pandas:get_dummies()与pd.factorize()的用法及区别说明
1.get_dummies()
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None,sparse=False, drop_first=False):Convert categorical variable into dummy/indicator variables
>>> import pandas as pd
>>> s = pd.Series(list('abca'))
>>> pd.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
2.pd.factorize()
pandas.factorize(values, sort=False, order=None, na_sentinel=-1,size_hint=None):Encode input values as an enumerated type or categorical variable
Series.factorize(sort=False, na_sentinel=-1):Encode the object as an enumerated type or categorical variable
Pandas有一个方法叫做factorize(),它可以创建一些数字,来表示类别变量,对每一个类别映射一个ID,这种映射最后只生成一个特征,不像dummy那样生成多个特征。
| Parameters: |
sort : boolean, default False
na_sentinel: int, default -1
|
|---|---|
| Returns: |
labels : the indexer to the original array uniques : the unique Index |
labels:对应的编码array
uniques:需要编码的类型
补充:pandas.get_dummies 的使用及含义
get_dummies 是利用pandas实现one hot encode的方式
get_dummies参数如下:
pandas.get_dummies(data,prefix = None,prefix_sep ='_',dummy_na = False,columns = None,sparse = False,drop_first = False,dtype = None )
data : array-like,Series或DataFrame
prefix :string,字符串列表或字符串dict,默认为None,
用于追加DataFrame列名的字符串。在DataFrame上调用get_dummies时,传递一个长度等于列数的列表。或者,前缀 可以是将列名称映射到前缀的字典。
prefix_sep : string,默认为'_'
如果附加前缀,分隔符/分隔符要使用。或者传递与前缀一样的列表或字典。
dummy_na : bool,默认为False
如果忽略False NaN,则添加一列以指示NaN。
columns : 类似列表,默认为无
要编码的DataFrame中的列名称。如果列是None,那么所有与列 对象或类别 D型细胞将被转换。
sparse : bool,默认为False
伪编码列是否应由SparseArray(True)或常规NumPy数组(False)支持。
drop_first : bool,默认为False
是否通过删除第一级别从k分类级别获得k-1个假人。
版本0.18.0中的新功能。
dtype: D型,默认np.uint8
新列的数据类型。只允许一个dtype。
版本0.23.0中的新功能。
实例
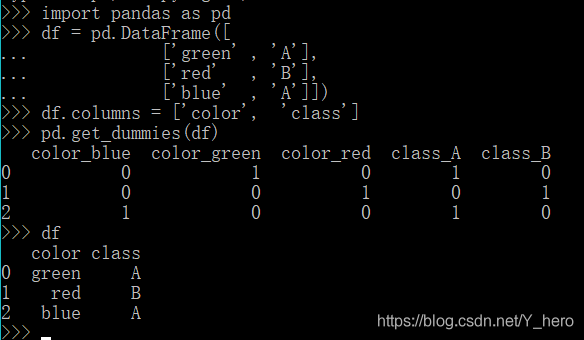
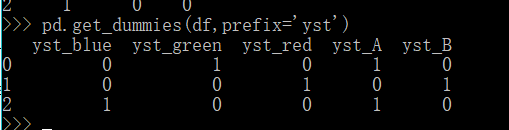
prefix自定义前缀
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python pandas用法最全整理
1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as npimport pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1))df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001,1002,1003
-
pandas使用get_dummies进行one-hot编码的方法
离散特征的编码分为两种情况: 1.离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码 2.离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3} 使用pandas可以很方便的对离散型特征进行one-hot编码 import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的
-

pandas:get_dummies()与pd.factorize()的用法及区别说明
1.get_dummies() pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None,sparse=False, drop_first=False):Convert categorical variable into dummy/indicator variables >>> import pandas as pd >>> s = pd.Series(list
-
pandas中pd.groupby()的用法详解
在pandas中的groupby和在sql语句中的groupby有异曲同工之妙,不过也难怪,毕竟关系数据库中的存放数据的结构也是一张大表罢了,与dataframe的形式相似. import numpy as np import pandas as pd from pandas import Series, DataFrame df = pd.read_csv('./city_weather.csv') print(df) ''' date city temperature
-
Python Pandas数据合并pd.merge用法详解
目录 前言 语法 参数 1.连接键 2.索引连接 3.多连接键 4.连接方法 5.连接指示 总结 前言 实现类似SQL的join操作,通过pd.merge()方法可以自由灵活地操作各种逻辑的数据连接.合并等操作 可以将两个DataFrame或Series合并,最终返回一个合并后的DataFrame 语法 pd.merge(left, right, how = 'inner', on = None, left_on = None, right_on = None, left_index = Fal
-
pandas dataframe 中的explode函数用法详解
在使用 pandas 进行数据分析的过程中,我们常常会遇到将一行数据展开成多行的需求,多么希望能有一个类似于 hive sql 中的 explode 函数. 这个函数如下: Code # !/usr/bin/env python # -*- coding:utf-8 -*- # create on 18/4/13 import pandas as pd def dataframe_explode(dataframe, fieldname): temp_fieldname = fieldname
-
Pandas中的 transform()结合 groupby()用法示例详解
首先,假设我们有如下餐厅数据集: import pandas as pd df = pd.DataFrame({ 'restaurant_id': [101,102,103,104,105,106,107], 'address': ['A','B','C','D', 'E', 'F', 'G'], 'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'], 'sales': [10,500,48,12,2
-
pandas时间序列之pd.to_datetime()的实现
目录 解析来自各种来源和格式的时间序列信息 时间序列解析之小试牛刀 时间序列解析之磨刀霍霍 1. 指定识别的format 2. 遇到DataFrame 3. 遇到不能识别的处理方法 4. origin的用法 解析来自各种来源和格式的时间序列信息 pd.to_datetime( arg,#int, float, str, datetime, list, tuple, 1-d array, Series DataFrame/dict-like errors='raise',# {'ignore',
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
Pandas数据连接pd.concat的实现
目录 1.按行连接 2.按列连接 3.合并交集 扩展 4.与序列合并 5.指定索引 Pandas数据可以实现纵向和横向连接,将数据连接后会形成一个新对象(Series或DataFrame) 连接是最常用的多个数据合并操作 pd.concat()是专门用于数据连接合并的函数,它可以沿着行或列进行操作,同时可以指定非合并轴的合并方式(如合集.交集等) pd.concat()会返回一个合并后的DataFrame 语法 pd.concat(objs, axis=0, join='outer', igno
-
基于python cut和qcut的用法及区别详解
我就废话不多说了,直接上代码吧: from pandas import Series,DataFrame import pandas as pd import numpy as np from numpy import nan as NA from matplotlib import pyplot as plt ages = [20,22,25,27,21,23,37,31,61,45,41,32] #将所有的ages进行分组 bins = [18,25,35,60,100] #使用pandas
-
详谈pandas中agg函数和apply函数的区别
在利用python进行数据分析 这本书中其实没有明确表明这两个函数的却别,而是说apply更一般化. 其实在这本书的第九章'数组及运算和转换'点到了两者的一点点区别:agg是用来聚合运算的,所谓的聚合当然是合成的成分比较大些,这一节开头就点到了:聚合只不过是分组运算的其中一种而已.它是数据转换的一个特例,也就是说,它接受能够将一维数组简化为标量值的函数. 当然这两个函数都是作用在groupby对象上的,也就是分完组的对象上的,分完组之后针对某一组,如果值是一维数组,在利用完特定的函数之后,能做到