Python采集二手车数据的超详细讲解
目录
- 数据采集
- 发送请求
- 明确需求:
- 解析数据
- 保存数据
- 总结
数据采集
XPath,XML路径语言的简称。XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath主要用于解析XML文档,可以用来获取XML文档中某个元素的位置、属性值等信息。XPath可以用于XML文档解析、XML数据抽取、XML路径匹配等方面。
发送请求
首先,我们要进行数据来源分析,知道我们的需求是什么?
明确需求:
- 明确采集网站是什么?
- 明确采集数据是什么?
车辆基本信息
然后,我们分析车辆基本信息数据, 具体是请求那个网址可以得到我们想要的数据。
通过开发者工具, 进行抓包分析:
打开开发者工具: F12 / 鼠标右键点击检查选择network
刷新网页: 让本网页数据内容重新加载一遍 <方便分析数据出处>
搜索数据来源: 复制你想要的内容, 进行搜索即可
import requests
url = 'https://www.che168.com/china/a0_0msdgscncgpi1ltocsp1exx0/'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
res = requests.get(url,headers=headers)
我们和之前一样,获取数据,我们会发现,车辆的基本信息就在网页源代码中,我们今天就用xpath的方法来解析数据。
解析数据
接下来,我们用xpath解析数据。我们用开发者工具定位到标签位置。
我们通过网页源代码,我们可以获取到每一个网页的url。
selector=parsel.Selector(res.text)
detail_url_list = selector.xpath('//ul[@class="viewlist_ul"]/li/a[@class="carinfo"]/@href').getall()
我们可以看到,得到下面数据。
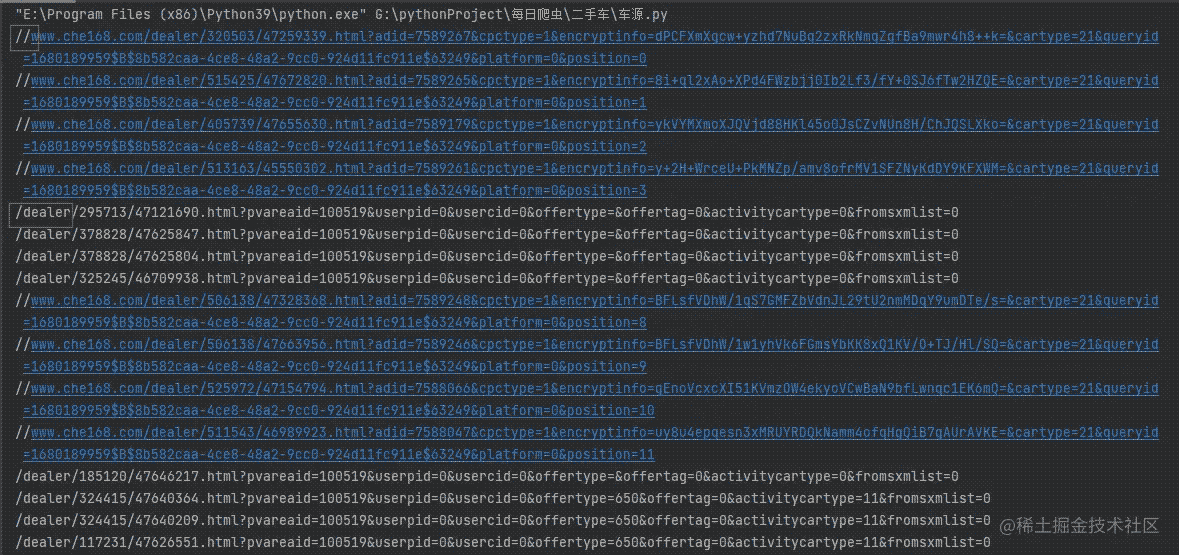
我们会发现,我们得到了两种网页,所以,在这里我们拼接网页就需要注意,这里,我不多说,直接看我是怎么写的。
if detail_url.split('/') == '':
detail_url = 'https:'+detail_url
else:
detail_url = 'https://www.che168.com'+detail_url
这样,我们就得到了每一个车辆信息的数据网页,看看运行之后的效果吧。
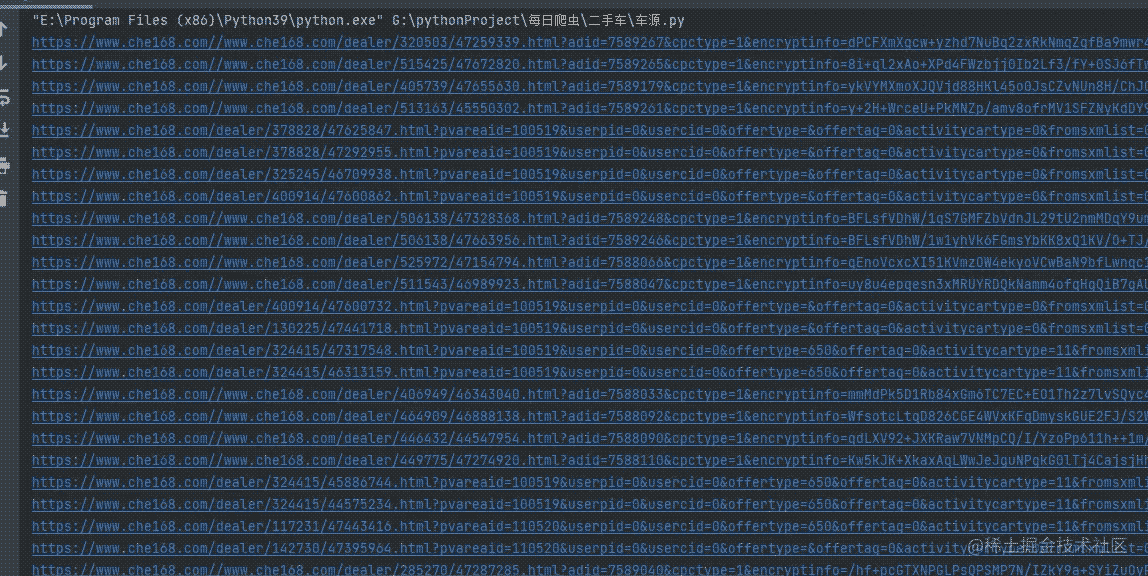
接下来,我们就依次访问某个链接,获取我们想要的数据。
responses = requests.get(detail_url,headers=headers)
detail_selector = parsel.Selector(responses.text)
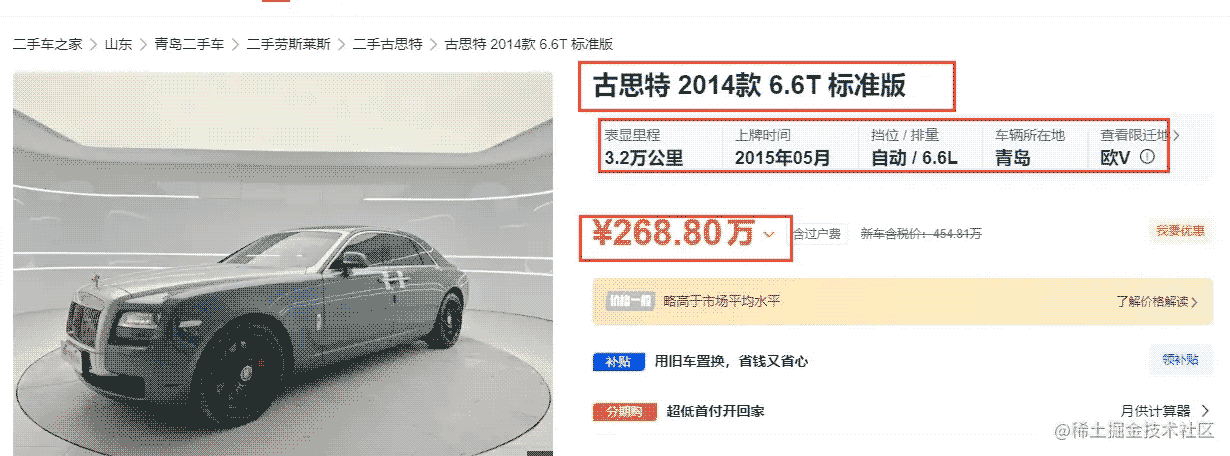
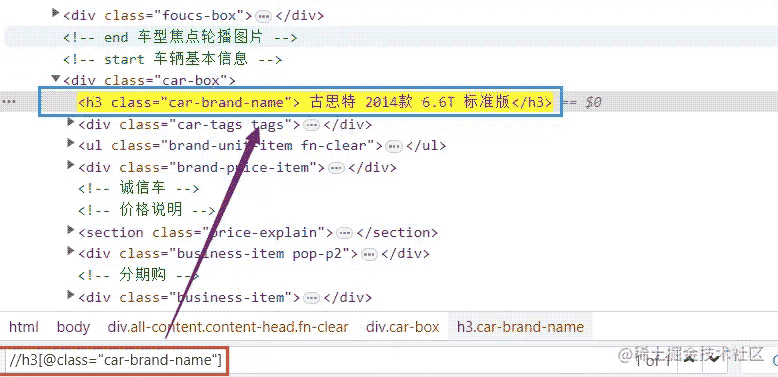
我用不同颜色标注的,就是我们这次想要获取的数据,我们这里以车辆名称为例,讲解下path如何写。
title = detail_selector.xpath('string(//h3[@class="car-brand-name"])').get("").strip()
我们看看网页源代码是如何得到的xpath。
可能有人就要问了,这个
("").strip()
是什么意思?这个就是去除空格的,只是为了后期数据的美观。
后面的我就不一一展示了,我直接放代码了,不懂的在评论区交流。
tableShowMileage = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[1]/h4/text()').get("").strip()
theRegistrationTime = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[2]/h4/text()').get("").strip()
blockADisplacement = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[3]/h4/text()').get("").strip()
addr = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[4]/h4/text()').get("").strip()
guobiao = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[5]/h4/text()').get("").strip()
price = detail_selector.xpath('string(//span[@id="overlayPrice"])').get()
我们打印这些数据,看看效果吧。

可能大家注意到了,有返回空值的,这个可能就是被反爬,大家感兴趣可以用代理IP试试。
保存数据
和我们上一篇一样,我们先写入字典,然后在写入csv文件里面。
dit ={
'车辆':title,
'表显里程':tableShowMileage,
'上牌时间':theRegistrationTime,
'挡位/排量':blockADisplacement,
'车辆所在地':addr,
'查看限迁地':guobiao,
'价格':price,
}
csv_writer.writerow(dit)
大家感兴趣还可以获取车辆信息更详细的数据,其实原理都是一样的。
总结
通过本文的学习,我们学习了数据采集。我们在采集数据的时候,遇到各种问题,自己在尝试解决问题,也是在一种学习,本次实战,我们明白如何使用xpath解析数据。
以上就是Python采集二手车数据的超详细讲解的详细内容,更多关于Python采集二手车数据的资料请关注我们其它相关文章!
相关推荐
-
Python采集C站热榜数据实战示例
目录 前言 功能实现 解析数据 保存数据 总结 前言 大家好,我们今天来爬取c站的热搜榜,把其文章名称,链接和作者获取下来,我们保存到本地,我们通过测试,发现其实很简单,我们只要简单获取数据就可以.没有加密的东西. 功能实现 我们话不多说,我们先找到url,也就是请求地址.我们代码如下: url = 'https://blog.csdn.net/phoenix/web/blog/hot-rank?page=0&pageSize=25&type=' headers = { 'user-age
-
Python采集某评论区内容的实现示例
目录 前言 发送请求 解析数据 总结 前言 我们知道在这个互联网时代,评论已经在我们的生活到处可见,评论区里面的信息是一个非常有趣和有争议的地方.我们今天,就来获取某技术平台的评论,和大家分享一下,我获取数据的过程,也是一个尝试的过程. 发送请求 我们首先,确定我们要获取哪一个文章下面的评论区.我们先使用开发者工具,定位到我们要的数据. 我们通过数据抓取,我们发现,这个平台的评论区数据,放在了一个叫getlist数据包里面了. 我们就不难明白,我们只要请求这个url,在传一个关于文章的参数,我们
-
Python采集情感音频的实现示例
目录 前言 发送请求 获取数据 解析数据 保存数据 总结 前言 我最近喜欢去听情感类的节目,比如说,婚姻类,我可能老了吧.我就想着怎么把音乐下载下来了,保存到手机上,方便我们业余时间去听. 发送请求 首先,我们要确定我们的目标网址,我们想要获取到每一个音频的地址. 我们发送请求,获取网页源代码.我们相信大家这里的代码都会写了. url = 'https://www.ximalaya.com/album/37453303' headers = { 'User-Agent': 'Mozilla/5.
-
Python采集C站高校信息实战示例
目录 前言 功能实现 内容获取 总结 前言 大家好,我们今天来爬取c站的高校名单,把其高校名单,成员和内容数获取下来,不过,我们发现这个网站比我们平时多了一个验证,下面看看我是怎么解决的. 功能实现 话不多说,我们和平时一样,发送我们的请求,按照平时,我们看看代码怎么写. url = 'https://bizapi.csdn.net/community-cloud/v1/homepage/community/by/tag?deviceType=PC&tagId=37' headers = { '
-
Python采集热搜数据实现详解
目录 功能实现 发送请求 解析数据 获取内容 拓展内容 总结 功能实现 随着互联网的发展,信息的传播越来越快速和便捷.在这个信息爆炸的时代,如何快速获取有用的信息已经成为了一个重要的能力.而爬取网站信息则是获取信息的一种重要方式.本文将介绍如何使用Python爬取百度热搜,并对爬取过程进行详细说明. 其实,这个并不难.现在,看我是如何一步一步获取到数据的. 发送请求 我们首先确定网址,我们先使用开发者工具,定位到我们要的数据.发现,内容就在网页源代码中. urllib = 'https://to
-

Python 数据可视化超详细讲解折线图的实现
绘制简单的折线图 在使用matplotlib绘制简单的折线图之前首先需要安装matplotlib,直接在pycharm终端pip install matplotlib即可 使用matplotlib绘制简单的折线图,再对其进行定制,实现数据的可视化操作 import matplotlib.pyplot as plt # 导入pyplot模块并设置别名为plt squares = [1, 4, 9, 16, 25] plt.plot(squares) plt.show() # 打开matplotib
-
Java SpringMVC数据响应超详细讲解
目录 1)页面跳转 2)回写数据 3)配置注解驱动 4)知识要点 1)页面跳转 直接返回字符串:此种方式会将返回的字符串与视图解析器的前后缀拼接后跳转. 返回带有前缀的字符串: 转发: forward:/WEB-INF/views/index.jsp 重定向: redirect:/index.jsp 通过ModelAndView对象返回 @RequestMapping("/quick2") public ModelAndView quickMethod2(){ ModelAn
-
python绘图之坐标轴的超详细讲解
目录 1. 2D坐标轴 1.1 绘制简单的曲线 1.2 坐标轴的刻度线向内 1.3 将坐标刻度从整0开始 1.4 设置刻度栅格 1.5 不显示坐标 1.6 坐标值 1.7 绘制横线和竖线 1.8 设置坐标点的颜色 1.9 双坐标 2. 3D坐标轴 2.1 绘制3D散点图 2.2 绘制3D曲面图 2.3 绘制3D柱形图 引用 总结 1. 2D坐标轴 1.1 绘制简单的曲线 import matplotlib.pyplot as plt import numpy as np x=np.linspac
-
Python超详细讲解内存管理机制
目录 什么是内存管理机制 一.引用计数机制 二.数据池和缓存 什么是内存管理机制 python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一 个叫做refchain的双向循环链表中,每个数据都保存如下信息: 1. 链表中数据前后数据的指针 2. 数据的类型 3. 数据值 4. 数据的引用计数 5. 数据的长度(list,dict..) 一.引用计数机制 引用计数增加: 1.1 对象被创建 1.2 对象被别的变量引用(另外起了个名字) 1.3 对象被作为元素,
-
Python超详细讲解元类的使用
目录 类的定义 一.什么是元类 二.注意区分元类和继承的基类 三.type 元类的使用 四.自定义元类的使用 类的定义 对象是通过类创建的,如下面的代码: # object 为顶层基类 class Work(object): a = 100 Mywork = Work() # 实例化 print(Mywork ) # Mywork 是 Work 所创建的一个对象 <__main__.Work object at 0x101eb4630> print(type(Mywork)) # <cl
-
Python进程间通讯与进程池超详细讲解
目录 进程间通讯 队列Queue 管道Pipe 进程池Pool 在<多进程并发与同步>中介绍了进程创建与信息共享,除此之外python还提供了更方便的进程间通讯方式. 进程间通讯 multiprocessing中提供了Pipe(一对一)和Queue(多对多)用于进程间通讯. 队列Queue 队列是一个可用于进程间共享的Queue(内部使用pipe与锁),其接口与普通队列类似: put(obj[, block[, timeout]]):插入数据到队列(默认阻塞,且没有超时时间): 若设定了超时且
-
Python多进程并发与同步机制超详细讲解
目录 多进程 僵尸进程 Process类 函数方式 继承方式 同步机制 状态管理Managers 在<多线程与同步>中介绍了多线程及存在的问题,而通过使用多进程而非线程可有效地绕过全局解释器锁. 因此,通过multiprocessing模块可充分地利用多核CPU的资源. 多进程 多进程是通过multiprocessing包来实现的,multiprocessing.Process对象(和多线程的threading.Thread类似)用来创建一个进程对象: 在类UNIX平台上,需要对每个Proce
-
Python海象运算符超详细讲解
目录 介绍 语法 用法 if 语句 while 循环 while 循环逐行读取文件 while 循环验证输入 推导式 三元表达式 总结 介绍 海象运算符,即 := ,在 PEP 572 中被提出,并在 Python3.8 版本中发布. 海象运算符的英文原名叫Assignment Expresions,即赋值表达式. 它由一个冒号:和一个等号=组成,即:=.而它被称作walrus operator(海象运算符),是因为它长得像一只海象. 语法 海象运算符的语法格式如下: variable_name
-
超详细讲解python正则表达式
目录 正则表达式 1.1 正则表达式字符串 1.1.1 元字符 1.1.2 字符转义 1.1.3 开始与结束字符 1.2 字符类 1.2.1 定义字符类 1.2.2 字符串取反 1.2.3 区间 1.2.4 预定义字符类 1.3 量词 1.3.1 量词的使用 1.3.2 贪婪量词和懒惰量词 1.4 分组 1.4.1 分组的使用 1.4.2 分组命名 1.4.3 反向引用分组 1.4.4 非捕获分组 1.5 re模块 1.5.1 search()和match()函数 1.5.2 findall()
-
Python OpenCV超详细讲解读取图像视频和网络摄像头
0.准备工作 右击新建的项目,选择Python File,新建一个Python文件,然后在开头import cv2导入cv2库. 1.读取图像调用imread()方法获取我们资源文件夹中的图片使用imshow()方法显示图片,窗口名称为OutputwaitKey(0)这句可以让窗口一直保持,如果去掉这句,窗口会一闪而过 我们来看下效果: 2.读取视频VideoCapture()方法的参数就是视频文件循环中通过read不断地去读视频的每一帧,再通过imshow显示出来最后if语句代表按q可以退出程