Python 网络爬虫--关于简单的模拟登录实例讲解
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号、密码等等。
模拟登录一个网站大致分为这么几步:
1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存)
2.将信息进行提交
3.获取登录后的信息
先给上源码
<span style="font-size: 14px;"># -*- coding: utf-8 -*-
import requests
def login():
session = requests.session()
# res = session.get('http://my.its.csu.edu.cn/').content
login_data = {
'userName': '3903150327',
'passWord': '136510',
'enter': 'true'
}
session.post('http://my.its.csu.edu.cn//', data=login_data)
res = session.get('http://my.its.csu.edu.cn/Home/Default')
print(res.text)
login()</span>
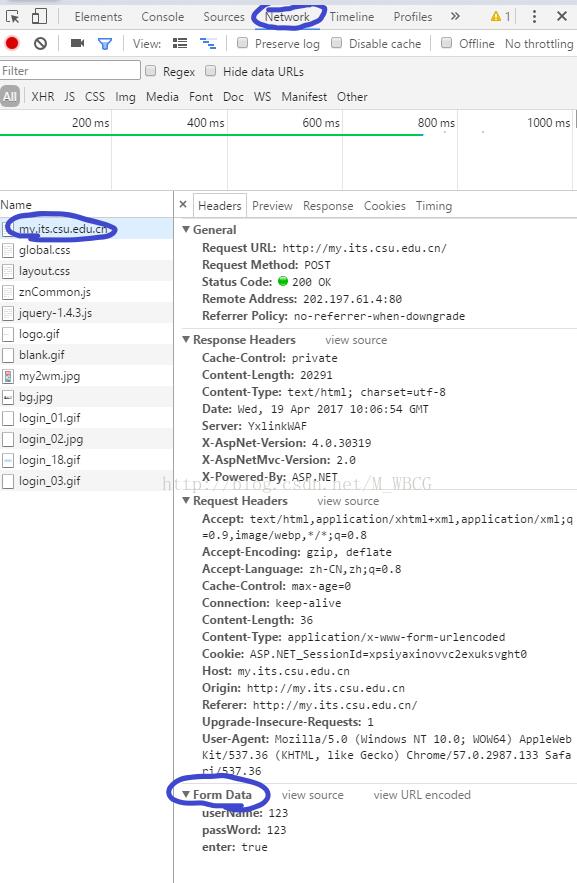
一、筛选得到隐藏信息
进入开发者工具(按F12),找到其中的Network后,手动的先进行一次登录,找到其中的第一个请求,在Header的底部会有一个data的数据段,这个就是登录所需的信息。如果想对其中的隐藏信息进行修改
先获取网页Html的内容
res = session.get('http://my.its.csu.edu.cn/').content
再通过正则表达式筛选内容
二、将信息进行提交
找到源码中提交表单所需要的action,和method
使用
session.post('http://my.its.csu.edu.cn/(这里就是提交的action)', data=login_data)
该方法提交信息
三、获取登录后的信息
信息提交后模拟登录就成功了
接下来就可以获取登录后的信息了
res = session.get('http://my.its.csu.edu.cn/Home/Default').content
以上这篇Python 网络爬虫--关于简单的模拟登录实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python实现爬虫从网络上下载文档的实例代码
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下: Spider_main.py # coding:utf8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __ini
-

Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
Python爬虫之网页图片抓取的方法
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url): ''' 打开网页 :param url: :return: ''' req = urllib.reques
-
Python爬取成语接龙类网站
介绍 本文将展示如何利用Python爬虫来实现诗歌接龙. 该项目的思路如下: 利用爬虫爬取诗歌,制作诗歌语料库: 将诗歌分句,形成字典:键(key)为该句首字的拼音,值(value)为该拼音对应的诗句,并将字典保存为pickle文件: 读取pickle文件,编写程序,以exe文件形式运行该程序. 该项目实现的诗歌接龙,规则为下一句的首字与上一句的尾字的拼音(包括声调)一致.下面将分步讲述该项目的实现过程. 诗歌语料库 首先,我们利用Python爬虫来爬取诗歌,制作语料库.爬取的网址为:https
-
python爬虫_实现校园网自动重连脚本的教程
一.背景 最近学校校园网不知道是什么情况,总出现掉线的情况.每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录.系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网.每次掉线后,再打开任意网页就是这个页面. 二.实现代码 #-*- coding:utf-8 -*- __author__ = 'pf' import time import requests class Login: #初始化 def __init__(self): #检测间隔时间,单位
-
python2.7实现爬虫网页数据
最近刚学习Python,做了个简单的爬虫,作为一个简单的demo希望帮助和我一样的初学者. 代码使用python2.7做的爬虫 抓取51job上面的职位名,公司名,薪资,发布时间等等. 直接上代码,代码中注释还算比较清楚 ,没有安装mysql需要屏蔽掉相关代码: #!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs im
-
解决Python网页爬虫之中文乱码问题
Python是个好工具,但是也有其固有的一些缺点.最近在学习网页爬虫时就遇到了这样一种问题,中文网站爬取下来的内容往往中文显示乱码.看过我之前博客的同学可能知道,之前爬取的一个学校网页就出现了这个问题,但是当时并没有解决,这着实成了我一个心病.这不,刚刚一解决就将这个方法公布与众,大家一同分享. 首先,我说一下Python中文乱码的原因,Python中文乱码是由于Python在解析网页时默认用Unicode去解析,而大多数网站是utf-8格式的,并且解析出来之后,python竟然再以Unicod
-
python爬虫 使用真实浏览器打开网页的两种方法总结
1.使用系统自带库 os 这种方法的优点是,任何浏览器都能够使用, 缺点不能自如的打开一个又一个的网页 import os os.system('"C:/Program Files/Internet Explorer/iexplore.exe" http://www.baidu.com') 2.使用python 集成的库 webbroswer python的webbrowser模块支持对浏览器进行一些操作,主要有以下三个方法: import webbrowser webbrowser.
-
Python 网络爬虫--关于简单的模拟登录实例讲解
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号.密码等等. 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存) 2.将信息进行提交 3.获取登录后的信息 先给上源码 <span style="font-size: 14px;"># -*- coding: utf-8 -*- import requests def login(): sessi
-
python网络爬虫之模拟登录 自动获取cookie值 验证码识别的具体实现
目录 1.爬取网页分析 2.验证码识别 3.cookie自动获取 4.程序源代码 chaojiying.py sign in.py 1.爬取网页分析 爬取的目标网址为:https://www.gushiwen.cn/ 在登陆界面需要做的工作有,获取验证码图片,并识别该验证码,才能实现登录. 使用浏览器抓包工具可以看到,登陆界面请求头包括cookie和user-agent,故在发送请求时需要这两个数据.其中user-agent可通过手动添加到请求头中,而cookie值需要自动获取. 分析完毕,实践
-
python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作.分享给大家供大家参考,具体如下: 一.背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验
-
Python网络爬虫实例讲解
聊一聊Python与网络爬虫. 1.爬虫的定义 爬虫:自动抓取互联网数据的程序. 2.爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出. 3.爬虫的时序图 4.URL管理器 URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取.URL管理器的主要职能如下图
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1)热搜的名字都在<td class="td-02">的子节点<a>里 (2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是
-
python网络爬虫实现发送短信验证码的方法
前言:今天要总结的是如何用程序来实现短信发送功能.但是呢,可能需要我们调用一些api接口,我会详细介绍.都是自己学到的,害怕忘记,所以要总结一下,让写博客成为一种坚持的信仰.废话不多说,我们开始吧! 网络爬虫实现发送短信验证码 在实现我们目标的功能之前,我们要有自己的思路,否则你没有方向,又如何实现自己的代码功能呢? 我们要发送短信,那么我们其实是需要分析的.我们可以去分析一个可以发送短信的网站页面. 我们来到这里如下: 可以看到这是一个注册界面,我们在注册时会被要求需要填写手机号码的·,其实还
-
利用Python网络爬虫爬取各大音乐评论的代码
python爬虫--爬取网易云音乐评论 方1:使用selenium模块,简单粗暴.但是虽然方便但是缺点也是很明显,运行慢等等等. 方2:常规思路:直接去请求服务器 1.简易看出评论是动态加载的,一定是ajax方式. 2.通过网络抓包,可以找出评论请求的的URL 得到请求的URL 3.去查看post请求所上传的数据 显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密. 4.首先去查看请求是经过那些js到达服务器的 5.设置断点:依次对所发送的内容进行观察,找到评论对应的UR
-
python网络爬虫实战
目录 一.概述 二.原理 三.爬虫分类 1.传统爬虫 2.聚焦爬虫 3.通用网络爬虫(全网爬虫) 四.网页抓取策略 1.宽度优先搜索: 2.深度优先搜索: 3.最佳优先搜索: 4.反向链接数策略: 5.Partial PageRank策略: 五.网页抓取的方法 1.分布式爬虫 现在比较流行的分布式爬虫: 2.Java爬虫 3.非Java爬虫 六.项目实战 1.抓取指定网页 抓取某网首页 2.抓取包含关键词网页 3.下载贴吧中图片 4.股票数据抓取 六.结语 一.概述 网络爬虫(Web crawl
-
详解Python网络爬虫功能的基本写法
网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛. 1. 网络爬虫的定义 网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止.如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来.这样看来,网络爬虫就是一个爬行程序,一个抓取网页的