pandas.DataFrame.iloc的具体使用详解
目录
- 第一种 整数做索引
- 第二种 列表或数组做索引
- 第三种 利用切片做索引
- 第四种 Boolean数组做索引
- 第五种 带一个参数的可调用函数做索引
今天学习时遇到了这个方法,为了加深理解做一下笔记。

这是该方法的文档,从中可以看出,中括号里允许输入可情形有5种。
此外,iloc方法既可以索引行数据,也可以列数据。
//首先创建DataFrame
import pandas as pd
import numpy as np
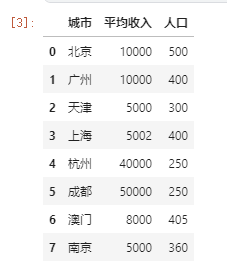
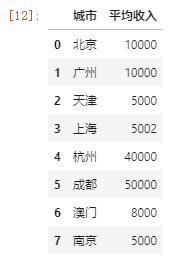
df = pd.DataFrame({'城市':['北京','广州', '天津', '上海', '杭州', '成都', '澳门', '南京'],
'平均收入':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'人口':[500, 400, 300, 400, 250, 250, 405, 360]})
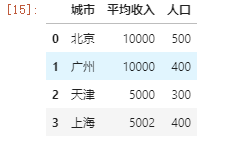
数据如下
第一种 整数做索引
// 索引第2行 df.iloc[1]

// 索引第2行第3列 df.iloc[1,2]
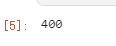
第二种 列表或数组做索引
// 索引2、3两行数据 df.iloc[[1,2]]
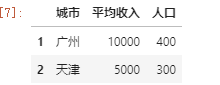
// 索引2、3两行数据的前两列 df.iloc[[1,2],[0,1]]
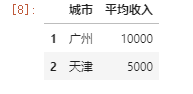
第三种 利用切片做索引
// 索引前5行数据的前两列 df.iloc[0:5,0:2]
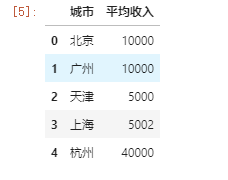
// 和切片原理一样,2是步长 df.iloc[0:8:2]
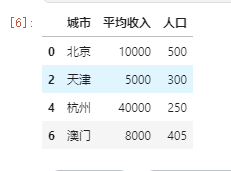
第四种 Boolean数组做索引
// True 为显示,False为不显示 df.iloc[[True, False, True, False, True, False, True, False],[True, False, True]]
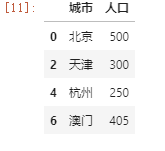
注意:此时Boolean数组的长度需对应df的行列数
此外还可以这样用
df.iloc[:,df.columns!='人口']
第五种 带一个参数的可调用函数做索引
// A code block df.iloc[lambda x: x.index + 2 < 8 ]
到此这篇关于pandas.DataFrame.iloc的具体使用详解的文章就介绍到这了,更多相关pandas.DataFrame.iloc的使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧. 首先,还是列出一个我们用的DataFrame,注意index一列,如下: 接下来,介绍下各个函数的用法: 1.loc函数 愿意看官方文档的,请戳这里,这里一般最权威. loc函数是基于"标签"选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例: 1.1 单个label 接受一个"标签"(
-
python pandas.DataFrame选取、修改数据最好用.loc,.iloc,.ix实现
相信很多人像我一样在学习python,pandas过程中对数据的选取和修改有很大的困惑(也许是深受Matlab)的影响... 到今天终于完全搞清楚了!!! 先手工生出一个数据框吧 import numpy as np import pandas as pd df = pd.DataFrame(np.arange(0,60,2).reshape(10,3),columns=list('abc')) df 是这样子滴 那么这三种选取数据的方式该怎么选择呢? 一.当每列已有column name时,用
-
![详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据](/assets/blank.gif)
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
pandas.DataFrame.iloc的具体使用详解
目录 第一种 整数做索引 第二种 列表或数组做索引 第三种 利用切片做索引 第四种 Boolean数组做索引 第五种 带一个参数的可调用函数做索引 今天学习时遇到了这个方法,为了加深理解做一下笔记. 这是该方法的文档,从中可以看出,中括号里允许输入可情形有5种.此外,iloc方法既可以索引行数据,也可以列数据. //首先创建DataFrame import pandas as pd import numpy as np df = pd.DataFrame({'城市':['北京','广州', '天
-
python sklearn与pandas实现缺失值数据预处理流程详解
注:代码用 jupyter notebook跑的,分割线线上为代码,分割线下为运行结果 1.导入库生成缺失值 通过pandas生成一个6行4列的矩阵,列名分别为'col1','col2','col3','col4',同时增加两个缺失值数据. import numpy as np import pandas as pd from sklearn.impute import SimpleImputer #生成缺失数据 df=pd.DataFrame(np.random.randn(6,4),colu
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
对python pandas 画移动平均线的方法详解
数据文件 66001_.txt 内容格式: date,jz0,jz1,jz2,jz3,jz4,jz5 2012-12-28,0.9326,0.8835,1.0289,1.0027,1.1067,1.0023 2012-12-31,0.9435,0.8945,1.0435,1.0031,1.1229,1.0027 2013-01-04,0.9403,0.8898,1.0385,1.0032,1.1183,1.0030 ... ... pd_roll_mean1.py # -*- coding: u
-
python pandas修改列属性的方法详解
使用astype如下: df[[column]] = df[[column]].astype(type) type即int.float等类型. 示例: import pandas as pd data = pd.DataFrame([[1, "2"], [2, "2"]]) data.columns = ["one", "two"] print(data) # 当前类型 print("----\n修改前类型:&quo
-
对pandas中Series的map函数详解
Series的map方法可以接受一个函数或含有映射关系的字典型对象. 使用map是一种实现元素级转换以及其他数据清理工作的便捷方式. (DataFrame中对应的是applymap()函数,当然DataFrame还有apply()函数) 1.字典映射 import pandas as pd from pandas import Series, DataFrame data = DataFrame({'food':['bacon','pulled pork','bacon','Pastrami',
-
python DataFrame转dict字典过程详解
这篇文章主要介绍了python DataFrame转dict字典过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景:将商品id以及商品类别作为字典的键值映射,生成字典,原为DataFrame # 创建一个DataFrame # 列值类型均为int型 import pandas as pd item = pd.DataFrame({'item_id': [100120, 10024504, 1055460], 'item_categor
-
Pandas时间序列:时期(period)及其算术运算详解
import pandas as pd import numpy as np 一.时间类型及其在python中对应的类型 时间戳–timestamp 时间间隔–timedelta 时期–period 二.时期 时期表示的是时间区间,比如数日.数月.数季.数年等 1.定义一个Period p = pd.Period(2007,freq='A-DEC') #表示以12月作为结束的一整年,这里表示从2007-01-01到2017-12-31的全年 p Period('2007', 'A-DEC') 2
-
Pandas实现数据拼接的操作方法详解
目录 merge 操作 merge 拼接方式 merge 举例 join 操作 join 举例 concat 操作 concat 举例 append 举例 数据科学领域日常使用 Python 处理大规模数据集的时候经常需要使用到合并.链接的方式进行数据集的整合,其中应用的数据类型包括 Series 和 DataFrame,可以使用的方法也很多,比如本文中介绍的 .merge(). .join() 和 .concat() 三种方法,进行拼接处理后的数据集可以发挥最大的用途. merge 操作 .m
-
pandas中pd.groupby()的用法详解
在pandas中的groupby和在sql语句中的groupby有异曲同工之妙,不过也难怪,毕竟关系数据库中的存放数据的结构也是一张大表罢了,与dataframe的形式相似. import numpy as np import pandas as pd from pandas import Series, DataFrame df = pd.read_csv('./city_weather.csv') print(df) ''' date city temperature