mysql查询连续记录方式
目录
- 案例
- 解决思路
- 1.对满足初次查询的数据赋予一个自增列b
- 2.用自增的id减去自增列b
- 3.对等差列c分组, 并将分组的id组装起来
- 4.根据组装的id去找数据
- 总结建议
案例
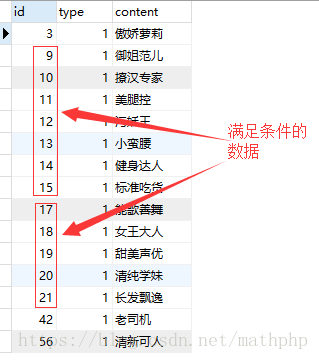
最近遇到一个业务需求, 需要查找满足条件且连续3出现条以上的记录。
表结构:
CREATE TABLE `cdb_labels` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `type` int(11) NOT NULL DEFAULT '0' COMMENT '标签类型:1喜欢异性类型,2擅长话题', `content` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL COMMENT '标签内容', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=57 DEFAULT CHARSET=utf8 COMMENT='标签内容';
所有数据:
SELECT * FROM cdb_labels WHERE type = 1;
解决思路
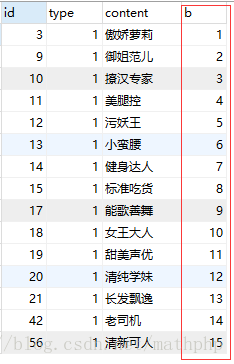
1.对满足初次查询的数据赋予一个自增列b
select id,type,content,(@b:=@b+1) as b from cdb_labels a,(SELECT @b := 0) tmp_b where type=1;
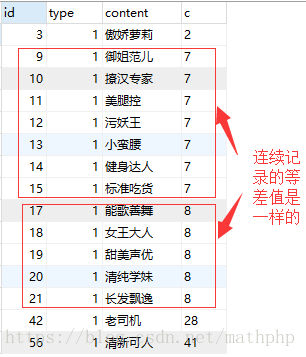
2.用自增的id减去自增列b
select id,type,content,( id-(@b:=@b+1) ) as c from cdb_labels a,(SELECT @b := 0) tmp_b where type=1;
3.对等差列c分组, 并将分组的id组装起来
select count(id),GROUP_CONCAT(id) from (
select id,( id-(@b:=@b+1) ) as c from cdb_labels a,(SELECT @b := 0) tmp_b where type=1
) as d GROUP BY c;
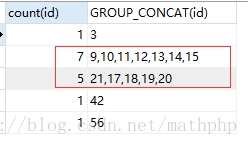
注:为了方便区分,这里查询分组成员要大于5(也就是连续出现超过5次的记录):
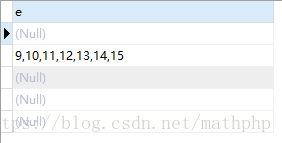
select if( count(id)>5 ,GROUP_CONCAT(id),null) e from ( select id,( id-(@b:=@b+1) ) as c from cdb_labels a,(SELECT @b := 0) tmp_b where type=1 ) as d GROUP BY c;
那么得到的数据只有:9,10,11,12,13,14,15
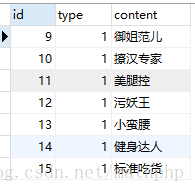
4.根据组装的id去找数据
select id,type,content from cdb_labels,(
select if( count(id)>5 ,GROUP_CONCAT(id),null) e from (
select id,( id-(@b:=@b+1) ) as c from cdb_labels a,(SELECT @b := 0) tmp_b where type=1
) as d GROUP BY c
) as f where f.e is not null and FIND_IN_SET(id , f.e);
总结建议
- MySQL的函数例如: GROUP_CONCAT() 的字符长度有限制(默认1024),如果连续记录较多会发生字符截取报错;
- 建议可以分步骤去查询,防止嵌套子查询,还可以提升性能而且避免使用MySQL函数;
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
mysql 查询第几行到第几行记录的语句
1.查询第一行记录: select * from table limit 1 2.查询第n行到第m行记录 select * from table1 limit n-1,m-n; SELECT * FROM table LIMIT 5,10:返回第6行到第15行的记录 select * from employee limit 3,1; // 返回第4行 3.查询前n行记录 select * from table1 limit 0,n; 或 select * from table1 limit n;
-
mysql随机查询若干条数据的方法
在mysql中查询5条不重复的数据,使用以下: 复制代码 代码如下: SELECT * FROM `table` ORDER BY RAND() LIMIT 5 就可以了.但是真正测试一下才发现这样效率非常低.一个15万余条的库,查询5条数据,居然要8秒以上搜索Google,网上基本上都是查询max(id) * rand()来随机获取数据. 复制代码 代码如下: SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * (SELECT MAX
-
MySQL中查询、删除重复记录的方法大全
前言 本文主要给大家介绍了关于MySQL中查询.删除重复记录的方法,分享出来供大家参考学习,下面来看看详细的介绍: 查找所有重复标题的记录: select title,count(*) as count from user_table group by title having count>1; SELECT * FROM t_info a WHERE ((SELECT COUNT(*) FROM t_info WHERE Title = a.Title) > 1) ORDER BY Titl
-

mysql查询表里的重复数据方法
INSERT INTO hk_test(username, passwd) VALUES ('qmf1', 'qmf1'),('qmf2', 'qmf11') delete from hk_test where username='qmf1' and passwd='qmf1' MySQL里查询表里的重复数据记录: 先查看重复的原始数据: 场景一:列出username字段有重读的数据 select username,count(*) as count from hk_test group by
-
mysql查询连续记录方式
目录 案例 解决思路 1.对满足初次查询的数据赋予一个自增列b 2.用自增的id减去自增列b 3.对等差列c分组, 并将分组的id组装起来 4.根据组装的id去找数据 总结建议 案例 最近遇到一个业务需求, 需要查找满足条件且连续3出现条以上的记录. 表结构: CREATE TABLE `cdb_labels` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `type` int(11) NOT NULL DEFAULT '0' COMM
-
MYSQL实现连续签到功能断签一天从头开始(sql语句)
1,创建测试表 CREATE TABLE `testsign` ( `userid` int(5) DEFAULT NULL, `username` varchar(20) DEFAULT NULL, `signtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `type` int(1) DEFAULT '0' COMMENT '为0表示签到数据,1表示签到日期字典数据' ) ENGIN
-
MySQL查询条件常见用法详解
本文实例讲述了MySQL查询条件常见用法.分享给大家供大家参考,具体如下: 条件 使用where子句对表中的数据筛选,结果为true的行会出现在结果集中 语法如下: select * from 表名 where 条件; 例: select * from students where id=1; where后面支持多种运算符,进行条件的处理 比较运算符 逻辑运算符 模糊查询 范围查询 空判断 比较运算符 等于: = 大于: > 大于等于: >= 小于: < 小于等于: <= 不等于:
-
SQL 查询连续登录的用户情况
以连续3天为例,使用工具:MySQL. 1.创建SQL表: create table if not exists orde(id varchar(10),date datetime,orders varchar(10)); insert into orde values('1' , '2019/1/1',10 ); insert into orde values('1' , '2019/1/2',109 ); insert into orde values('1' , '2019/1/3',15
-
mysql 生成连续日期及变量赋值
目录 1.生产连续日期 2.变量赋值 1.生产连续日期 说明:主要作用于一些统计数据,来根据时间顺序进行显示:假如数据库数据有隔天数据,偏偏统计又需要每天的都显示,即便是0,那就要生成一个时间表,来使用: 查询数据库数据: SELECT DATE_FORMAT( create_time, '%Y-%m-%d' ) AS date, COUNT(1) AS numb FROM qc_task WHERE create_time>= DATE
-
mysql查询语句中用户变量的使用代码解析
上一篇文章中我们介绍了MySQL优化总结-查询总条数.这篇文章我们来介绍下查询语句中的另一个知识:用户变量的使用代码解析. 先上代码吧 SELECT `notice`.`id` , `notice`.`fid` , `notice`.`has_read` , `notice`.`notice_time` , `notice`.`read_time` , `f`.`fnum` , `f`.`forg` , `f`.`fdst` , `f`.`actual_parking` AS `parking`
-
PHP访问MySQL查询超时处理的方法
目前两个客户端扩展库连接超时可以设置选项来操作,比如mysqli: 复制代码 代码如下: <?php //创建对象 $mysqli = mysqli_init(); //设置超时选项 $mysqli->options(MYSQLI_OPT_CONNECT_TIMEOUT, 5); //连接 $mysqli->real_connect('localhost', 'my_user', 'my_password', 'world'); //如果超时或者其他连接失败打印错误信息 if (mysq
-
如何设计高效合理的MySQL查询语句
MySQL查询语句大家都在用,但是应该如何设计高效合理的MySQL查询语句呢?下面就教您MySQL查询语句的合理设计方法,分享给大家学习学习. 1.合理使用索引 索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率.现在大多数的数据库产品都采用IBM最先提出的ISAM索引结构.索引的使用要恰到好处,其使用原则如下: ●在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引. ●在频繁进行排序或分组(即进行group by或order by操作)的列上
-
mysql查询语句通过limit来限制查询的行数
mysql查询语句,通过limit来限制查询的行数. 例如: select name from usertb where age > 20 limit 0, 1; //限制从第一条开始,显示1条 select name from usertb where age > 20 limit 1; //同上面的一个效果 select name from usertb where age > 20 limit 4, 1; //显示从第五条开始,显示1条
-
MySql查询时间段的方法
本文实例讲述了MySql查询时间段的方法.分享给大家供大家参考.具体方法如下: MySql查询时间段的方法未必人人都会,下面为您介绍两种MySql查询时间段的方法,供大家参考. MySql的时间字段有date.time.datetime.timestamp等,往往我们在存储数据的时候将整个时间存在一个字段中,采用datetime类型:也可能采用将日期和时间分离,即一个字段存储date,一个字段存储时间time.无论怎么存储,在实际应用中,很可能会出现包含"时间段"类型的查询,比如一个访