java的多线程高并发详解
1.JMM数据原子操作
- read(读取)∶从主内存读取数据
- load(载入):将主内存读取到的数据写入工作内存
- use(使用):从工作内存读取数据来计算
- assign(赋值):将计算好的值重新赋值到工作内存中
- store(存储):将工作内存数据写入主内存
- write(写入):将store过去的变量值赋值给主内存中的变量
- lock(锁定):将主内存变量加锁,标识为线程独占状态
- unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定该变量
2.来看volatile关键字
(1)启动两个线程
public class VolatileDemo {
private static boolean flag = false;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (!flag){
}
System.out.println("跳出while循环了");
}).start();
Thread.sleep(2000);
new Thread(() -> changeFlage()).start();
}
private static void changeFlage() {
System.out.println("开始改变flag值之前");
flag = true;
System.out.println("改变flag值之后");
}
}
没加volatile之前,第一个线程的while判断一直满足

(2)给变量flag加了volatile之后
public class VolatileDemo {
private static volatile boolean flag = false;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
while (!flag){
}
System.out.println("跳出while循环了");
}).start();
Thread.sleep(2000);
new Thread(() -> changeFlage()).start();
}
private static void changeFlage() {
System.out.println("开始改变flag值之前");
flag = true;
System.out.println("改变flag值之后");
}
}
while语句能够满足条件

(3)原理解释:
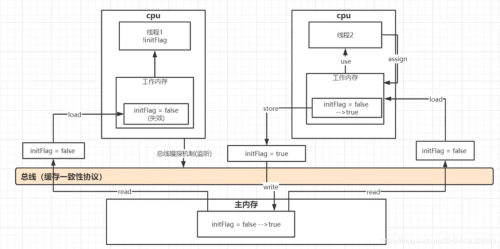
开启第一个线程时,flag变量通过read从主内存中读出数据,使用load把数据加载进线程一的工作内存,通过use把flag读取到线程中;线程二也是同样的读取操作。线程二通过assign改变了flag的值,线程二工作内存中存储的flag=true,再通过store把flag写入到总线,总线再把flag通过write写入到住内存;由于两个线程读取操作的都是各种工作内存中的值,是主内存的副本,相互不通信,所以线程一一直再循环,线程一的flag为false。
加了volatile后,添加了缓存一致性协议(MESI),CPU通过总线嗅探机制感知到数据的变化而自己缓存里的值失效,此时线程一会把工作内存中存放的flag失效,从主内存中重新读取flag的值,此时满足while条件。
volatile底层通过汇编语言的lock修饰,当变量有修改立马写回主类,避免指令重排序
3.并发编程三大特性
可见性,有序性、原子性
4.双锁判断机制创建单例模式
public class DoubleCheckLockSinglenon {
private static volatile DoubleCheckLockSinglenon doubleCheckLockSingleon = null;
public DoubleCheckLockSinglenon(){}
public static DoubleCheckLockSinglenon getInstance(){
if (null == doubleCheckLockSingleon) {
synchronized(DoubleCheckLockSinglenon.class){
if(null == doubleCheckLockSingleon){
doubleCheckLockSingleon = new DoubleCheckLockSinglenon();
}
}
}
return doubleCheckLockSingleon;
}
public static void main(String[] args) {
System.out.println(DoubleCheckLockSinglenon.getInstance());
}
}
当线程调用getInstance方法创建的时候,先判断是否为空,为空则把对象加上锁,否则多线程的情况会创建重复,再锁里面再次判断是否为空,当new一个对象的时候,先在内存分配空间,再执行对象的init属性赋零操作,再执行初始化赋值操作。
cpu为了优化代码执行效率,会对满足as-if-serial和happens-before原则的代码进行指令重排序,as-if-serial规定线程内的执行代码顺序不影响结果输出,则会进行指令重排;
happens-before规定一些锁的顺序,同一个对象的unlock需要出现下一个lock之前等。
所以为了防止new的时候,指令重排,先进行赋值再执行赋零操作情况,需要加上volatile修饰符,加上volatile修饰后,在new操作时会创建内存屏障,高速cpu不进行指令重排序,底层是lock关键字;内存屏障分为LoadLoad(读读)、storestore(写写)、loadstore(读写)、storeload(写读),底层是c++代码写的,c++代码再调用汇编语言
5.synchronized关键字
(1)没加synchronized之前
package com.qingyun;
/**
* Synchronized关键字
*/
public class SynchronizedDemo {
public static void main(String[] args) throws InterruptedException {
Num num = new Num();
Thread t1 = new Thread(() -> {
for (int i = 0;i < 100000;i++) {
num.incrent();
}
});
t1.start();
for (int i = 0;i < 100000;i++) {
num.incrent();
}
t1.join();
System.out.println(num.getNum());
}
}
package com.qingyun;
public class Num {
public int num = 0;
public void incrent() {
num++;
}
public int getNum(){
return num;
}
}
输出结果不是我们想要的,由于线程和for循环同时去调加的方法,导致最后输出的结果不是我们想要的

(2)加上synchronized之后
public synchronized void incrent() {
num++;
}
//或者
public void incrent() {
synchronized(this){
num++;
}
}

输出的结果是我们想要的,synchronized关键字底层使用的lock,是重量级锁,互斥锁、悲观锁,jdk1.6之前的锁,线程会放到一个队列里面等待着执行
6.AtomicIntger原子操作
(1)给原子加1的操作,可以使用AtomicInteger实现,与synchronized相比,性能大大提升
public class Num {
// public int num = 0;
AtomicInteger atomicInteger = new AtomicInteger();
public void incrent() {
atomicInteger.incrementAndGet(); //原子加1
}
public int getNum(){
return atomicInteger.get();
}
}
AtomicInteger源码有一个value字段,使用volatile修饰,volatile底层使用lock修饰,保证多线程并发结果的正确
private volatile int value;
(2)atomicInteger.incrementAndGet()方法做的事情:先获取到value的值,给值加1,再使用旧的值和atomicInteger进行比较,相等了把newValue设置进去,由于使用多线程可能值会不相等的情况,所以使用while进行循环比对,相等了执行完才推出
while(true) {
int oldValue = atomicInteger.get();
int newValue = oldValue+1;
if(atomicInteger.compareAndSet(oldValue,newValue)){
break;
}
}
(3)atomicInteger.compareAndSet比对完值后才设置新值的方式即为CAS:无锁、乐观锁、轻量级锁,synchroznied存在线程阻塞、上行文切换、操作系统调度比较费时;CAS一直循环比对执行,效率要高
(4)compareAndSetInt底层使用native修饰,底层是c++代码,实现了原子性问题,在汇编语言使用代码lock cmpxchqq保证了原子性,是缓存行锁
(5)ABA问题:线程一那到一个变量,线程二执行比较快,也拿到这个变量,把变量的值进行修改,再快速修改回原来的值,这样变量的值有过一次变化,线程一再去执行compareAndSet的时候,虽然值还是之前的没变,但是已经发生过变化了,出现ABA问题
(6)解决ABA问题就是给变量加版本,每次操作变量版本加1,JDK带版本的锁有AtomicStampedReference,这样就算变量被其它线程修改过再回复原值,版本号也是不一致的。
7.锁优化
(1)重量级锁会把等待的线程放到队列中,重量级锁锁定的是monitor,存在上下问切换的资源占用;轻量级锁若是线程太多,会存在自旋,耗费cpu
(2)jdk1.6之后,锁升级为无状态-》偏向锁(锁id指定)-》轻量级锁(自旋膨胀)-》重量级锁(队列存储)
(3)创建一个对象,此时对象为无状态,当启动了一个线程时,再创建一个对象时,启用偏向锁,偏向锁执行完之后不会释放锁;当再启用一个线程时,有两个线程来挣抢对象时,立马又偏向锁升级为轻量级锁;当再创建一个线程的来挣抢对象锁时,由轻量级锁升级为重量级锁
(4)分段CAS,底层有一个base记录变量值,当有多个线程类访问此变量是,base的值会分为多个cell,组成数组,每个cell对应一到多个线程的cas处理,避免了线程的自旋空转,这样还是轻量级锁,返回数据的时候,底层调用的是所有cell数组和base的加和
public class Num {
LongAdder longAdder = new LongAdder();
public void incrent() {
longAdder.increment();
}
public long getNum(){
return longAdder.longValue();
}
}
public long longValue() {
return sum();
}
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
到此这篇关于java的多线程与高并发详解的文章就介绍到这了,更多相关java多线程与高并发内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Java内部类——匿名内部类
今天来看看另一个更加神奇的类--匿名内部类. 就像它的名字表示的那样,这个类是匿名的,用完之后,深藏功与名,就像扫地僧那样默默潜藏于深山之中.匿名内部类不仅没有名字,连class关键字都省掉了,而且匿名内部类必须继承于某个类或者实现某个接口,长的就像这样: new 父类(参数列表)|实现接口() { //匿名内部类的内部定义 } 来看一个栗子: public abstract class Human { public abstract void walk(); } 这是一个抽象类,如果使用匿名内
-
简述JAVA同步、异步、阻塞和非阻塞之间的区别
同步和异步,阻塞和非阻塞是大家经常会听到的概念,但是它们是从不同维度来描述一件事情,常常很容易混为一谈. 1. 同步和异步 同步和异步描述的是消息通信的机制. 同步 当一个request发送出去以后,会得到一个response,这整个过程就是一个同步调用的过程.哪怕response为空,或者response的返回特别快,但是针对这一次请求而言就是一个同步的调用. 异步 当一个request发送出去以后,没有得到想要的response,而是通过后面的callback.状态或者通知的方式获得结果.可
-
Java内部类和匿名内部类的用法说明
一.内部类: (1)内部类的同名方法 内部类可以调用外部类的方法,如果内部类有同名方法必须使用"OuterClass.this.MethodName()"格式调用(其中OuterClass与MethodName换成实际外部类名及其方法:this为关键字,表示对外部类的引用):若内部类无同名方法可以直接调用外部类的方法. 但外围类无法直接调用内部类的private方法,外部类同样无法直接调用其它类的private方法.注意:内部类直接使用外部类的方法与该方法的权限与是否static无关,
-
JAVA匿名内部类语法分析及实例详解
1.前言 匿名内部类在我们JAVA程序员的日常工作中经常要用到,但是很多时候也只是照本宣科地用,虽然也在用,但往往忽略了以下几点:为什么能这么用?匿名内部类的语法是怎样的?有哪些限制?因此,最近,我在完成了手头的开发任务后,查阅了一下JAVA官方文档,将匿名内部类的使用进行了一下总结,案例也摘自官方文档.感兴趣的可以查阅官方文档(https://docs.oracle.com/javase/tutorial/java/javaOO/anonymousclasses.html). 2.匿名内部类
-
Java匿名类,匿名内部类实例分析
本文实例讲述了Java匿名类,匿名内部类.分享给大家供大家参考,具体如下: 本文内容: 内部类 匿名类 首发日期 :2018-03-25 内部类: 在一个类中定义另一个类,这样定义的类称为内部类.[包含内部类的类可以称为内部类的外部类] 如果想要通过一个类来使用另一个类,可以定义为内部类.[比如苹果手机类,苹果手机类中的黄金版的是特别定制的] 内部类的外部类的成员变量在内部类中仍然有效,内部类中的方法也可以调用外部类中的方法.[不论是静态还是非静态的,内部类都可以直接调用外部类中的属性,] 内部
-

JAVA序列化和反序列化的底层实现原理解析
一.基本概念 1.什么是序列化和反序列化 (1)Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程: (2)**序列化:**对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性.序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中.序列化后的字节流保存了Java对象的状态以及相关的描述信息.序列化机制的核心作用就是对象状态的保存与重建. (3)**反序列化:**客户端从文件中或网络上获得序列化后
-
Java实现线程同步方法及原理详解
一.概述 无论是什么语言,在多线程编程中,常常会遇到多个线同时操作程某个变量(读/写),如果读/写不同步,则会造成不符合预期的结果. 例如:线程A和线程B并发运行,都操作变量X,若线程A对变量X进行赋上一个新值,线程B仍然使用变量X之前的值,很明显线程B使用的X不是我们想要的值了. Java提供了三种机制,解决上述问题,实现线程同步: 同步代码块 synchronized(锁对象){ // 这里添加受保护的数据操作 } 同步方法 静态同步方法:synchronized修饰的静态方法,它的同步锁是
-
java多线程CountDownLatch与线程池ThreadPoolExecutor/ExecutorService案例
1.CountDownLatch: 一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行. 2.ThreadPoolExecutor/ExecutorService: 线程池,使用线程池可以复用线程,降低频繁创建线程造成的性能消耗,同时对线程的创建.启动.停止.销毁等操作更简便. 3.使用场景举例: 年末公司组织团建,要求每一位员工周六上午8点到公司门口集合,统一乘坐公司所租大巴前往目的地. 在这个案例中,公司作为主线程,员工作为子线程. 4.代码示例: package
-
Java原生序列化和反序列化代码实例
这篇文章主要介绍了Java原生序列化和反序列化代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 写一个Java原生的序列化和反序列化的DEMO. 需序列化的类: package com.nicchagil.nativeserialize; import java.io.Serializable; public class User implements Serializable { private static final long se
-
java多线程CyclicBarrier的使用案例,让线程起步走
1.CyclicBarrier: 一个同步辅助类,用于协调多个子线程,让多个子线程在这个屏障前等待,直到所有子线程都到达了这个屏障时,再一起继续执行后面的动作. 2.使用场景举例: 年末公司组织团建,要求每一位员工周六上午8点[自驾车]到公司门口集合,然后[自驾车]前往目的地. 在这个案例中,公司作为主线程,员工作为子线程. 3.代码示例: package com.test.spring.support; import java.util.concurrent.BrokenBarrierExce
-
Java多线程下载网图的完整案例
Java多线程下载网图案例 此案例依赖--文件操作工具类(FileUtils) 使用 apache 的commons-io包下的FileUtilsimportorg.apache.commons.io.FileUtils; 下载commons-io包 官方API文档 点击即可下载,然后导入IDEA的库中或者项目中. 导包 首先创建一个下载器 步骤: 1.新建一个download类 2.在类中建立一个下载方法 下载方法需要接收2个变量,一个是url下载地址,一个是name文件名称 3.在下载方法中
-
java对象序列化与反序列化原理解析
这篇文章主要介绍了java对象序列化与反序列化原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.序列化和反序列化的概念 对象转换为字节序列的过程称为对象的序列化.把字节序列恢复为对象的过程称为对象的反序列化. 二.序列化和反序列化的作用 对象的序列化主要有两种用途: 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中. 在网络上传送对象的字节序列.网络上传输的都是二进制序列. 在很多应用中,需要对某些对象进行序列化,让它们离开内
-
Java中难理解的四个概念
前言 Java 是很多人一直在用的编程语言,但是有些 Java 概念是非常难以理解的,哪怕是一些多年的老手,对某些 Java 概念也存在一些混淆和困惑. 所以,在这篇文章里,会介绍四个 Java 中最难理解的四个概念,去帮助开发者更清晰的理解这些概念: 匿名内部类的用法 多线程 如何实现同步 序列化 匿名内部类 匿名内部类又叫匿名类,它有点像局部类(Local Class)或者内部类(Inner Class),只是匿名内部类没有名字,我们可以同时声明并实例化一个匿名内部类. 一个匿名内部类仅适用
-
java 定时同步数据的任务优化
前言 定时任务在系统中并不少见,主要目的是用于需要定时处理数据或者执行某个操作的情况下,如定时关闭订单,或者定时备份.而常见的定时任务分为2种,第一种:固定时间执行,如:每分钟执行一次,每天执行一次.第二种:延时多久执行,就是当发生一件事情后,根据这件时间发生的时间定时多久后执行任务,如:15分钟后关闭订单付款状态,24小时候后关闭订单并且释放库存,而由于第二种一般都是单一数据的处理(主要是指数据量不大,一般情况下只有一个主体处理对象,如:一个订单以及订单中的N个商品),所以一般情况下第二种出现