python之NAN和INF值处理方式
目录
- 一、NAN和INF值处理
- 二、NAN一些特点
- 三、两种处理方式:删除缺失值,用其他值进行填充
- 3.1删除缺失值
- 3.2用其他值进行填充
- 总结
一、NAN和INF值处理
首先我们要知道这两个英文单词代表的什么意思:
NAN:Not A number,不是一个数字的意思,但是他是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型。INF:Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为0的时候为无穷大。比如2/0。
二、NAN一些特点
- NAN和NAN不相等。比如np.NAN != np.NAN这个条件是成立的。
- NAN和任何值做运算,结果都是NAN。
有些时候,特别是从文件中读取数据的时候,经常会出现一些缺失值。缺失值的出现会影响数据的处理。因此我们在做数据分析之前,先要对缺失值进行一些处理。处理的方式有多种,需要根据实际情况来做。一般有两种处理方式:删除缺失值,用其他值进行填充。
三、两种处理方式:删除缺失值,用其他值进行填充
3.1删除缺失值
3.1.1 将数组中的NAN删掉,那么我们可以换一种思路,就是只提取不为NAN的值


3.1.2 删除NAN所在的行(删除后还是二维数组)

3.2用其他值进行填充
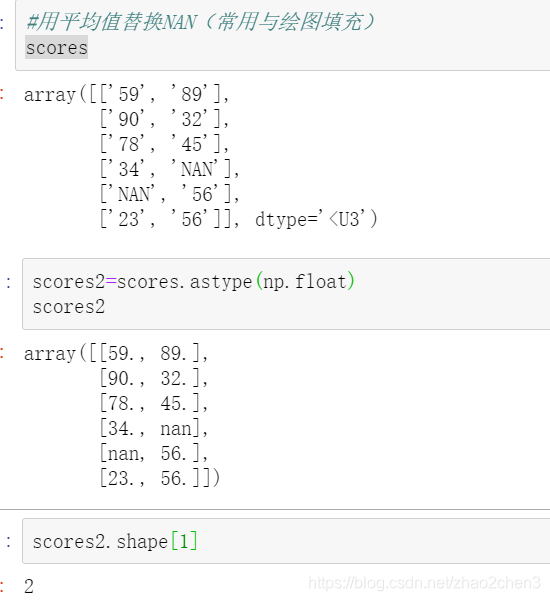
有些时候我们不想直接删掉,比如有一个成绩表,分别是数学和英语,但是因为某个人在某个科目上没有成绩,那么此时就会出现NAN的情况,这时候就不能直接删掉了,就可以使用某些值进行替代。
假如有以下表格:
| 数学 | 英语 |
|---|---|
| 59 | 89 |
| 90 | 32 |
| 78 | 45 |
| 34 | NAN |
| NAN | 56 |
| 23 | 56 |
如果想要求每门成绩的总分,以及每门成绩的平均分,那么就可以采用某些值替代。比如求总分,那么就可以把NAN替换成0,如果想要求平均分,那么就可以把NAN替换成其他值的平均值。示例代码如下:

总结
1.NAN: Not A Number的简写,不是一个数字,但是他是属于浮点类型。
2.INF:无穷大,在除数为0的情况下会出现INF。
3.NAN和所有的值进行计算结果都是等于NAN
4.NAN != NAN
5.可以通过np.isnan来判断某个值是不是NAN。
6.处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换进行处理。
7.np.delete比较特殊,他通过axis=0来代表行,而其他大部分函数是通过axis=1来代表行。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
关于Python中Inf与Nan的判断问题详解
大家都知道 在Python 中可以用如下方式表示正负无穷: float("inf") # 正无穷 float("-inf") # 负无穷 利用 inf(infinite) 乘以 0 会得到 not-a-number(NaN) .如果一个数超出 infinite,那就是一个 NaN(not a number)数.在 NaN 数中,它的 exponent 部分为可表达的最大值,即 FF(单精度).7FF(双精度)和 7FFF(扩展双精度). NaN 数与 infinit
-
Python快速转换numpy数组中Nan和Inf的方法实例说明
在使用numpy数组的过程中时常会出现nan或者inf的元素,可能会造成数值计算时的一些错误.这里提供一个numpy库函数的用法,使nan和inf能够最简单地转换成相应的数值. numpy.nan_to_num(x): 使用0代替数组x中的nan元素,使用有限的数字代替inf元素 使用范例: >>>import numpy as np >>> a = np.array([[np.nan,np.inf],\ ... [-np.nan,-np.inf]]) >>
-
python中nan与inf转为特定数字方法示例
前言 最近因为工作的需求,要处理两个矩阵的点除,得到结果后,再作其他的计算,发现有些内置的函数不work:查看得到的数据,发现有很多nan和inf,导致Python的基本函数运行不了,这是因为在除的过程中分母出现0的缘故.为了将结果能够被python其他函数处理,尤其numpy库,需要将nan,inf转为python所能识别的类型. 这里将nan,inf替换0作为例子.下面来看看详细的介绍: 1. 代码 import numpy as np a = np.array([[np.nan, np.n
-
Python 实现将numpy中的nan和inf,nan替换成对应的均值
nan:not a number inf:infinity;正无穷 numpy中的nan和inf都是float类型 t!=t 返回bool类型的数组(矩阵) np.count_nonzero() 返回的是数组中的非0元素个数:true的个数. np.isnan() 返回bool类型的数组. 那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响? 比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者
-

python之NAN和INF值处理方式
目录 一.NAN和INF值处理 二.NAN一些特点 三.两种处理方式:删除缺失值,用其他值进行填充 3.1删除缺失值 3.2用其他值进行填充 总结 一.NAN和INF值处理 首先我们要知道这两个英文单词代表的什么意思: NAN:Not A number,不是一个数字的意思,但是他是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型. INF:Infinity,代表的是无穷大的意思,也是属于浮点类型.np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为0的时候为无穷大.比
-
Python判断Nan值的五种方式小结
目录 Python判断Nan值方式小结 numpy判断 Math判断 Pandas判断 判断是否等于自身 Nan不属于任何取值区间 python的nan处理 定义nan的方法 常见的计算结果为nan的情况 Python判断Nan值方式小结 numpy判断 import numpy as np nan = float('nan') print(np.isnan(nan)) True Math判断 import math nan = float('nan') print(math.isnan(nan
-
python dataframe NaN处理方式
将dataframe中的NaN替换成希望的值 import pandas as pd df1 = pd.DataFrame([{'col1':'a', 'col2':1}, {'col1':'b', 'col2':2}]) df2 = pd.DataFrame([{'col1':'a', 'col3':11}, {'col1':'c', 'col3':33}]) data = pd.merge(left=df1, right=df2, how='left', left_on='col1', ri
-
python requests response值判断方式
这段时间在技术上没太多的思考的,只是碰到几个虾米小问题. 往往问题不大,也会致使你花心思去排解. 今遇到一个reqeusts返回值的一个问题,花了不短时间调,后来发现是reqeusts返回的对象也含有 魔法函数 处理. 我这边的业务是cdn的刷新预缓存,对于该项目来说 http code 200, 2xx, 404 都是友好的. #jb51.net import requests r = None try: r = requests.get("https://jb51.net") ex
-
Python获取协程返回值的四种方式详解
目录 介绍 源码 依次执行结果 介绍 获取协程返回值的四种方式: 1.通过ensure_future获取,本质是future对象中的result方 2.使用loop自带的create_task, 获取返回值 3.使用callback, 一旦await地方的内容运行完,就会运行callback 4.使用partial这个模块向callback函数中传入值 源码 import asyncio from functools import partial async def talk(name): pr
-
Python+MongoDB自增键值的简单实现
背景 最近在写一个测试工具箱,里面有一个bug记录系统,因为后台我是用Django和MongoDB来实现的,就遇到了一个问题,要如何实现一个自增的字段. 传统的关系型数据库要实现起来是非常容易,只要直接设置一个自增字段就行了,插入数据时不用管这个键值,只管自己处理的数据就行了,会自动实现自增的功能,但是非关系型数据库好像没有这个功能(或者我不知道).百度之后发现都是MongoDB的设置方法,并不是我想要的. 解决思路 百度没有找到好的思路,那就只能自己解决了,我的想法很简单,字段不会自增,那么就
-
python获取list下标及其值的简单方法
当在python中遍历一个序列时,我们通常采用如下的方法: for item in sequence: process(item) 如果要取到某个item的位置,可以这样写: for index in range(len(sequence)): process(sequence[index]) 另一个比较好的方式是使用python内建的enumerate函数: enumerate(sequence,start=0) 上述函数中,sequence是一个可迭代的对象,可以是列表,字典,文件对象等等.