Python实现基于Fasttext的商品评论数据分类的操作流程
在以往的文本分类型的任务中,基本的流程主要是就是:
- 文本数据加载
- 数据清洗
- 分词
- 向量化
- 分类模型训练
- 性能评估
这里面比如向量化和模型搭建是独立的两个节点,可以自由地进行设计,当然了也是一份工作量,今天使用的fasttext更像是一个集成的库,把向量化和分类一起做掉了,这个对于使用层面来讲就更方便了一些,不过也并不是绝对的,一般经验来说,封装程度越高的库对于个性化的开发越不友好,但是如果仅仅只是使用一下就行,能够实现自己的功能这样的想法的话倒是可以使用这种类型的库的,总之,没有绝对的最优,只有适合自己的模型。
本文主要也是基于具体的应用来体验fasttext,整体流程如下:

为了清晰展示流程,这里我用不同的颜色来标识不同的功能部分:
绿色部分为数据采集部分,这部分由于部分原因无法开放到这里
蓝色部分为数据处理部分,这部分主要完成原始数据的清洗分词等工作
黄色部分主要是实例化调用fasttext提供的模型来完成分类评估等工作
首先看下原始数据样例如下:
{
'_id': '4c671f75cc20b28264c30c2ef158f32b',
'guid': 'b2422b96a015b85d9a47c83e65f01987',
'content': 'iPhone13收到了,很喜欢的苹果手机,一直都是苹果的忠实粉丝。13手机外观真的太惊艳了,最新款的手机就是不一样,非常的好看!午夜色也是很惊艳的,是我很喜欢的颜色。外观设计非常的好看,小巧精致,很喜欢iPhone的产品。新款的相机非常好,拍摄效果强大,很适合爱美的女生拍照。拍视频的电影模式也是非常惊艳,真的太棒了,滤镜自带美颜效果,非常特别!前置摄像头也有亮点,优化升级,升级后的像素真的超棒!萌萌的摄像头,手机大小合适,握着手感很舒服。屏幕非常细腻,通透,屏幕很喜欢!新一代运行速度快了很多,系统非常流畅,屏幕120hz刷新率。电池也还不错,正常使用,续航能力还是挺久的,玩游戏也不会发烫。买了套装一年延保的,感觉还是很不错的!A15速度还是很快的,加上iOS15的加持,手机很流畅,使用了一周了,手机各方面都很不错!',
'creationTime': '2021-11-2907: 13: 51',
'isDelete': False,
'isTop': False,
'userImageUrl': 'misc.360buyimg.com/user/myjd-2015/css/i/peisong.jpg',
'topped': 0,
'replies': [
{
'id': 946189091,
'commentId': 16739194625,
'content': '谢谢您对本店的支持,我们会不断的努力,争取做的更好,我们成长的路上有您的支持,我们表示感谢,欢迎再次光临。祝您生活愉快,合家安康!',
'pin': 'jd_oMFlwVDJJjkA',
'userClient': 98,
'userImage': 'misc.360buyimg.com/user/myjd-2015/css/i/peisong.jpg',
'ip': '115.207.85.31',
'productId': 10039695828478,
'replyList': [
],
'nickname': 'jd_oMFlwVDJJjkA',
'creationTime': '2021-11-2910: 10: 54',
'parentId': 0,
'targetId': 0,
'venderShopInfo': {
'id': 10706414,
'appName': '//mall.jd.com/index-10706414.html',
'title': '京东之家官方旗舰店',
'venderId': 10955089
}
}
],
'replyCount': 28,
'score': 5,
'imageStatus': 1,
'usefulVoteCount': 28,
'userClient': 4,
'discussionId': 1006752884,
'imageCount': 8,
'anonymousFlag': 1,
'plusAvailable': 201,
'mobileVersion': '10.2.4',
'mergeOrderStatus': 2,
'productColor': '128G午夜色',
'productSize': '套装五:搭配店铺延保一年',
'textIntegral': 40,
'imageIntegral': 40,
'status': 1,
'referenceId': '10039695828478',
'referenceTime': '2021-11-0802: 31: 34',
'nickname': 'z***a',
'replyCount2': 39,
'userImage': 'misc.360buyimg.com/user/myjd-2015/css/i/peisong.jpg',
'orderId': 0,
'integral': 80,
'productSales': '[
]',
'referenceImage': 'jfs/t1/124476/38/25971/146827/622b14cfEec332c92/75f5bf4417c1fd1d.jpg',
'referenceName': '【12期免息可选】Apple苹果iPhone13(A2634)全网通5G手机128G绿色套装一:搭配90天品胜碎屏保障',
'firstCategory': 9987,
'secondCategory': 653,
'thirdCategory': 655,
'aesPin': None,
'days': 21,
'afterDays': 0,
'comp_con': 'iPhone13收到了很喜欢的苹果手机一直都是苹果的忠实粉丝13手机外观真的太惊艳了最新款的手机就是不一样非常的好看午夜色也是很惊艳的是我很喜欢的颜色外观设计非常的好看小巧精致很喜欢iPhone的产品新款的相机非常好拍摄效果强大很适合爱美的女生拍照拍视频的电影模式也是非常惊艳真的太棒了滤镜自带美颜效果非常特别前置摄像头也有亮点优化升级升级后的像素真的超棒萌的摄像头手机大小合适握着手感很舒服屏幕非常细腻通透屏幕很喜欢新一代运行速度快了很多系统非常流畅屏幕120hz刷新率电池也还不错正常使用续航能力还是挺久的玩游戏也不会发烫买了套装一年延保的感觉还是很不错的A15速度还是很快的加上iOS15的加持手机很流畅使用了一周了手机各方面都很不错',
'label': 1,
'cut_li': [
'iPhone',
'13',
'收到',
'喜欢',
'苹果',
'手机',
'一直',
'苹果',
'忠实',
'粉丝',
'13',
'手机',
'外观',
'真的',
'太',
'惊艳',
'最新款',
'手机',
'非常',
'好看',
'午夜',
'色',
'惊艳',
'喜欢',
'颜色',
'外观设计',
'非常',
'好看',
'小巧',
'精致',
'喜欢',
'iPhone',
'产品',
'新款',
'相机',
'非常',
'拍摄',
'效果',
'强大',
'适合',
'爱美',
'女生',
'拍照',
'拍',
'视频',
'电影',
'模式',
'非常',
'惊艳',
'真的',
'太棒了',
'滤镜',
'自带',
'美颜',
'效果',
'非常',
'特别',
'前置',
'摄像头',
'亮点',
'优化',
'升级',
'升级',
'像素',
'真的',
'超棒',
'萌',
'摄像头',
'手机',
'大小',
'合适',
'握',
'手感',
'舒服',
'屏幕',
'非常',
'细腻',
'通透',
'屏幕',
'喜欢',
'新一代',
'运行',
'速度',
'快',
'很多',
'系统',
'非常',
'流畅',
'屏幕',
'120hz',
'刷新率',
'电池',
'不错',
'正常',
'使用',
'续航',
'能力',
'挺久',
'玩游戏',
'不会',
'发烫',
'买',
'套装',
'一年',
'延保',
'感觉',
'不错',
'A15',
'速度',
'很快',
'加上',
'iOS15',
'加持',
'手机',
'流畅',
'使用',
'一周',
'手机',
'方面',
'不错'
],
'cut_con': 'iPhone13收到喜欢苹果手机一直苹果忠实粉丝13手机外观真的太惊艳最新款手机非常好看午夜色惊艳喜欢颜色外观设计非常好看小巧精致喜欢iPhone产品新款相机非常拍摄效果强大适合爱美女生拍照拍视频电影模式非常惊艳真的太棒了滤镜自带美颜效果非常特别前置摄像头亮点优化升级升级像素真的超棒萌摄像头手机大小合适握手感舒服屏幕非常细腻通透屏幕喜欢新一代运行速度快很多系统非常流畅屏幕120hz刷新率电池不错正常使用续航能力挺久玩游戏不会发烫买套装一年延保感觉不错A15速度很快加上iOS15加持手机流畅使用一周手机方面不错',
'label_con': '__label__1,
iPhone13收到喜欢苹果手机一直苹果忠实粉丝13手机外观真的太惊艳最新款手机非常好看午夜色惊艳喜欢颜色外观设计非常好看小巧精致喜欢iPhone产品新款相机非常拍摄效果强大适合爱美女生拍照拍视频电影模式非常惊艳真的太棒了滤镜自带美颜效果非常特别前置摄像头亮点优化升级升级像素真的超棒萌摄像头手机大小合适握手感舒服屏幕非常细腻通透屏幕喜欢新一代运行速度快很多系统非常流畅屏幕120hz刷新率电池不错正常使用续航能力挺久玩游戏不会发烫买套装一年延保感觉不错A15速度很快加上iOS15加持手机流畅使用一周手机方面不错'
}
之后对原始数据进行解析处理:
# 文本去重
con_li = []
data_clear = []
for item in data:
if item["content"] not in con_li:
con_li.append(item["content"])
data_clear.append(item)
print("文本去重过滤条数:%s" % (len(data) - len(data_clear)))
print("剩余评论个数:", len(con_li)) # 剩余评论个数
def clean_txt(raw):
"""
提取清洗
"""
fil = re.compile(r"[^0-9a-zA-Z\u4e00-\u9fa5]+")
return fil.sub(" ", raw)
compress_num = 0
for i, item in enumerate(data_clear):
temp_com = item["content"]
compress_com = clean_txt(temp_com)
if compress_com != temp_com:
compress_num += 1
item["comp_con"] = compress_com
data_clear[i] = item
print("data_clear_legnth: ", len(data_clear))
for one in data_clear[:3]:
print("one: ", one)
接着对清洗处理好的数据记性分词和数据组装:
# 进行结巴分词
stop_words = []
with open("cn_stopwords.txt", "r", encoding="utf-8") as f:
stop_words = f.readlines()
stop_words = [sw.strip() for sw in stop_words]
stop_words.append("\n")
data_li = []
for i, item in enumerate(data_final):
cut_li = list(jieba_fast.cut(item["comp_con"]))
cut_clear_li = [c.strip() for c in cut_li if c.strip() and c not in stop_words]
item["cut_li"] = cut_clear_li
cut_con = " ".join(cut_clear_li)
item["cut_con"] = cut_con
label_con = "__label__%s , %s" % (item["label"], item["cut_con"])
item["label_con"] = label_con
data_li.append(label_con)
data_final[i] = item
print("data_final_legnth: ", len(data_final))
for one in data_final[:3]:
print("one: ", one)
处理后的数据如下:

虽然说看着有些奇怪,尤其是: __label__,但是这个没办法,fasttext需要的标准数据格式就是这个样子的。
之后就可以进行模型训练了,核心实现如下:
def train_model(ipt=None, opt=None, model="", dim=100, epoch=5, lr=0.5, loss="softmax"):
np.set_printoptions(suppress=True)
classifier = fasttext.train_supervised(
ipt, label="__label__", dim=dim, epoch=epoch, lr=lr, wordNgrams=4, loss=loss
)
"""
训练一个监督模型, 返回一个模型对象
@param input: 训练数据文件路径
@param lr: 学习率
@param dim: 向量维度
@param ws: cbow模型时使用
@param epoch: 次数
@param minCount: 词频阈值, 小于该值在初始化时会过滤掉
@param minCountLabel: 类别阈值,类别小于该值初始化时会过滤掉
@param minn: 构造subword时最小char个数
@param maxn: 构造subword时最大char个数
@param neg: 负采样
@param wordNgrams: n-gram个数
@param loss: 损失函数类型, softmax, ns: 负采样, hs: 分层softmax
@param bucket: 词扩充大小, [A, B]: A语料中包含的词向量, B不在语料中的词向量
@param thread: 线程个数, 每个线程处理输入数据的一段, 0号线程负责loss输出
@param lrUpdateRate: 学习率更新
@param t: 负采样阈值
@param label: 类别前缀
@param verbose: ??
@param pretrainedVectors: 预训练的词向量文件路径, 如果word出现在文件夹中初始化不再随机
@return model object
"""
classifier.save_model(opt)
return classifier
这里同样实现了对于模型结果的评估方法:
def cal_precision_and_recall(file="test.txt"):
"""
计算每个标签 的precision和recall
"""
precision = defaultdict(int, 1)
recall = defaultdict(int, 1)
total = defaultdict(int, 1)
with open(file, encoding="utf-8") as f:
for line in f:
label, content = line.split(",", 1)
total[label.strip().strip("__label__")] += 1
labels2 = classifier.predict([content.strip()])
pre_label, sim = labels2[0][0][0], labels2[1][0][0]
recall[pre_label.strip().strip("__label__")] += 1
if label.strip() == pre_label.strip():
precision[label.strip().strip("__label__")] += 1
print("{:<10} {:<30}".format("precision", str(precision.dict)))
print("{:<10} {:<30}".format("recall", str(recall.dict)))
print("{:<10} {:<30}".format("total", str(total.dict)))
for sub in precision.dict:
pre = precision[sub] / total[sub]
rec = precision[sub] / recall[sub]
F1 = (2 * pre * rec) / (pre + rec)
print(
f"{sub.strip('__label__')} \t precision: {str(pre)} \t recall: {str(rec)} \t F1: {str(F1)}"
)
运行结果如下所示:
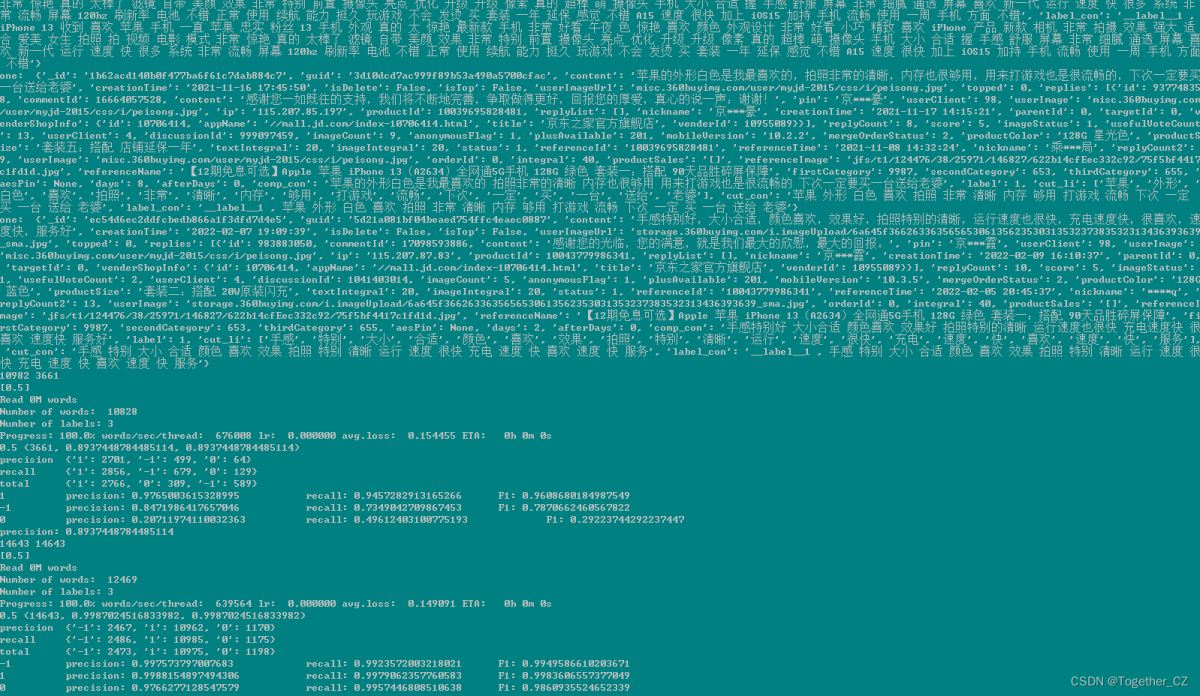
到此这篇关于Python实现基于Fasttext的商品评论数据分类的文章就介绍到这了,更多相关Python Fasttext商品评论内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬取京东商品信息评论存并进MySQL
目录 构建mysql数据表 第一版: 第二版 : 第三版: 构建mysql数据表 问题:使用SQL alchemy时,非主键不能设置为自增长,但是我想让这个非主键仅仅是为了作为索引,autoincrement=True无效,该怎么实现让它自增长呢? from sqlalchemy import String,Integer,Text,Column from sqlalchemy import create_engine from sqlalchemy.orm import sessionmake
-

python 爬取京东指定商品评论并进行情感分析
项目地址 https://github.com/DA1YAYUAN/JD-comments-sentiment-analysis 爬取京东商城中指定商品下的用户评论,对数据预处理后基于SnowNLP的sentiment模块对文本进行情感分析. 运行环境 Mac OS X Python3.7 requirements.txt Pycharm 运行方法 数据爬取(jd.comment.py) 启动jd_comment.py,建议修改jd_comment.py中变量user-agent为自己浏览器用户
-
python制作爬虫爬取京东商品评论教程
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化.下面是要抓取的商品信息,一款女士文胸.这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论. 京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息.因此我们需要先找到存放商品评论信息的文件.这里我们使用Chrome浏览器里的开发者工具进行查找. 具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界
-
Python 类,对象,数据分类,函数参数传递详解
目录 1.基本概念 1.1 类与对象的关系 1.3 对象的创建与引用 2.数据的分类 2.1 不可变类型 2.2 可变类型 3.函数传递参数的方式 3.1 值传递 3.2 引用传递 总结 最近在基于python写的接口自动化脚本,从Excel表中读取所有数据,每一行数据保存为字典,再将很多行的字典数据保存到一个列表里,运行时发现,列表中的字典均相同,且一直是excel最后一行的数据,情况类比如下: dd = {"a":1,"b":10} i = 2 list1 =
-
Python实现基于Fasttext的商品评论数据分类的操作流程
在以往的文本分类型的任务中,基本的流程主要是就是: 文本数据加载 数据清洗 分词 向量化 分类模型训练 性能评估 这里面比如向量化和模型搭建是独立的两个节点,可以自由地进行设计,当然了也是一份工作量,今天使用的fasttext更像是一个集成的库,把向量化和分类一起做掉了,这个对于使用层面来讲就更方便了一些,不过也并不是绝对的,一般经验来说,封装程度越高的库对于个性化的开发越不友好,但是如果仅仅只是使用一下就行,能够实现自己的功能这样的想法的话倒是可以使用这种类型的库的,总之,没有绝对的最优,只有
-
基于Python获取亚马逊的评论信息的处理
目录 一.分析亚马逊的评论请求 二.获取亚马逊评论的内容 三.亚马逊评论信息的处理 四.代码整合 4.1代理设置 4.2while循环翻页 总结 上次亚马逊的商品信息都获取到了,自然要看一下评论的部分.用户的评论能直观的反映当前商品值不值得购买,亚马逊的评分信息也能获取到做一个评分的权重. 亚马逊的评论区由用户ID,评分及评论标题,地区时间,评论正文这几个部分组成,本次获取的内容就是这些. 测试链接:https://www.amazon.it/product-reviews/B08GHGTGQ2
-
基于Django contrib Comments 评论模块(详解)
老版本的Django中自带一个评论框架.但是从1.6版本后,该框架独立出去了,也就是本文的评论插件. 这个插件可给models附加评论,因此常被用于为博客文章.图片.书籍章节或其它任何东西添加评论. 一.快速入门 快速使用步骤: 安装包:pip install django-contrib-comments 在django的settings中的INSTALLED_APPS处添加'django.contrib.sites'进行app注册,并设置SITE_ID值. 在django的settings中
-
详解Python如何批量采集京东商品数据流程
目录 准备工作 驱动安装 模块使用与介绍 流程解析 完整代码 效果展示 准备工作 驱动安装 实现案例之前,我们要先安装一个谷歌驱动,因为我们是使用selenium 操控谷歌驱动,然后操控浏览器实现自动操作的,模拟人的行为去操作浏览器. 以谷歌浏览器为例,打开浏览器看下我们自己的版本,然后下载跟自己浏览器版本一样或者最相近的版本,下载后解压一下,把解压好的插件放到我们的python环境里面,或者和代码放到一起也可以. 模块使用与介绍 selenium pip install selenium ,直
-
Python爬取网易云歌曲评论实现词云图
目录 前言 环境使用 代码实现 先是安装.导入所需模块 1. 创建一个浏览器对象 2. 执行自动化 下拉页面, 直接下拉到页面的底部 3.解析数据 保存数据 翻页 保存为txt文件 运行代码得到结果 再做个词云 导入相关模块 读取文件数据 词云图 分词<中文(词语)> 基于结果 合并 创建词云图 最后效果 前言 emmmm 没什么说的,想说的都在代码里 环境使用 Python 3.8 解释器 3.10 Pycharm 2021.2 专业版 selenium 3.141.0 本次要用到selen
-
Python实现基于HTTP文件传输实例
本文实例讲述了Python实现基于HTTP文件传输的方法.分享给大家供大家参考.具体实现方法如下: 一.问题: 因为需要最近看了一下通过POST请求传输文件的内容 并且自己写了Server和Client实现了一个简单的机遇HTTP的文件传输工具 二.实现代码: Server端: 复制代码 代码如下: #coding=utf-8 from BaseHTTPServer import BaseHTTPRequestHandler import cgi class PostHandler(Base
-
python解析基于xml格式的日志文件
大家中午好,由于过年一直还没回到状态,好久没分享一波小知识了,今天,继续给大家分享一波Python解析日志的小脚本. 首先,同样的先看看日志是个啥样. 都是xml格式的,是不是看着就头晕了??没事,我们先来分析一波. 1.每一段开头都是catalina-exec,那么我们就按catalina-exec来分,分了之后,他们就都是一段一段的了. 2.然后,我们再在已经分好的一段段里面分,找出你要分割的关键字,因为是xml的,所以,接下来的工作就简单了,都是一个头一个尾的. 3.但是还有一个问题,有可
-
python实现基于两张图片生成圆角图标效果的方法
本文实例讲述了python实现基于两张图片生成圆角图标效果的方法.分享给大家供大家参考.具体分析如下: 使用pil的蒙版功能,将原图片和圆角图片进行叠加,并将圆角图片作为mask,生成新的圆角图片 from PIL import Image flower = Image.open('flower.png') border = Image.open('border.png') source = border.convert('RGB') flower.paste(source, mask=bord