压缩Redis里的字符串大对象操作
背景
Redis缓存的字符串过大时会有问题。不超过10KB最好,最大不能超过1MB。
有几个配置缓存,上千个flink任务调用,每个任务5分钟命中一次,大小在5KB到6MB不等,因此需要压缩。
第一种,使用gzip
/**
* 使用gzip压缩字符串
*/
public static String compress(String str) {
if (str == null || str.length() == 0) {
return str;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPOutputStream gzip = null;
try {
gzip = new GZIPOutputStream(out);
gzip.write(str.getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
if (gzip != null) {
try {
gzip.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return new sun.misc.BASE64Encoder().encode(out.toByteArray());
}
/**
* 使用gzip解压缩
*/
public static String uncompress(String compressedStr) {
if (compressedStr == null || compressedStr.length() == 0) {
return compressedStr;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = null;
GZIPInputStream ginzip = null;
byte[] compressed = null;
String decompressed = null;
try {
compressed = new sun.misc.BASE64Decoder().decodeBuffer(compressedStr);
in = new ByteArrayInputStream(compressed);
ginzip = new GZIPInputStream(in);
byte[] buffer = new byte[1024];
int offset = -1;
while ((offset = ginzip.read(buffer)) != -1) {
out.write(buffer, 0, offset);
}
decompressed = out.toString();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (ginzip != null) {
try {
ginzip.close();
} catch (IOException e) {
}
}
if (in != null) {
try {
in.close();
} catch (IOException e) {
}
}
if (out != null) {
try {
out.close();
} catch (IOException e) {
}
}
}
return decompressed;
}
第二种,使用Zstd
<!-- https://mvnrepository.com/artifact/com.github.luben/zstd-jni -->
<dependency>
<groupId>com.github.luben</groupId>
<artifactId>zstd-jni</artifactId>
<version>1.4.5-6</version>
</dependency>
public class ConfigCacheUtil {
private static ZstdDictCompress compressDict;
private static ZstdDictDecompress decompressDict;
private static final Integer LEVEL = 5;
public static void train() throws IOException {
// 初始化词典对象
String dictContent = FileUtils.readFileToString(new File("/Users/yangguang/vscode/text/cache.json"),
StandardCharsets.UTF_8);
byte[] dictBytes = dictContent.getBytes(StandardCharsets.UTF_8);
compressDict = new ZstdDictCompress(dictBytes, LEVEL);
decompressDict = new ZstdDictDecompress(dictBytes);
}
public static void main(String[] args) throws IOException {
String read = FileUtils.readFileToString(new File("/Users/yangguang/vscode/text/cache.json"));
ConfigCacheUtil.testGzip(read);
System.out.println("");
ConfigCacheUtil.test(read.getBytes());
System.out.println("");
ConfigCacheUtil.testByTrain(read.getBytes());
}
public static void testGzip(String str) {
logger.info("初始数据: {}", str.length());
// 压缩数据
long compressBeginTime = System.currentTimeMillis();
String compressed = ConfigCacheUtil.compress(str);
long compressEndTime = System.currentTimeMillis();
logger.info("压缩耗时: {}", compressEndTime - compressBeginTime);
logger.info("数据大小: {}", compressed.length());
// 解压数据
long decompressBeginTime = System.currentTimeMillis();
// 第 3 个参数不能小于解压后的字节数组的大小
String decompressed = ConfigCacheUtil.uncompress(compressed);
long decompressEndTime = System.currentTimeMillis();
logger.info("解压耗时: {}", decompressEndTime - decompressBeginTime);
logger.info("数据大小: {}", decompressed.length());
}
public static void test(byte[] bytes) {
logger.info("初始数据: {}", bytes.length);
// 压缩数据
long compressBeginTime = System.currentTimeMillis();
byte[] compressed = Zstd.compress(bytes);
long compressEndTime = System.currentTimeMillis();
logger.info("压缩耗时: {}", compressEndTime - compressBeginTime);
logger.info("数据大小: {}", compressed.length);
// 解压数据
long decompressBeginTime = System.currentTimeMillis();
// 第 3 个参数不能小于解压后的字节数组的大小
byte[] decompressed = Zstd.decompress(compressed, 20 * 1024 * 1024 * 8);
long decompressEndTime = System.currentTimeMillis();
logger.info("解压耗时: {}", decompressEndTime - decompressBeginTime);
logger.info("数据大小: {}", decompressed.length);
}
public static void testByTrain(byte[] bytes) throws IOException {
ConfigCacheUtil.train();
logger.info("初始数据: {}", bytes.length);
// 压缩数据
long compressBeginTime = System.currentTimeMillis();
byte[] compressed = Zstd.compress(bytes, compressDict);
long compressEndTime = System.currentTimeMillis();
logger.info("压缩耗时: {}", compressEndTime - compressBeginTime);
logger.info("数据大小: {}", compressed.length);
// 解压数据
long decompressBeginTime = System.currentTimeMillis();
// 第 3 个参数不能小于解压后的字节数组的大小
byte[] decompressed = Zstd.decompress(compressed, decompressDict, 20 * 1024 * 1024 * 8);
long decompressEndTime = System.currentTimeMillis();
logger.info("解压耗时: {}", decompressEndTime - decompressBeginTime);
logger.info("数据大小: {}", decompressed.length);
compressDict.toString();
}
}
输出
5KB
2020-09-08 22:42:48 INFO ConfigCacheUtil:157 - 初始数据: 5541
2020-09-08 22:42:48 INFO ConfigCacheUtil:163 - 压缩耗时: 2
2020-09-08 22:42:48 INFO ConfigCacheUtil:164 - 数据大小: 1236
2020-09-08 22:42:48 INFO ConfigCacheUtil:171 - 解压耗时: 2
2020-09-08 22:42:48 INFO ConfigCacheUtil:172 - 数据大小: 55412020-09-08 22:42:48 INFO ConfigCacheUtil:176 - 初始数据: 5541
2020-09-08 22:42:48 INFO ConfigCacheUtil:182 - 压缩耗时: 523
2020-09-08 22:42:48 INFO ConfigCacheUtil:183 - 数据大小: 972
2020-09-08 22:42:48 INFO ConfigCacheUtil:190 - 解压耗时: 85
2020-09-08 22:42:48 INFO ConfigCacheUtil:191 - 数据大小: 55412020-09-08 22:42:48 INFO ConfigCacheUtil:196 - 初始数据: 5541
2020-09-08 22:42:48 INFO ConfigCacheUtil:202 - 压缩耗时: 1
2020-09-08 22:42:48 INFO ConfigCacheUtil:203 - 数据大小: 919
2020-09-08 22:42:48 INFO ConfigCacheUtil:210 - 解压耗时: 22
2020-09-08 22:42:48 INFO ConfigCacheUtil:211 - 数据大小: 5541
6MB
2020-09-08 22:44:06 INFO ConfigCacheUtil:158 - 初始数据: 5719269
2020-09-08 22:44:06 INFO ConfigCacheUtil:164 - 压缩耗时: 129
2020-09-08 22:44:06 INFO ConfigCacheUtil:165 - 数据大小: 330090
2020-09-08 22:44:06 INFO ConfigCacheUtil:172 - 解压耗时: 69
2020-09-08 22:44:06 INFO ConfigCacheUtil:173 - 数据大小: 57192692020-09-08 22:44:06 INFO ConfigCacheUtil:177 - 初始数据: 5874139
2020-09-08 22:44:06 INFO ConfigCacheUtil:183 - 压缩耗时: 265
2020-09-08 22:44:06 INFO ConfigCacheUtil:184 - 数据大小: 201722
2020-09-08 22:44:06 INFO ConfigCacheUtil:191 - 解压耗时: 81
2020-09-08 22:44:06 INFO ConfigCacheUtil:192 - 数据大小: 58741392020-09-08 22:44:06 INFO ConfigCacheUtil:197 - 初始数据: 5874139
2020-09-08 22:44:06 INFO ConfigCacheUtil:203 - 压缩耗时: 42
2020-09-08 22:44:06 INFO ConfigCacheUtil:204 - 数据大小: 115423
2020-09-08 22:44:07 INFO ConfigCacheUtil:211 - 解压耗时: 49
2020-09-08 22:44:07 INFO ConfigCacheUtil:212 - 数据大小: 5874139
Redis 压缩列表
压缩列表(ziplist)是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现。
下面看一下压缩列表实现的列表键:

列表键里面包含的都是1、3、5、10086这样的小整数值,以及''hello''、''world''这样的短字符串。
再看一下压缩列表实现的哈希键:

压缩列表是Redis为了节约内存而开发的,是一系列特殊编码的连续内存块组成的顺序型数据结构。
一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
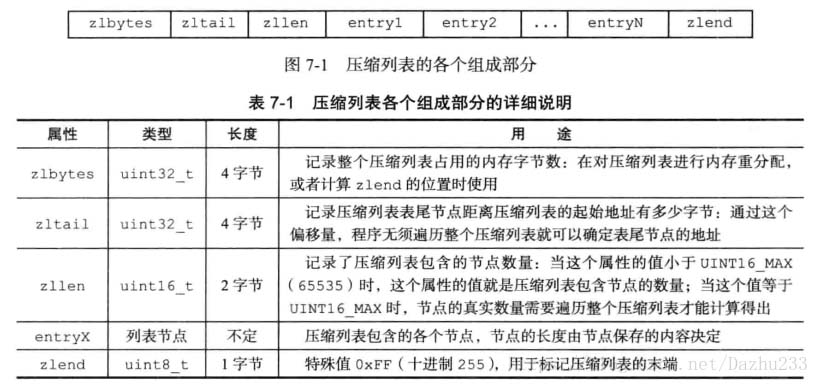
看一下压缩列表的示例:

看一下包含五个节点的压缩列表:

节点的encoding属性记录了节点的content属性所保存数据的类型以及长度。
节点的content属性负责保存节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的encoding属性决定。

连锁更新:
每个节点的previous_entry_length属性都记录了前一个节点的长度,那么当前一个节点的长度从254以下变成254以上时,本节点的存储前一个节点的长度的previous_entry_length就需要从1字节变为5字节。
那么后面的节点的previous_entry_length属性也有可能更新。不过连锁更新的几率并不大。
总结:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Redis字符串对象实用笔记
字符串对象 字符串数据类型是Redis里最常用的类型了,它的键和值都是字符串,使用起来非常的方便.虽然字符串数据类型的值都统称为字符串了,但是在实际存储时会根据值的不同自动选择合适的编码.字符串对象的编码一共有三种:int.raw.embstr. Redis对象 Redis用统一的数据结构来表示一个对象,具体定义如下: typedef struct redisObject { unsigned type:4; unsigned encoding:4; // 当内存超限时采用LRU算法清除内存中的
-
压缩列表牺牲速度来节省内存,Redis是膨胀了吗
正常情况下我们选择使用 Redis 就是为了提升查询速度,然而让人意外的是,Redis 当中却有一种比较有意思的数据结构,这种数据结构通过牺牲部分读写速度来达到节省内存的目的,这就是 ziplist(压缩列表),Redis 为什么要这么做呢?难道真的是觉得自己的速度太快了,牺牲一点速度也不影响吗? 什么是压缩列表 ziplist 是为了节省内存而设计出来的一种数据结构.ziplist 是由一系列特殊编码组成的连续内存块的顺序型数据结构,一个 ziplist 可以包含任意多个 entry,而每一个
-
详解redis数据结构之压缩列表
详解redis数据结构之压缩列表 redis使用压缩列表作为列表键和哈希键的底层实现之一.当一个列表键只包含少量的列表项,并且每个列表项都是由小整数值或者是短字符串组成,那么redis就会使用压缩列表存储列表项:同理,当一个哈希表包含的键值对都是由小整数值或者是短字符串组成,并且存储的键值对数目不多时,redis也会使用压缩列表来存储哈希表.以下是压缩列表存储结构: zlbytes长度为4个字节,记录了整个压缩列表所占用的字节数 zltail长度为4个字节,记录了压缩列表起始位置到压缩列表尾节
-
Redis字符串原理的深入理解
前言 来掘进都有两年多了一直当个小透明,今天终于发一次文章了. 最近在看 Redis,感觉收获很多,写篇博客记录一下. Redis 有五种基础数据结构:string,list,set,zset,hash.其中 string是最最最简单的也是最常用的.这个数据类型虽然简单但是内部的结构设计却很是精致. 基本介绍 相比于 Java,在 Redis 中 string 是可以修改的,是动态字符串(Simple Dynamic String 简称 SDS)他的内部结构更像是一个 ArrayList,维护一
-
压缩Redis里的字符串大对象操作
背景 Redis缓存的字符串过大时会有问题.不超过10KB最好,最大不能超过1MB. 有几个配置缓存,上千个flink任务调用,每个任务5分钟命中一次,大小在5KB到6MB不等,因此需要压缩. 第一种,使用gzip /** * 使用gzip压缩字符串 */ public static String compress(String str) { if (str == null || str.length() == 0) { return str; } ByteArrayOutputStream o
-
JS对象和字符串之间互换操作实例分析
本文实例讲述了JS对象和字符串之间互换操作.分享给大家供大家参考,具体如下: 平时在工作中大家一定也有过这样的需求,就是有时候需要把一个json对象转换为字符串,有时候要把一个类似json对象的字符串转换为json对象,那么今天就来总结一下,js的方法 1. json对象转字符串 这个API很简单就是 JSON.stringify() ,只需要把你要转换的对象写到括号里就行了,下面有一个小demo let json = { msg:"json转字符串", name:"前端林三
-
分布式爬虫处理Redis里的数据操作步骤
存入MongoDB 1.启动MongoDB数据库:sudo mongod 2.执行下面程序:py2 process_youyuan_mongodb.py # process_youyuan_mongodb.py # -*- coding: utf-8 -*- import json import redis import pymongo def main(): # 指定Redis数据库信息 rediscli = redis.StrictRedis(host='192.168.199.108',
-
详解处理Java中的大对象的方法
目录 String中的substring 集合大对象扩容 保持合适的对象粒度 Bitmap 把对象变小 数据的冷热分离 数据双写 写入 MQ 分发 使用 Binlog 同步 思维发散 小结 本文我们将讲解一下对于“大对象”的优化.这里的“大对象”,是一个泛化概念,它可能存放在 JVM 中,也可能正在网络上传输,也可能存在于数据库中. 那么为什么大对象会影响我们的应用性能呢? 第一,大对象占用的资源多,垃圾回收器要花一部分精力去对它进行回收: 第二,大对象在不同的设备之间交换,会耗费网络流量,以及
-
JSON字符串和对象相互转换实例分析
本文实例分析了JSON字符串和对象相互转换方法.分享给大家供大家参考,具体如下: 同事问了我一个问题--server端返回了一个json结构的字符串,怎么样去访问json对象里面的值?jquery有没有对返回的JSON数据进行解析? 我自己写了一个小的demo,还有从网上查了一些资料,在这里跟大家分享一下 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/T
-
Python使用jsonpath-rw模块处理Json对象操作示例
本文实例讲述了Python使用jsonpath-rw模块处理Json对象操作.分享给大家供大家参考,具体如下: 这两天在写一个爬虫,需要从网站返回的json数据提取一些有用的数据. 向url发起请求,返回的是response,在python3中,response.content是二进制bytes类型的,需要用decode()转成unicode的str类型 #如果用的requests发的请求 import json response = requests.get(url,headers=self.
-
详解Redis 键和字符串常用命令
目录 Redis 相关知识 Redis中的数据类型 redis 键(key) Redis字符串(String) 常用命令 String的数据结构 Redis 相关知识 Redis的默认端口号为6379 默认16个数据库,类似数组下标从0开始,初始默认使用0号库.使用命令select <dbid>来切换数据库. 如: select 8.统一密码管理,所有库同样密码. dbsize查看当前数据库的key的数量.flushdb清空当前库.flushall通杀全部库. Redis是单线程+多路IO复用
-
Python实现压缩与解压gzip大文件的方法
本文实例讲述了Python实现压缩与解压gzip大文件的方法.分享给大家供大家参考,具体如下: #encoding=utf-8 #author: walker #date: 2015-10-26 #summary: 测试gzip压缩/解压文件 import gzip BufSize = 1024*8 def gZipFile(src, dst): fin = open(src, 'rb') fout = gzip.open(dst, 'wb') in2out(fin, fout) def gun
-
Python字符串和文件操作常用函数分析
本文实例分析了Python字符串和文件操作常用函数.分享给大家供大家参考.具体如下: # -*- coding: UTF-8 -*- ''' Created on 2010-12-27 @author: sumory ''' import itertools def a_containsAnyOf_b(seq,aset): '''判断seq中是否含有aset里的一个或者多个项 seq可以是字符串或者列表 aset应该是字符串或者列表''' for item in itertools.ifilte
-
PHP获取redis里不存在的6位随机数应用示例【设置24小时过时】
本文实例讲述了PHP获取redis里不存在的6位随机数的方法.分享给大家供大家参考,具体如下: PHP获取6位数随机数 PHP str_shuffle() 函数 str_shuffle() 函数随机打乱字符串中的所有字符. 参数 描述 string 必需.规定要打乱的字符串. 用php的str_shuffle函数: <?php $randStr = str_shuffle('ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'); $rand = substr($randS