,先用着再说,慢慢掌握知识。)
public URL(String url) throws MalformedURLException
Java 爬虫
Talk is cheap, show me the code!
前面主要是一下简单的基础知识,如果已经了解可以直接看下面这部分。
项目的基本结构:
Client
package dragon;
import java.io.File;
import java.io.IOException;
public class Client {
public static final String downloadFilePath = "D:\\DragonDataFile\\cat";
public static void main(String[] args) throws IOException {
//初始化创建文件下载目录
File dir = new File(Client.downloadFilePath);
if (!dir.exists()) {
dir.mkdirs();
}
//启动下载窗口
new Window("龙");
}
}
DataProcessUtil
package dragon;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.net.URL;
import java.net.URLConnection;
import java.util.LinkedList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class DataProcessUtil {
//根据链接获取 html 文件数据。
public static String getData(String link) throws IOException {
URL url = new URL(link);
URLConnection connection = url.openConnection();
StringBuilder strBuilder = new StringBuilder();
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream())){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
strBuilder.append(new String(b, 0, hasRead));
}
}
return strBuilder.toString();
}
public static List<String> getLinkList(String str){
String regx = "\"objURL\":\"(.*?)\",";
Pattern p = Pattern.compile(regx);
Matcher m = p.matcher(str);
List<String> strs = new LinkedList<>();
while (m.find()) {
strs.add(m.group(0));
}
//使用 Stream API 进行处理并返回。
return strs.stream()
.map(s->s.substring(10, s.length()-2))
.collect(Collectors.toList());
}
}
说明:
获取html页面的信息,并进行处理,使用正则表达式从html中提取图片的链接。
(正则表达式是参考其它人的实现,这个涉及到对html内容的分析)
String regx = "\"objURL\":\"(.*?)\",";
//使用 Stream API 进行处理并返回。 return strs.stream() .map(s->s.substring(10, s.length()-2)) .collect(Collectors.toList());
使用Java 8新增加的 Stream 对数据进行遍历,提取所有的图片的 URL 组成一个列表集合返回。
DownLoadUtil
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.util.Date;
import java.util.List;
import java.util.Random;
public class DownLoadUtil {
public static void downLoad(List<String> strs) {
strs.stream().forEach(u->{
try {
URL url = new URL(u);
String contentType = url.openConnection().getContentType();
if (contentType != null && contentType.contains("image/")) {
//获取图片的类型:content type
String filetype = null;
if (contentType.contains("jpeg")) {
filetype = ".jpeg";
} else if (contentType.contains("jpg")) {
filetype = ".jpg";
} else{
filetype = ".png";
} //gif 格式图片,似乎无法正常显示
//使用当前日期的毫秒数+随机数+contentType 作为文件名
Random rand = new Random(System.currentTimeMillis());
String filename = new Date().getTime()+rand.nextInt(10000)+filetype;
Runnable r = ()->{
int flag = 0;
File imageFile = new File(Client.downloadFilePath, filename);
try(
BufferedInputStream bis = new BufferedInputStream(url.openConnection().getInputStream());
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(imageFile))){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
} catch (IOException e) {
System.out.println("下载失败!");
//对于下载失败的图片进行删除,不然会出现错误!图片只能正常现实一部分
if (imageFile.exists()) {
boolean b = imageFile.delete();
System.out.println("下载失败,删除图片"+b);
}
flag = 1;
e.printStackTrace();
}
if (flag == 0)
System.out.println("下载完成:"+filename);
};
Thread t = new Thread(r);
t.start(); //启动下载线程。
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("链接错误!");
}
});
}
}
**注意:这里遇到一个问题,就是图片的下载过程受到网络因素的影响,有时候会下载失败,但是如果图片已经开始下载,仍然提示下载失败,那么这张图片可以能会出现异常,比如出现一下奇怪的颜色,我对下载失败的图片,进行了处理,发现,似乎没有效果。所以我代码中处理下载失败图片的部分,可能不起效果。或许,可以通过获取资源文件的大小和下载后文件的大小进行比对,如果不相等就删除,感兴趣的可以试试。 **
单纯的判断大小无法解决图片变形的问题,还有一种情况需要考虑!在最下面,会有详细说明解决方法。
Window
package dragon;
import java.awt.FlowLayout;
import java.io.IOException;
import java.util.List;
import javax.swing.Box;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JTextField;
public class Window extends JFrame{
/**
* 自动生成的序列化版本号
*/
private static final long serialVersionUID = 7809323808831342296L;
private JLabel label_keyWord, label_Page;
private JTextField textField, textPage;
private JButton download;
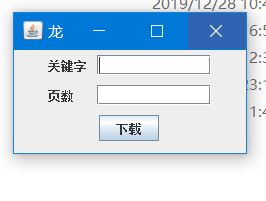
public Window(String name) {
super(name);
this.init();
//设置布局
this.setLayout(new FlowLayout());
this.setBounds(400, 400, 250, 150);
this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
this.setVisible(true);
}
private void init() {
label_keyWord = new JLabel("关键字");
label_Page = new JLabel("页数");
textField = new JTextField(10);
textPage = new JTextField(10);
download = new JButton("下载");
download.addActionListener(e->{
String keyWord = textField.getText().trim();
String page = textPage.getText().trim();
int download_page = 0;
if (keyWord.length() == 0 || page.length() == 0) {
JOptionPane.showMessageDialog(null, "关键字或页数不能为空!", "警告", JOptionPane.WARNING_MESSAGE);
return ;
}
try {
download_page = Integer.parseInt(page); //匹配单个数字,如果数字很多使用正则表达式
} catch (NumberFormatException exp) {
JOptionPane.showMessageDialog(null, "页数必须为数字!", "警告", JOptionPane.WARNING_MESSAGE);
return ;
}
String link = null;
for (int i = 1; i <= download_page; i++) {
//分页下载图片!
link = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+keyWord+"&pn="+i*20;
this.download(link);
}
});
Box boxH1 = Box.createHorizontalBox();
boxH1.add(label_keyWord);
boxH1.add(Box.createHorizontalStrut(10));
boxH1.add(textField);
Box boxH2 = Box.createHorizontalBox();
boxH2.add(label_Page);
boxH2.add(Box.createHorizontalStrut(23));
boxH2.add(textPage);
Box boxH3 = Box.createHorizontalBox();
boxH3.add(download);
Box boxV = Box.createVerticalBox();
boxV.add(boxH1);
boxV.add(Box.createVerticalStrut(10));
boxV.add(boxH2);
boxV.add(Box.createVerticalStrut(10));
boxV.add(boxH3);
this.add(boxV);
}
private void download(String link) {
try {
String str = DataProcessUtil.getData(link);
List<String> links = DataProcessUtil.getLinkList(str);
//尝试下载!使用线程进行下载,防止阻塞!
Thread t = new Thread(()->{
DownLoadUtil.downLoad(links);
});
t.start();
} catch (IOException e1) {
e1.printStackTrace();
JOptionPane.showMessageDialog(null, "啥都没有!", "警告", JOptionPane.WARNING_MESSAGE);
}
}
}
说明:
当图片没有下载完成时,不要再次点击下载按钮,否则会报错。因为线程不能被再次启动。
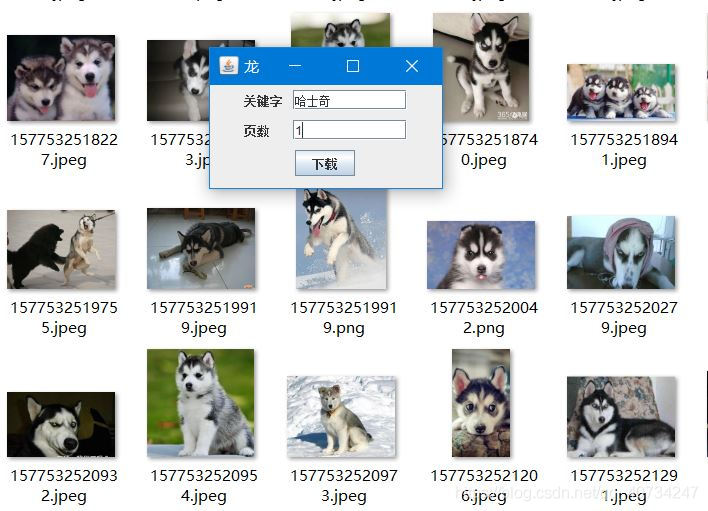
运行结果
基本原理
我来简单画一个示意图,大家凑合着看:
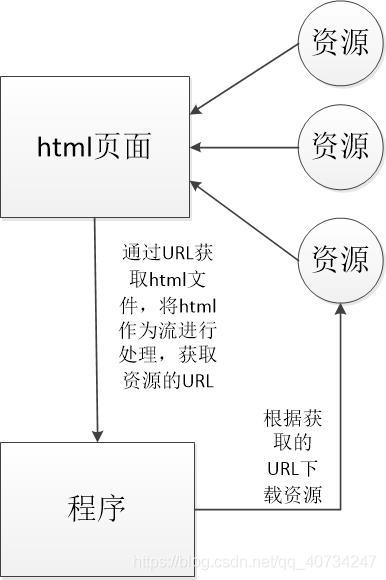
说明:首先通过百度图片的URL来获取百度图片那个页面的信息(html的内容),我们平时在浏览器使用,看到的都是浏览器处理好的页面,如果使用爬虫爬取的就是原始的html页面,在浏览器按 F12 也可以看到。因为图片的链接都在html 中,所以我们需要取出这些图片,这里就用到了**正则表达式(Regular Expression)**的知识了,通过正则表达式可以取出需要的信息(资源的URL或者说资源的地址)。其实获取html的过程和获取图片的过程,都是一样的。
这里说一下,这个步骤:
//根据链接获取 html 文件数据。
public static String getData(String link) throws IOException {
URL url = new URL(link);
URLConnection connection = url.openConnection();
StringBuilder strBuilder = new StringBuilder();
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream())){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
strBuilder.append(new String(b, 0, hasRead));
}
}
return strBuilder.toString();
}
通过参数 link,创建一个 URL 对象,然后通过使用URLConnection connection = url.openConnection();获取 URLConnection 对象,在通过 URLConnection 对象的getInputStream() 方法,获取输入流即可。这样就完成了对资源的获取。我这里强调资源,因为下载图片其实和这个过程是一样的。
总结
这个小软件虽然功能很简单,但是也用到了很多知识点,比较适合初学者进行学习(Java IO流、网络、Stream、线程的知识),知识虽然用到的都不难(一些基础知识),但是融合起来使用,还是很有意思的。
附
对于图片的奇怪颜色问题,可以确定是图片的大小和原来图片的大小不一致导致的,至于为什么是这样的,估计需要具备一定的图形学知识,才能解答,这个超出了这个东西的范围了。所以为了判断哪些图片出错,我就使用大小判断的方法,对最后生成的文件大小和网络图片文件大小进行比对,删除了一些无法下载的图片,但是有一些图片居然无法删除,我查阅了资料,大多说它被另一个进程占用,但是我这个图片应该是没有的。后来,经过检查发现是多线程惹得祸,因为是多线程,并且代码执行速度太快了(对的,和这个也有关系),因为我的文件命名是当前时间的毫秒数+一个种子为当前时间的随机数,在多线程的情况下,重复的概率居然还挺高的。
所以,原因就出现了,当发现图片大小不对,试图删除图片时,图片被另一个线程占用,无法删除。(关于名字重复的问题,就是两个线程在同一个毫秒启动了,所以随机数也是相等的(种子相等),因此有些图片就会和其它图片写入同一个图片文件,导致出现异常情况。)
总结一下:
图片异常的情况有两种:
1.网络原因,导致图片无法完整下载,这是无法解决的,只能删除。
2.图片名字重复,导致多张图片数据被写入同一张图片当中,这是程序错误,可以避免的。
解决方法:
对于第一种情况,只需要把错误的图片删除即可;
对于第二种情况,要避免图片名字重复,所以我重新设计了图片的命名方法,
采用:当前时间的毫秒数+UUID随机数(查阅资料,这个挺好用的)作为文件的命名方式。注:UUID 也有一个缺点,就是名字太长了。
修改后的源文件:
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.UUID;
public class DownLoadUtil {
public static void downLoad(List<String> strs) {
strs.stream().forEach(u->{
try {
URL url = new URL(u);
URLConnection urlConnection = url.openConnection();
String contentType = urlConnection.getContentType();
//获取资源文件的大小
long size = urlConnection.getContentLengthLong();
if (contentType != null && contentType.contains("image/")) {
//获取图片的类型:content type
String filetype = null;
if (contentType.contains("jpeg")) {
filetype = ".jpeg";
} else if (contentType.contains("jpg")) {
filetype = ".jpg";
} else{
filetype = ".png";
} //gif 格式图片,似乎无法正常显示
//使用当前时间戳+随机数+contentType 作为文件名
String filename = System.currentTimeMillis()+UUID.randomUUID().toString()+filetype;
//使用线程进行下载
Runnable r = ()->{
File imageFile = new File(Client.downloadFilePath, filename);
try(
BufferedInputStream bis = new BufferedInputStream(urlConnection.getInputStream());
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(imageFile))){
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
} catch (IOException e) {
System.out.println("下载失败!");
e.printStackTrace();
}
//对下载失败的图片进行删除。
if (imageFile.length() != size) {
boolean result = imageFile.delete();
System.out.println(imageFile.length()+" "+size+" "+filename+" 删除结果:"+result);
//大小不符合,说明图片下载有问题,删除图片。
} else {
System.out.println("下载完成:"+filename);
}
};
Thread t = new Thread(r);
t.start(); //启动下载线程。
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("链接错误!");
}
});
}
}
运行截图
这样网络原因错误的图片直接删除,代码原因的错误,已经改正了。

注:还有一些图片无法显示,这个可能是官方不允许我们进行爬取,有的图片,爬取的就是不允许爬取那种图片,还有一些图片,不支持格式(这个原因,我 也不太明白,希望明白的人,可以指出来为什么)。
到此这篇关于使用JavaIO流和网络制作一个简单的图片爬虫的文章就介绍到这了,更多相关JavaIO流制作图片爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java细数IO流底层原理到方法使用
目录 一.什么是IO流 二.常用的文件操作 三.获取文件的相关信息 四.目录的操作和文件删除 五.IO流体系图-常用的类 六.FileInputStream常用方法 七.FileOutputStream常用方法 八.FileReader常用方法 九.FileWriter常用方法 一.什么是IO流 输入流和输出流. 输入流:数据从数据源(文件)到程序(内存)的路径 输出流:数据从程序(内存)到数据源(文件)的路径 二.常用的文件操作 学习目标:创建文件对象相关构造器和方法 new File(Str
-
Java利用IO流实现简易的记事本功能
要求:编写一个模拟日记本的程序,通过在控制台输入指令,实现在本地新建文件,打开日记本和修改日记本等功能. 指令1代表“新建日记本”,可以从控制台获取用户输入的日记内容 指令2代表“打开日记本”,读取指定路径的TXT文件的内容并输出到控制台 指令3代表“修改日记本”,修改日记本中原有的内容 指令4代表保存 指令5代表退出 import java.io.*; import java.util.Scanner; public class IO_日记本 { /** * 模拟日记本程序 */ privat
-
Java IO流之字节输入流的使用详解
目录 一.InputStream字节输入流 二.FileInputStream文件输入类 三.文件复制 一.InputStream字节输入流 ①.是一个抽象类,不能够创建对象,需要被继承才能够使用 ②.在java.io包下,使用时需要导入 ③.公共的方法: 方法一: int read() 方法二: int read(byte[] b) 方法三: void close() 更多方法请查看官方API 二.FileInputStream文件输入类 ①.该类继承了InputStream,可以使用Inpu
-
Java的IO流实现文件和文件夹的复制
本文实例为大家分享了Java的IO流实现文件和文件夹复制的具体代码,供大家参考,具体内容如下 1.使用文件流对单个文件进行复制 将某个文件复制到指定的路径下: //复制文件 public static void copy(File f1, String path) throws IOException { System.out.println("***copy***" + f1.getName()); FileInputStream in = new F
-
Java基础学习之IO流应用案例详解
目录 一.点名器 二.集合到文件 三.文件到集合 一.点名器 需求: 我有一个文件里面存储了班级同学的姓名,每一个姓名占一行,要求通过程序实现随机点名器 实现步骤: 创建字符缓冲输入流对象 创建ArrayList集合对象 调用字符缓冲流对象的方法读数据 把读取到的字符串数据存储到集合中 释放资源 使用Randam产生一个随机数,随机数的范围在:[0,集合的长度] 把第6步产生的随机数作为索引到ArrayList集合中获取值 把第7步得到的数据输出在控制台 代码实现: public class C
-
Java详细讲解IO流的Writer与Reader操作
目录 接口连接 一.Writer方法 二.Reader方法 接口连接 public static void main(String[] args) throws Exception io流的所有方法都需要链接他们的接口父类,Exception. 一.Writer方法 方法引入: Writer Writer = new FileWriter("D:\\java制作\\高级特性\\src\\com\\ytzl\\第二章\\demo4\\io流\\two\\FileWriter方法.txt"
-
用React Native制作一个简单的游戏引擎
简介 今天我们将学习如何使用React Native制作一个游戏.因为我们使用的是React Native,这个游戏将是跨平台的,这意味着你可以在Android.iOS和网络上玩同一个游戏.然而,今天我们将只关注移动设备.所以我们开始吧. 开始吧 要制作任何游戏,我们需要一个循环,在我们玩的时候更新我们的游戏.这个循环被优化以顺利运行游戏,为此我们将使用 React Native游戏引擎 . 首先让我们用以下命令创建一个新的React Native应用. npx react-native ini
-
利用Python制作一个简单的天气播报系统
目录 前言 工具 天气数据来源 代码实现 总结 前言 大家好,我是辣条 相信大家都能感觉到最近天气的多变,好几次出门半路天气转变.辣条也深受其扰,直接给我整感冒,就差被隔离起来了,既然天气我没法做主,那不如用python整个天气爬虫来获取天气情况.这样也好可以进行一个提前预防 工具 python3.7 pycharm pyttsx3:语音播报库 天气数据来源 找寻一个天气网站 比如说我们要查询某地的天气,在输入地名后就能看到结果. 我们可以看到网站的url会有变化: 每个城市的天气信息url就是
-
探索Emberjs制作一个简单的Todo应用
目标 使用Emberjs制作一个简单的Todo应用,实现这样一个效果:通过在文本框输入文本,创建一条代办事项,代办事项可以选择优先级,完成的事项可以删除. 准备 完成这个应用,需要做点准备: 1.创建一个html页面,暂时不管样式: 2.脚本:emberjs,handlebars.jQuery.这三个脚本可以从网上获得,我们将把他们加入到head标签里去. 制作 创建页面,加入脚本,就可以开始制作应用.html代码如下: 复制代码 代码如下: <!doctype html> <html&
-
PHP开发制作一个简单的活动日程表Calendar
材料取之深入PHP与JQuery开发,这本书实际上就是讲述一个活动日程表. 此文章适合从其它语言(如java,C++,python等)转到php,没有系统学习php,或者是php初学者,已经对程序有较深理解的朋友 以上为文件目录结构,public为程序根目录,目的是为了安全方面的考虑,把核心程序放在外界访问不到的地方. 本地的演示地址为:http://localhost/index.php 首先是数据库的脚本: /* Navicat MySQL Data Transfer Source Serv
-
python制作一个简单的gui 数据库查询界面
一.准备工作: 1.安装mysql3.7,创建一个test数据库,创建student表,创建列:(列名看代码),创建几条数据 (以上工作直接用navicat for mysql工具完成) 二.代码: import sys import tkinter as tk import mysql.connector as sql #--------------------查询函数--------------------------- def sql_connect(): listbox_show.del
-
基于JS制作一个简单的网页版地图
目录 前言 一.申请地图的AK密钥 二.主要代码分析 三.全部代码 四.结果展示 前言 以前做了一个安卓版的地图应用,现在突然想做一个简单的网页版地图.这个简单的网页版地图能根据城市名进行位置查询(有个城市列表的小控件,支持城市列表选择),还能根据经纬度进行位置查询.当你进行城市搜索时,或者经纬度查询城市时,该小控件也能自由地切换到目标城市. 一.申请地图的AK密钥 1.首先找到一个地图开放平台,这里以百度地图开放平台为例,步骤如下:进入百度地图开放平台,拉到最底下,进行登录注册,然后进入应用管
-
如何利用PyQt5制作一个简单的登录界面
目录 环境配置 额外工具配置 生成UI界面 总结 环境配置 新建python虚拟环境并激活 conda create -n pyqt python=3.8 conda activate py36 安装pyqt5 pip install pyqt5 安装pyqt5-tools pip install pyqt5-tools 在PyCharm中新建一个qtdemo工程,并使用这个新建的python虚拟环境作为工程环境 额外工具配置 依次点击File---Settings---Tools---Exte
-
分享一个简单的java爬虫框架
反复给网站编写不同的爬虫逻辑太麻烦了,自己实现了一个小框架 可以自定义的部分有: 请求方式(默认为Getuser-agent为谷歌浏览器的设置),可以通过实现RequestSet接口来自定义请求方式 储存方式(默认储存在f盘的html文件夹下),可以通过SaveUtil接口来自定义保存方式 需要保存的资源(默认为整个html页面) 筛选方式(默认所有url都符合要求),通过实现ResourseChooser接口来自定义需要保存的url和资源页面 实现的部分有: html页面的下载方式,通过Htt
-
一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据.专业的解释:百度百科 分析爬虫需求 确定目标 爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称.豆瓣评分.导演.编剧.主演.类型.制片国家/地区.语言.上映日期.片长.IMDb链接等信息. 分析目标 1.借助工具分析目标网页 首先,我们打开豆瓣电影·热门电影,会发现页面总共20部
-
ASP.Net生成一个简单的图片
在本节中我们通过生成一个简单的图片作为ASP.NET图形处理的入门训练.首先使用VisualStudio.NET 2003 新建一个Web 应用程序,命名为GDITec,新建一个Web 窗体命名为GDI_Sample1.aspx,我们为该窗体编写逻辑代码: '-----code begin----- Imports System.Drawing Imports System.Drawing.Bitmap Imports System.Drawing.Graphics Public Class W