pandas 实现将NaN转换为None
在python中,用pandas处理数据非常方便。
但是有时候从其他地方读取数据时,会有异常值需要处理。
比如,我们要从excel读取数据然后调用接口写入数据库时,读取到的空值是NaN,但是,接口接收的对应单元格数据应该是None,这时候怎么处理呢?当然,用pandas做这个事也是非常容易的。
示例如下:
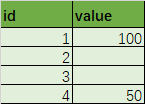
原始数据:
示例代码:
import pandas as pd
df = pd.read_excel('data/test_data.xlsx')
# 将非空数据保留,空数据用None替换
df = df.where(df.notnull(), None)
print(df)
输出结果:
id value
0 1 100
1 2 None
2 3 None
3 4 50
补充:Pandas Nan & None 处理
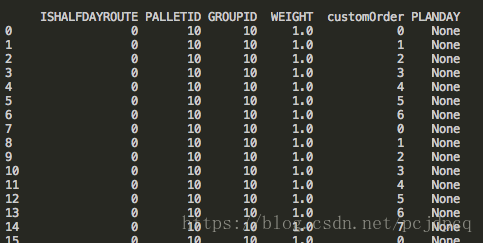
在处理数据的时候遇到这个问题。
数据库里的值 是null
然后读取数据库后得到的dataframe 里显示的事None.
想把这些None 装换成0.0 但是试过很多方法都不奏效。
使用过
df['PLANDAY'].replace('None',0)
未奏效
这个判断句是生效的
df.loc[0,'PLANDAY'] is None:
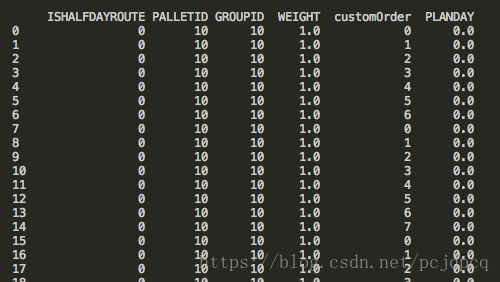
后来发现这个数据类型是Nan 不是None
因此使用解决了上诉问题。
df['PLANDAY'] = df['PLANDAY'].fillna(0.0)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas 缺失值与空值处理的实现方法
1.相关函数 df.dropna() df.fillna() df.isnull() df.isna() 2.相关概念 空值:在pandas中的空值是"" 缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可 3.函数具体解释 DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 函数作用:删除含有空值的行或列 axis:维度,axis=
-
在Pandas中处理NaN值的方法
关于NaN值 -在能够使用大型数据集训练学习算法之前,我们通常需要先清理数据, 也就是说,我们需要通过某个方法检测并更正数据中的错误. - 任何给定数据集可能会出现各种糟糕的数据,例如离群值或不正确的值,但是我们几乎始终会遇到的糟糕数据类型是缺少值. - Pandas 会为缺少的值分配 NaN 值. 创建一个具有NaN值得 Data Frame import pandas as pd # We create a list of Python dictionaries # 创建一个字典列表 ite
-
Python Pandas对缺失值的处理方法
Pandas使用这些函数处理缺失值: isnull和notnull:检测是否是空值,可用于df和series dropna:丢弃.删除缺失值 axis : 删除行还是列,{0 or 'index', 1 or 'columns'}, default 0 how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除 inplace : 如果为True则修改当前df,否则返回新的df fillna:填充空值 value:用于填充的值,可以是单个值,或者字典(key是列名,valu
-

pandas 实现将NaN转换为None
在python中,用pandas处理数据非常方便. 但是有时候从其他地方读取数据时,会有异常值需要处理. 比如,我们要从excel读取数据然后调用接口写入数据库时,读取到的空值是NaN,但是,接口接收的对应单元格数据应该是None,这时候怎么处理呢?当然,用pandas做这个事也是非常容易的. 示例如下: 原始数据: 示例代码: import pandas as pd df = pd.read_excel('data/test_data.xlsx') # 将非空数据保留,空数据用None替换 d
-
python利用pandas将excel文件转换为txt文件的方法
python将数据换为txt的方法有很多,可以用xlrd库实现.本人比较懒,不想按太多用的少的插件,利用已有库pandas将excel文件转换为txt文件. 直接上代码: ''' function:将excel文件转换为text author:Nstock date:2018/3/1 ''' import pandas as pd import re import codecs #将excel转化为txt文件 def exceltotxt(excel_dir, txt_dir): with co
-
使用Pandas将inf, nan转化成特定的值
1. 数据处理中很恶心,出现 RuntimeWarning: divide by zero encountered in divide 发现自己的DataFrame中有除以0的运算,出现了Inf值 2. 为了不让该值影响到我们,打算将inf全变成NaN,则适用replace进行计算 df.replace([np.inf, -np.inf], np.nan) 3. 举例实现: In [0]: df = pd.DataFrame([1, 2, np.inf, -np.inf]) In [1]: df
-
Python Pandas中缺失值NaN的判断,删除及替换
目录 前言 1. 检查缺失值NaN 2. Pandas中NaN的类型 3. NaN的删除 dropna() 3.1 删除所有值均缺失的行/列 3.2 删除至少包含一个缺失值的行/列 3.3 根据不缺少值的元素数量删除行/列 3.4 删除特定行/列中缺少值的列/行 4. 缺失值NaN的替换(填充) fillna() 4.1 用通用值统一替换 4.2 为每列替换不同的值 4.3 用每列的平均值,中位数,众数等替换 4.4 替换为上一个或下一个值 总结 前言 当使用pandas读取csv文件时,如果元
-
浅谈pandas中对nan空值的判断和陷阱
pandas基于numpy,所以其中的空值nan和numpy.nan是等价的.numpy中的nan并不是空对象,其实际上是numpy.float64对象,所以我们不能误认为其是空对象,从而用bool(np.nan)去判断是否为空值,这是不对的. 对于pandas中的空值,我们该如何判断,并且有哪些我们容易掉进去的陷阱,即不能用怎么样的方式去判断呢? 可以判断pandas中单个空值对象的方式: 1.利用pd.isnull(),pd.isna(); 2.利用np.isnan(); 3.利用is表达式
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值
-
pandas中read_csv的缺失值处理方式
今天遇到的问题是,要将一份csv数据读入dataframe,但某些列中含有NA值.对于这些列来说,NA应该作为一个有意义的level,而不是缺失值,但read_csv函数会自动将类似的缺失值理解为缺失值并变为NaN. 看pandas文档中read_csv函数中这两个参数的描述,默认会将'-1.#IND', '1.#QNAN', '1.#IND', '-1.#QNAN', '#N/A N/A','#N/A', 'N/A', 'NA', '#NA', 'NULL', 'NaN', '-NaN', '
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
使用pandas读取文件的实现
pandas可以将读取到的表格型数据(文件不一定要是表格)转成DataFrame类型的数据结构,然后我们可以通过操作DataFrame进行数据分析,数据预处理以及行和列的操作等.下面介绍一些常用读取文件的方法 1.read_csv函数 功能:从文件.URL.文件新对象中加载带有分隔符的数据,默认分隔符是逗号. data.txt a,b,c,d,name 1,2,3,4,python 5,6,7,8,java 9,10,11,12,c++ data = pd.read_csv("data.txt&