YOLO v4常见的非线性激活函数详解
YOLO v4中用到的激活函数是Mish激活函数
在YOLO v4中被提及的激活函数有: ReLU, Leaky ReLU, PReLU, ReLU6, SELU, Swish, Mish
其中Leaky ReLU, PReLU难以训练,ReLU6转为量化网络设计
激活函数使用过程图:

一、饱和激活函数
1.1、Sigmoid
函数表达式:

Sigmoid函数图像及其导数图像:
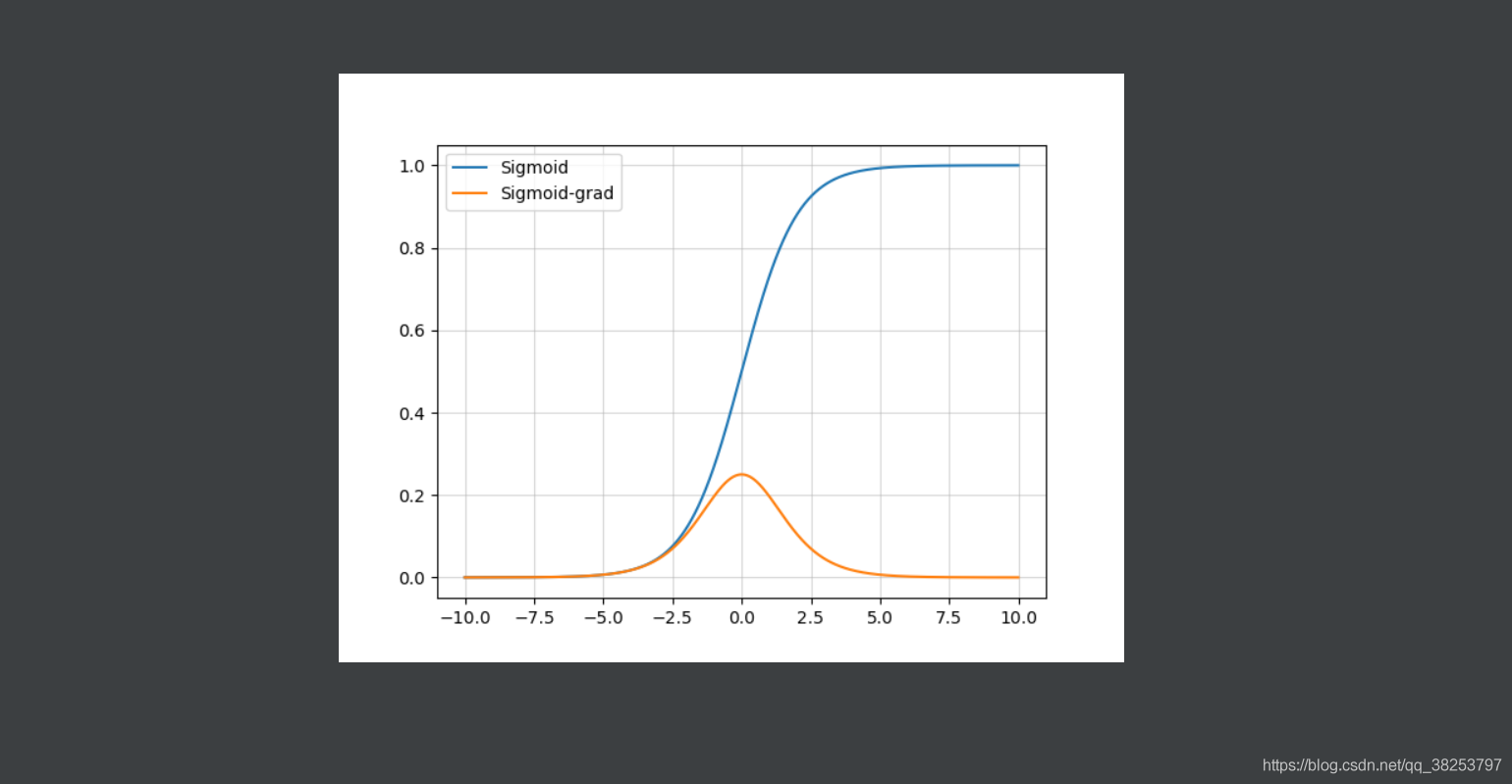
优点:
- 是一个便于求导的平滑函数;
- 能压缩数据,使输出保证在 [ 0 , 1 ] [0,1] [0,1]之间(相当于对输出做了归一化),保证数据幅度不会有问题;
- (有上下界)适合用于前向传播,但是不利于反向传播。
缺点:
- 容易出现梯度消失(gradient vanishing),不利于权重更新;
- 不是0均值(zero-centered)的,这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响。以 f=sigmoid(wx+b)为例, 假设输入均为正数(或负数),那么对w的导数总是正数(或负数),这样在反向传播过程中要么都往正方向更新,要么都往负方向更新,导致有一种捆绑效果,使得收敛缓慢。
- 指数运算,相对耗时。
1.2、hard-Sigmoid函数
hard-Sigmoid函数时Sigmoid激活函数的分段线性近似。
函数公式:

hard-Sigmoid函数图像和Sigmoid函数图像对比:

hard-Sigmoid函数图像及其导数图像:

优点:
- 从公示和曲线上来看,其更易计算,没有指数运算,因此会提高训练的效率。
缺点:
- 首次派生值为零可能会导致神经元died或者过慢的学习率。
1.3、Tanh双曲正切
函数表达式:

Tanh函数图像及其导函数图像:

优点:
- 解决了Sigmoid函数的非zero-centered问题
- 能压缩数据,使输出保证在 [ 0 , 1 ] [0,1] [0,1]之间(相当于对输出做了归一化),保证数据幅度不会有问题;(有上下界)
缺点:
- 还是容易出现梯度消失(gradient vanishing),不利于权重更新;
- 指数运算,相对耗时。
二、非饱和激活函数
2.1、ReLU(修正线性单元)
函数表达式:
f ( z ) = m a x ( 0 , x ) f(z)=max(0,x) f(z)=max(0,x)
ReLU函数图像及其导数图像:

优点:
- ReLu的收敛速度比 sigmoid 和 tanh 快;
- 输入为正时,解决了梯度消失的问题,适合用于反向传播。;
- 计算复杂度低,不需要进行指数运算;
缺点:
- ReLU的输出不是zero-centered;
- ReLU不会对数据做幅度压缩,所以数据的幅度会随着模型层数的增加不断扩张。(有下界无上界)
- Dead ReLU Problem(神经元坏死现象):x为负数时,梯度都是0,这些神经元可能永远不会被激活,导致相应参数永远不会被更新。(输入为负时,函数存在梯度消失的现象)
2.2、ReLU6(抑制其最大值)
函数表达式:

ReLU函数图像和ReLU6函数图像对比:

ReLU6函数图像及其导数图像:
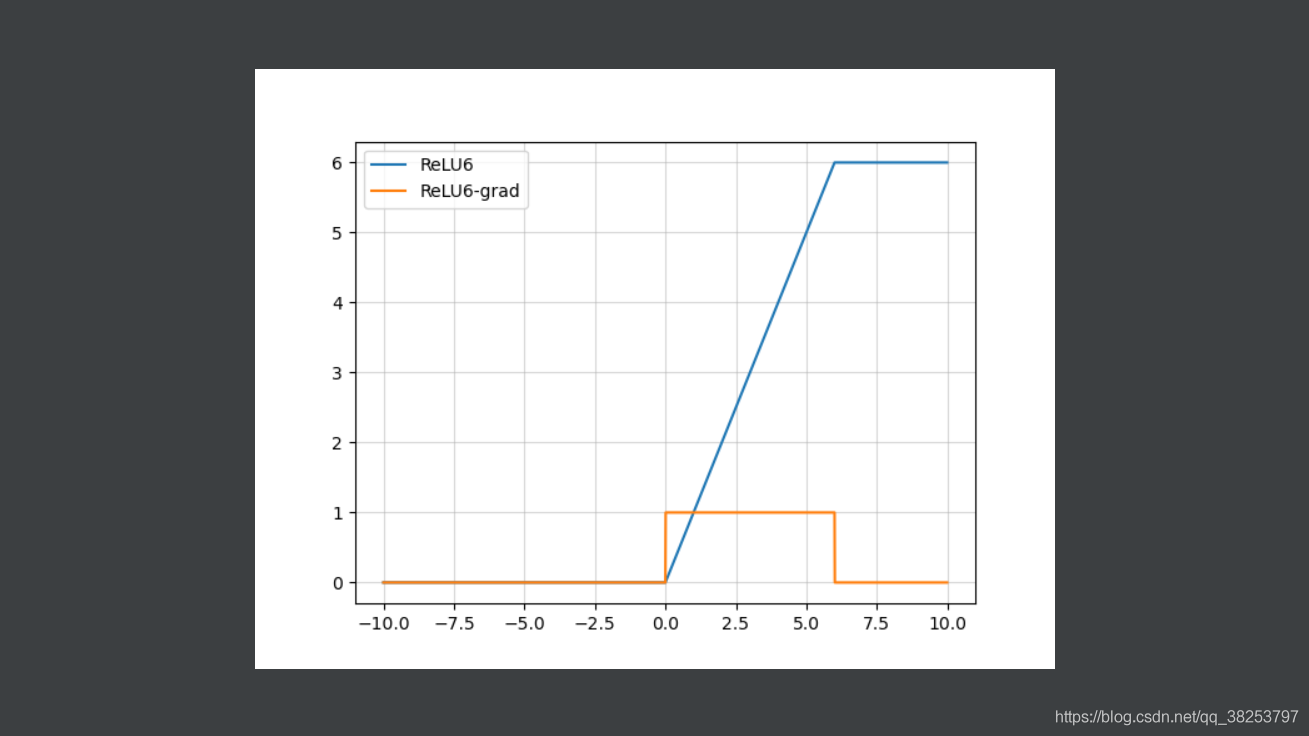
2.3、Leakly ReLU
函数表达式:

ReLU函数图像和Leakly ReLU函数图像对比:

Leakly ReLU函数图像及其导数图像:
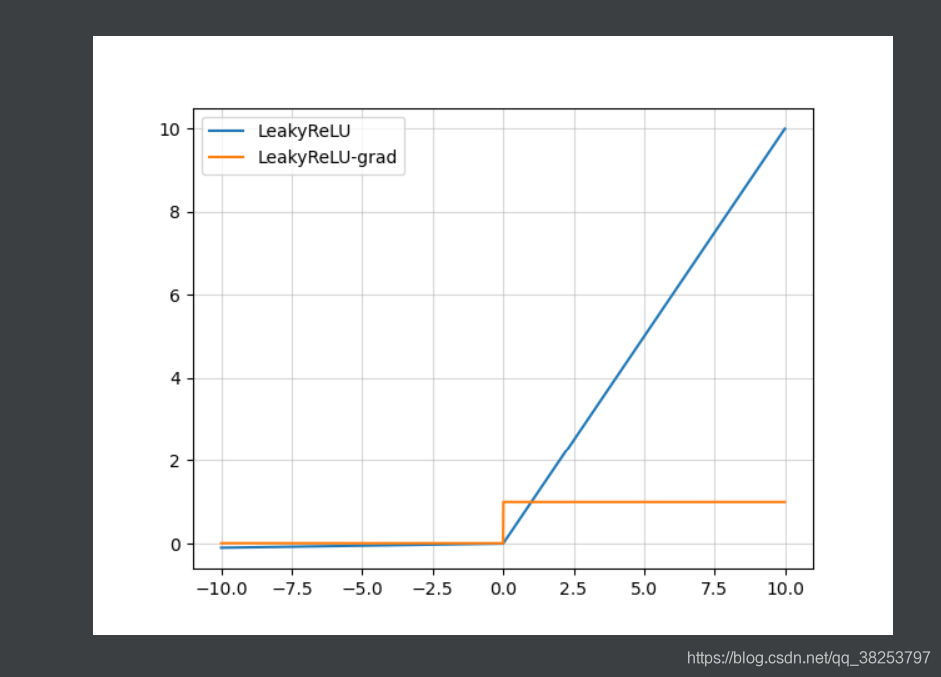
优点:
- 解决上述的dead ReLU现象, 让负数区域也会梯度消失;
理论上Leaky ReLU 是优于ReLU的,但是实际操作中,并不一定。
2.4、PReLU(parametric ReLU)
函数公式:

注意:

函数图像:

优点:
- 可以避免dead ReLU现象;
- 与ELU相比,输入为负数时不会出现梯度消失。
2.5、ELU(指数线性函数)
函数表达式:

ELU函数图像及其导数图像( α = 1.5 \alpha=1.5 α=1.5):

优点:
- 有ReLU的所有优点,且没有Dead ReLU Problem(神经元坏死现象);
- 输出是zero-centered的,输出平均值接近0;
- 通过减少偏置偏移的影响,使正常梯度更加接近自然梯度,从而使均值向0加速学习。
缺点:
- 计算量更高了。
理论上ELU优于ReLU, 但是真实数据下,并不一定。
2.6、SELU
SELU就是在ELU的基础上添加了一个 λ \lambda λ参数,且 λ > 1 \lambda>1 λ>1
函数表达式:

ELU函数图像和SELU函数图像对比( α = 1.5 , λ = 2 \alpha=1.5, \lambda=2 α=1.5,λ=2):

SELU函数图像及其导数图像( α = 1.5 , λ = 2 \alpha=1.5, \lambda=2 α=1.5,λ=2):

优点:
- 以前的ReLU、P-ReLU、ELU等激活函数都是在负半轴坡度平缓,这样在激活的方差过大时可以让梯度减小,防止了梯度爆炸,但是在正半轴其梯度简答的设置为了1。而SELU的正半轴大于1,在方差过小的时候可以让它增大,但是同时防止了梯度消失。这样激活函数就有了一个不动点,网络深了之后每一层的输出都是均值为0,方差为1. 2.7、Swish
函数表达式:

Swish函数图像( β = 0.1 , β = 1 , β = 10 \beta=0.1, \beta=1,\beta=10 β=0.1,β=1,β=10):

Swish函数梯度图像( β = 0.1 , β = 1 , β = 10 \beta=0.1, \beta=1,\beta=10 β=0.1,β=1,β=10):

优点:
- 在x > 0的时候,同样是不存在梯度消失的情况;而在x < 0时候,神经元也不会像ReLU一样出现死亡的情况。
- 同时Swish相比于ReLU导数不是一成不变的,这也是一种优势。
- 而且Swish处处可导,连续光滑。
缺点:
- 计算量大,本来sigmoid函数就不容易计算,它比sigmoid还难。 2.8、hard-Swish
hard = 硬,就是让图像在整体上没那么光滑(从下面两个图都可以看出来)
函数表达式:

hard-Swish函数图像和Swish( β = 1 \beta=1 β=1)函数图像对比:

hard-Swish函数图像和Swish( β = 1 \beta=1 β=1)函数梯度图像对比:

优点:
- hard-Swish近似达到了Swish的效果;
- 且改善了Swish的计算量过大的问题,在量化模式下,ReLU函数相比Sigmoid好算太多了;
2.9、Mish
论文地址:
https://arxiv.org/pdf/1908.08681.pdf
关于激活函数改进的最新一篇文章,且被广泛用于YOLO4中,相比Swish有0.494%的提升,相比ReLU有1.671%的提升。
Mish函数公式:

Mish函数图像和Swish( β = 1 \beta=1 β=1)函数图像对比:

Mish函数图像和Swish( β = 1 \beta=1 β=1)函数导数图像对比:

为什么Mish表现的更好:
上面无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许更好的梯度流,而不是像ReLU中那样的硬零边界。
最后,可能也是最重要的,目前的想法是,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。Mish函数在曲线上几乎所有点上都极其平滑。
三、PyTorch 实现
import matplotlib.pyplot as plt
import numpy as np
class ActivateFunc():
def __init__(self, x, b=None, lamb=None, alpha=None, a=None):
super(ActivateFunc, self).__init__()
self.x = x
self.b = b
self.lamb = lamb
self.alpha = alpha
self.a = a
def Sigmoid(self):
y = np.exp(self.x) / (np.exp(self.x) + 1)
y_grad = y*(1-y)
return [y, y_grad]
def Hard_Sigmoid(self):
f = (2 * self.x + 5) / 10
y = np.where(np.where(f > 1, 1, f) < 0, 0, np.where(f > 1, 1, f))
y_grad = np.where(f > 0, np.where(f >= 1, 0, 1 / 5), 0)
return [y, y_grad]
def Tanh(self):
y = np.tanh(self.x)
y_grad = 1 - y * y
return [y, y_grad]
def ReLU(self):
y = np.where(self.x < 0, 0, self.x)
y_grad = np.where(self.x < 0, 0, 1)
return [y, y_grad]
def ReLU6(self):
y = np.where(np.where(self.x < 0, 0, self.x) > 6, 6, np.where(self.x < 0, 0, self.x))
y_grad = np.where(self.x > 6, 0, np.where(self.x < 0, 0, 1))
return [y, y_grad]
def LeakyReLU(self): # a大于1,指定a
y = np.where(self.x < 0, self.x / self.a, self.x)
y_grad = np.where(self.x < 0, 1 / self.a, 1)
return [y, y_grad]
def PReLU(self): # a大于1,指定a
y = np.where(self.x < 0, self.x / self.a, self.x)
y_grad = np.where(self.x < 0, 1 / self.a, 1)
return [y, y_grad]
def ELU(self): # alpha是个常数,指定alpha
y = np.where(self.x > 0, self.x, self.alpha * (np.exp(self.x) - 1))
y_grad = np.where(self.x > 0, 1, self.alpha * np.exp(self.x))
return [y, y_grad]
def SELU(self): # lamb大于1,指定lamb和alpha
y = np.where(self.x > 0, self.lamb * self.x, self.lamb * self.alpha * (np.exp(self.x) - 1))
y_grad = np.where(self.x > 0, self.lamb * 1, self.lamb * self.alpha * np.exp(self.x))
return [y, y_grad]
def Swish(self): # b是一个常数,指定b
y = self.x * (np.exp(self.b*self.x) / (np.exp(self.b*self.x) + 1))
y_grad = np.exp(self.b*self.x)/(1+np.exp(self.b*self.x)) + self.x * (self.b*np.exp(self.b*self.x) / ((1+np.exp(self.b*self.x))*(1+np.exp(self.b*self.x))))
return [y, y_grad]
def Hard_Swish(self):
f = self.x + 3
relu6 = np.where(np.where(f < 0, 0, f) > 6, 6, np.where(f < 0, 0, f))
relu6_grad = np.where(f > 6, 0, np.where(f < 0, 0, 1))
y = self.x * relu6 / 6
y_grad = relu6 / 6 + self.x * relu6_grad / 6
return [y, y_grad]
def Mish(self):
f = 1 + np.exp(x)
y = self.x * ((f*f-1) / (f*f+1))
y_grad = (f*f-1) / (f*f+1) + self.x*(4*f*(f-1)) / ((f*f+1)*(f*f+1))
return [y, y_grad]
def PlotActiFunc(x, y, title):
plt.grid(which='minor', alpha=0.2)
plt.grid(which='major', alpha=0.5)
plt.plot(x, y)
plt.title(title)
plt.show()
def PlotMultiFunc(x, y):
plt.grid(which='minor', alpha=0.2)
plt.grid(which='major', alpha=0.5)
plt.plot(x, y)
if __name__ == '__main__':
x = np.arange(-10, 10, 0.01)
activateFunc = ActivateFunc(x)
activateFunc.a = 100
activateFunc.b= 1
activateFunc.alpha = 1.5
activateFunc.lamb = 2
plt.figure(1)
PlotMultiFunc(x, activateFunc.Sigmoid()[0])
PlotMultiFunc(x, activateFunc.Hard_Sigmoid()[0])
PlotMultiFunc(x, activateFunc.Tanh()[0])
PlotMultiFunc(x, activateFunc.ReLU()[0])
PlotMultiFunc(x, activateFunc.ReLU6()[0])
PlotMultiFunc(x, activateFunc.LeakyReLU()[0])
PlotMultiFunc(x, activateFunc.ELU()[0])
PlotMultiFunc(x, activateFunc.SELU()[0])
PlotMultiFunc(x, activateFunc.Swish()[0])
PlotMultiFunc(x, activateFunc.Hard_Swish()[0])
PlotMultiFunc(x, activateFunc.Mish()[0])
plt.legend(['Sigmoid', 'Hard_Sigmoid', 'Tanh', 'ReLU', 'ReLU6', 'LeakyReLU',
'ELU', 'SELU', 'Swish', 'Hard_Swish', 'Mish'])
plt.show()
四、结果显示

Reference
https://arxiv.org/pdf/1908.08681.pdf
到此这篇关于YOLO v4常见的非线性激活函数详解的文章就介绍到这了,更多相关YOLO v4激活函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
解决pytorch-yolov3 train 报错的问题
UserWarning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool instead https://github.com/eriklindernoren/PyTorch-YOLOv3/blob/master/models.py#L191 将model.py obj_mask转为int8 bool obj_mask=obj_mask.bool() # convert int8
-
对YOLOv3模型调用时候的python接口详解
需要注意的是:更改完源程序.c文件,需要对整个项目重新编译.make install,对已经生成的文件进行更新,类似于之前VS中在一个类中增加新函数重新编译封装dll,而python接口的调用主要使用的是libdarknet.so文件,其余在配置文件中的修改不必重新进行编译安装. 之前训练好的模型,在模型调用的时候,总是在 lib = CDLL("/home/*****/*******/darknet/libdarknet.so", RTLD_GLOBAL)这里读不到darknet编译
-

详解使用CUDA+OpenCV加速yolo v4性能
YOLO是You-Only-Look-Once的缩写,它无疑是根据COCO数据集训练的最好的对象检测器之一.YOLOv4是最新的迭代版本,它在准确性和性能之间进行了权衡,使其成为最先进的对象检测器之一.在智能视频分析管道中使用任何对象检测器的典型机制包括使用像Tensorflow或PyTorch这样能够在NVIDIA GPU上操作的库来加速模型推理. OpenCV用于图像/视频流输入,预处理和后处理的视觉效果.如果我告诉你OpenCV现在能够利用NVIDIA CUDA的优点,使用DNN模块本地运
-
Python+树莓派+YOLO打造一款人工智能照相机
不久之前,亚马逊刚刚推出了DeepLens.这是一款专门面向开发人员的全球首个支持深度学习的摄像机,它所使用的机器学习算法不仅可以检测物体活动和面部表情,而且还可以检测类似弹吉他等复杂的活动.虽然DeepLens还未正式上市,但智能摄像机的概念已经诞生了. 今天,我们将自己动手打造出一款基于深度学习的照相机,当小鸟出现在摄像头画面中时,它将能检测到小鸟并自动进行拍照.最终成品所拍摄的画面如下所示: 相机不傻,它可以很机智 我们不打算将一个深度学习模块整合到相机中,相反,我们准备将树莓派"挂钩&q
-
使用pyqt5搭建yolo3目标识别界面的方法
由于这是我第一次写这种博客,其目的也不是为了赚取积分,主要是为了记录我的学习过程中的一些方法,以便以后我再次需要用的时候可以知道我当时是怎么做的.所以文中会有很多地方并不会解释其原理(主要是我自己压根也没搞明白,当时只想知道怎么用就行了,遇到需要用其他的再百度),主要着重于怎么运用.如有不当之处,请指出我当改正. 搭建pyqt5环境 我用的IDE是PyCharm,深度学习环境搭建可以参考其他博主的教程. pyqt5的环境搭建流程参考的是b站up主@刘金玉编程. 安装Anaconda3,搭建好虚拟
-
YOLO v4常见的非线性激活函数详解
YOLO v4中用到的激活函数是Mish激活函数 在YOLO v4中被提及的激活函数有: ReLU, Leaky ReLU, PReLU, ReLU6, SELU, Swish, Mish 其中Leaky ReLU, PReLU难以训练,ReLU6转为量化网络设计 激活函数使用过程图: 一.饱和激活函数 1.1.Sigmoid 函数表达式: Sigmoid函数图像及其导数图像: 优点: 是一个便于求导的平滑函数: 能压缩数据,使输出保证在 [ 0 , 1 ] [0,1] [0,1]之间(相当于对
-
pytorch常见的Tensor类型详解
Tensor有不同的数据类型,每种类型分别有对应CPU和GPU版本(HalfTensor除外).默认的Tensor是FloatTensor,可通过torch.set_default_tensor_type修改默认tensor类型(如果默认类型为GPU tensor,则所有操作都将在GPU上进行). Tensor的类型对分析内存占用很有帮助,例如,一个size为(1000,1000,1000)的FloatTensor,它有1000*1000*1000=10^9个元素,每一个元素占用32bit/8=
-
Java for循环常见优化方法案例详解
目录 方法一:最常规的不加思考的写法 方法二:数组长度提取出来 方法三:数组长度提取出来 方法四:采用倒序的写法 方法五:Iterator 遍历 方法六:jdk1.5后的写法 方法七:循环嵌套外小内大原则 方法八:循环嵌套提取不需要循环的逻辑 方法九:异常处理写在循环外面 前言 我们都经常使用一些循环耗时计算的操作,特别是for循环,它是一种重复计算的操作,如果处理不好,耗时就比较大,如果处理书写得当将大大提高效率,下面总结几条for循环的常见优化方式. 首先,我们初始化一个集合 list,如下
-
Python图像运算之图像灰度非线性变换详解
目录 一.图像灰度非线性变换 二.图像灰度对数变换 三.图像灰度伽玛变换 四.总结 一.图像灰度非线性变换 原始图像的灰度值按照DB=DA×DA/255的公式进行非线性变换,其代码如下: # -*- coding: utf-8 -*- # By:Eastmount import cv2 import numpy as np import matplotlib.pyplot as plt #读取原始图像 img = cv2.imread('luo.png') #图像灰度转换 grayImage =
-
Python+NumPy绘制常见曲线的方法详解
目录 一.利萨茹曲线 二.计算斐波那契数列 三.方波 四.锯齿波和三角波 在NumPy中,所有的标准三角函数如sin.cos.tan等均有对应的通用函数. 一.利萨茹曲线 (Lissajous curve)利萨茹曲线是一种很有趣的使用三角函数的方式(示波器上显示出利萨茹曲线).利萨茹曲线由以下参数方程定义: x = A sin(at + n/2) y = B sin(bt) 利萨茹曲线的参数包括 A . B . a 和 b .为简单起见,我们令 A 和 B 均为1,设置的参数为 a=9 , b=
-
C语言中文件常见操作的示例详解
目录 文件打开和关闭 文件写入 文件读取 fseek函数 ftell函数 Demo示例 解决读取乱码 FILE为C语言提供的文件类型,它是一个结构体类型,用于存放文件的相关信息.文件打开成功时,对它作了内存分配和初始化. 每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,使用者不必关心细节. 一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便. 文件打开和关闭 C语言的安全文件打开函数为_wfopen_s和_fopen_s
-
docker-compose常见的参数命令详解
目录 1. Docker Compose 产生背景 2. Docker Compose模板文件 1.environment 2.volumes 3.build 4.depends_on 5.env_file 6.networks 7.ports 8.expose 9.restart 3. docker-compose指令 1.up -d(后台启动) 2.down 3.exec 4.ps 5.top 6.logs -f(实时) 总结 1. Docker Compose 产生背景 Compose 项
-
Android常见控件使用详解
本文实例为大家分享了六种Android常见控件的使用方法,供大家参考,具体内容如下 1.TextView 主要用于界面上显示一段文本信息 2.Button 用于和用户交互的一个按钮控件 //为Button点击事件注册一个监听器 public class Click extends Activity{ private Button button; @Override ptotected void onCreate(Bundle savedInstanceState) { super.onCreat
-
Android ListView常见的优化方式详解
ListView的优化 对于ListView来说,应该算是布局中几种最常用的组件之一了,使用也十分方便,下面个大家介绍一下两种常见的优化方式. 1.条目复用优化 其实listview的工作原理就是,listview在请求屏幕可见的item数时,convertView在getVIew中是null 的. 但是当屏幕向下滑动的时候(比如该屏幕尺寸可显示7条teim),在item1被隐藏,此时出现item8时,covertView的值就不为null 了,因为item1去填充它. 而如果不做复用处理的话,
-
Go语言中一些不常见的命令参数详解
前言 这篇文章可能会有些偏见.这篇文章描述了个人会用到的Go工具参数,还有一些是我周围的人遇到的问题.如果有问题大家可以留言,你是刚开始使用Go工具么?或者你想扩展知识?这篇文章将会描述每个人都需要知道的Go工具参数.下面话不多说了,来一看看详细的介绍吧. $ go build -x -x会列出来go build调用到的所有命令. 如果你对Go的工具链好奇,或者使用了一个跨C编译器,并且想知道调用外部编译器用到的具体参数,或者怀疑链接器有bug:使用-x来查看所有调用. $ go build -