Python实现一键整理百度云盘中重复无用文件
目录
- 获取云盘缓存目录
- 云盘数据整理
- 云盘数据导出
- 数据整理
- 重复文件提取
有没有头疼过百度云盘都要塞满了,可是又没有工具能剔除大量重复无用的文件?这里教你一个简单的方法,通过整理目录的方式来处理我们云盘中无用的文件吧。
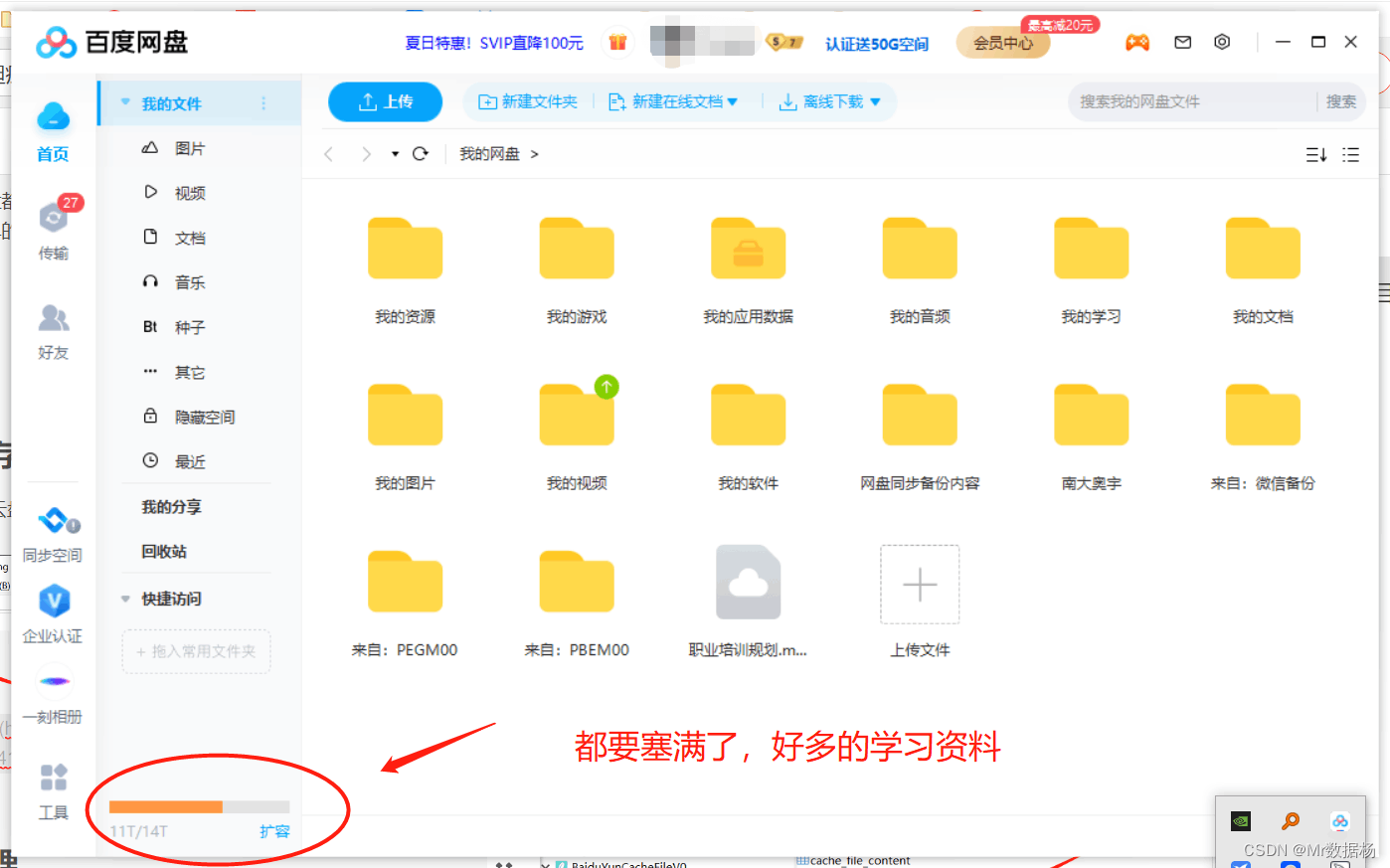
获取云盘缓存目录
使用 Everything 找到云盘缓存 db 文件,复制到脚本的目录下。
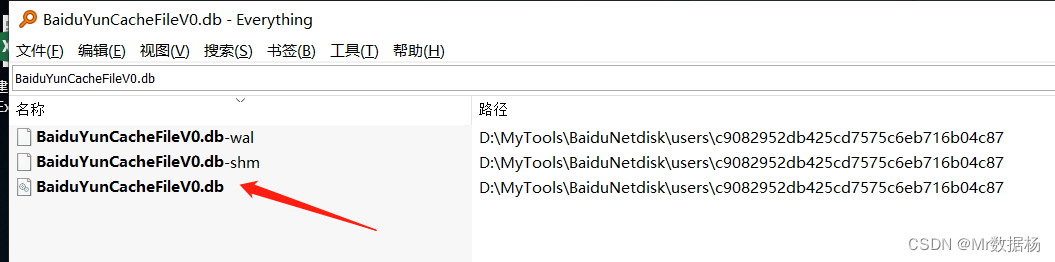
云盘数据整理
我们发现这个是一个 sqlite3 的文件,用 Navicat 打开先看看。

我们所有云盘的文件以及对应的路径保存在 cache_file 中,直接导出可能会有些问题,所以我们用 pandas 来处理数据就可以了。
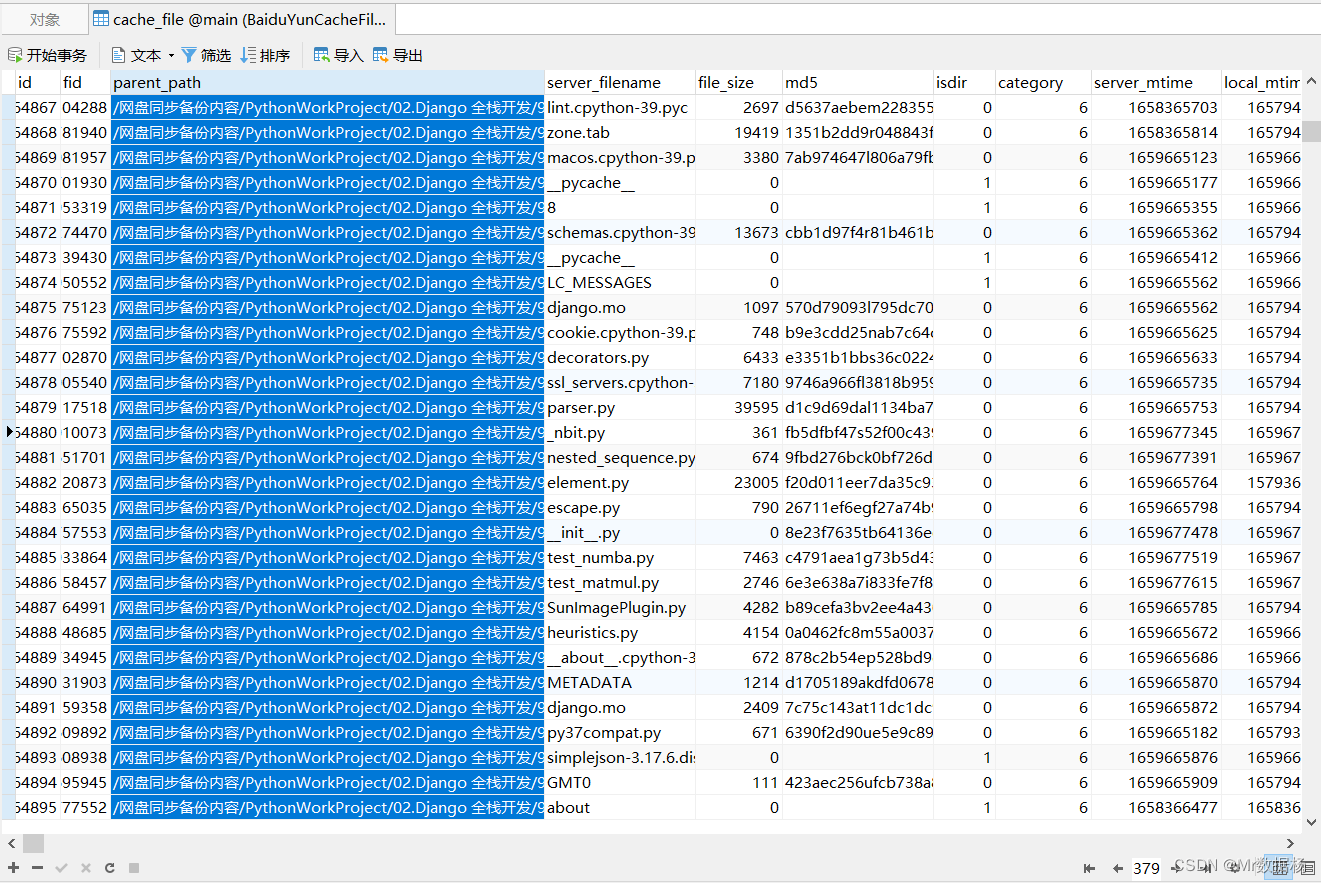
云盘数据导出
我的云盘导出来了 40MB 的目录数据,看着都头疼。
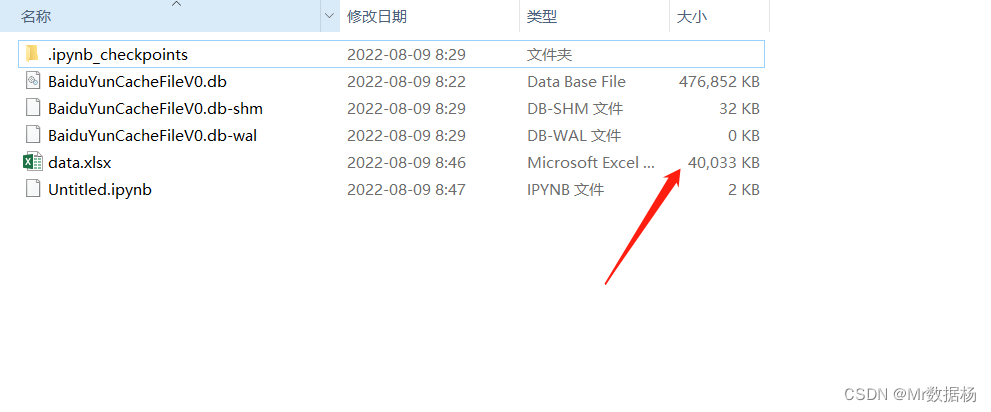
数据整理
把云盘的目录数据导出到 excel,后去该怎么处理就怎么处理吧。代码非常少,如果喜欢用 python 处理就用 pandas 处理,如果感觉有困难直接在 excel 中处理就可以了。
import sqlite3
import pandas as pd
file_dict = {}
con = sqlite3.connect('BaiduYunCacheFileV0.db')
cursor = con.cursor()
cursor.execute("select * from cache_file")
values = cursor.fetchall()
df = pd.DataFrame(values,columns=["id","fid","parent_path","server_filename","file_size","md5","isdir","category","server_mtime","local_mtime","reserved1","reserved2","reserved3","reserved4","reserved5","reserved6","reserved7","reserved8","reserved9"])
df.to_excel("data.xlsx")

重复文件提取
这个由于百度云盘没有对应的API接口可以使用爬虫的方式进行网页的操作对重复数据进行删除,但是容易误操作,所以还是手动把要处理的数据整理出来然后进行操作把。
通过文件名称判断重复,有了结果后续自己处理就好了。
df["server_filename"].duplicated()
0 False
1 False
2 False
3 False
4 False
...
379563 False
379564 False
379565 True
379566 True
379567 False
Name: server_filename, Length: 379568, dtype: bool
df[df["server_filename"].duplicated()]["server_filename"]
188 WE_rk_nos06.txt
252 django.po
254 django.po
255 django.po
256 django.po
...
378517 video.mp4
378518 top_level.txt
378543 Blog_articleinfo.xlsx
379565 apps
379566 职业培训规划.mmap
Name: server_filename, Length: 152409, dtype: object
到此这篇关于Python实现一键整理百度云盘中重复无用文件的文章就介绍到这了,更多相关Python整理重复文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现自动整理文件
前言: 平时工作没有养成分类的习惯,整个桌面杂乱无章都是文档和资料,几乎快占满整个屏幕了.所以必须要整理一下了,今天我们来看下用python如何批量将不同后缀的文件移动到同一文件夹. 演示效果: 使用前 使用后 代码: # # -*- coding:utf-8 -*- import os import glob import shutil import tkinter import tkinter.filedialog from datetime import datetime def star
-
Python实现清理重复文件功能的示例代码
目录 前置 查找.删除重复文件 GUI制作 GUI界面设计 逻辑设计 效果展示 在电脑上或多或少的存在一些重复文件,体积小的倒没什么,如果体积大的就很占内存了,而如果自己一个一个查看文件是否重复,然后再删除,还是很要命的. 为此,我用python制作了一个删除重复文件的小工具,核心代码很简单,就十行代码,不管什么类型的文件都可以一键删除! 前置 PySimpleGUI库用来创建可视化界面,os操作文件,只需要这两个库: import os import PySimpleGUI as sg os为
-
利用Python删除电脑中重复文件的方法
目录 前言 练习 代码演示 总结 前言 在生活中,我们经常会遇到电脑中文件重复的情况.在文件较少的情况下,这类情况还比较容易处理,最不济就是一个个手动对比删除:而在重复文件很多的时候,我们很难保证把重复文件全部删完.下面文章就来简单介绍便捷一个小方法,用Python来删除重复文件 练习 Python提供一个内置电脑文件管理库os模块,我们可以利用它来删除多余文件. 当一个文档里存在重复文件名,我们的系统会自动给我们重复的文件名更名, 比如下图的文件“1”重复了3次: 那我们该怎么删除文件“1”
-
Python实现批量自动整理文件
为了实现这样的小工具,我们先设想有下面这些功能. 1.可以自定义整理某一个路径下面的所有需要被整理的文件.2.默认情况下,使用文件后缀作为同一种类文件的文件夹名称,有其他想法的小伙伴可自行扩展. 将使用到的python模块导入到代码块中. import os # 文件/文件夹应用操作 import shutil # 移动文件 import logging # 使用日志logging来打印日志 选择好需要整理的原始文件目录. 下面是整理完成后的效果图,根据文件类型对各种文件进行整理. 在代码块中加
-
Python脚本实现一键自动整理办公文件
目录 导语: 1.准备 2.原理 3.自定义整理 导语: 举例:Python做一个根据后缀名整理文件的工具,先来看看效果: 自动整理前: 自动整理后: 这样看起来就好很多了. 1.准备 开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,可以访问这篇文章:python Windows最新版本安装教程 我们只需要修改源代码主程序中调用 auto_organize函数的参数即可完成对对应文件夹的整理,比如我想整理 C:\Users\83493\Downloads 文件夹: if
-
Python自动化办公之清理重复文件详解
目录 清理重复的文件 清理重复文件的优化 清理重复的文件 已知条件: 什么都不知道,只需要知道它是文件就可以了 实现方法: 可以从指定路径(或最上层路径)开始读取,利用 glob 读取每个文件夹,读到文件,记录名称和大小,每一次检测之前是否读取过相同名称的文件,如果存在,判断大小是否相同,如果相同,我们就认为这是重复文件,将其删除. 代码示例如下: # coding:utf-8 import glob import os.path data = {} # 定义一个空的字典,暂时将文件名存进来 d
-
Python实现一键整理百度云盘中重复无用文件
目录 获取云盘缓存目录 云盘数据整理 云盘数据导出 数据整理 重复文件提取 有没有头疼过百度云盘都要塞满了,可是又没有工具能剔除大量重复无用的文件?这里教你一个简单的方法,通过整理目录的方式来处理我们云盘中无用的文件吧. 获取云盘缓存目录 使用 Everything 找到云盘缓存 db 文件,复制到脚本的目录下. 云盘数据整理 我们发现这个是一个 sqlite3 的文件,用 Navicat 打开先看看. 我们所有云盘的文件以及对应的路径保存在 cache_file 中,直接导出可能会有些问题,所
-
Python实现统计给定字符串中重复模式最高子串功能示例
本文实例讲述了Python实现统计给定字符串中重复模式最高子串功能.分享给大家供大家参考,具体如下: 给定一个字符串,如何得到其中重复模式最高的子字符串,我采用的方法是使用滑窗机制,对给定的字符串切分,窗口的大小从1增加到字符串长度减1,将所有的得到的切片统计结果,在这里不考虑单个字符的重复模式,好了,很简单看具体实现: #!usr/binenv python #encoding:utf-8 ''''' __Author__:沂水寒城 统计一个给定字符串中重复模式数量得到最高重复模式串 '''
-
Python实现删除排序数组中重复项的两种方法示例
本文实例讲述了Python实现删除排序数组中重复项的两种方法.分享给大家供大家参考,具体如下: 对于给定的有序数组nums,移除数组中存在的重复数字,确保每个数字只出现一次并返回新数组的长度 注意:不能为新数组申请额外的空间,只允许申请O(1)的额外空间修改输入数组 Example 1: Given nums = [1,1,2], Your function should return length = 2, with the first two elements of nums being 1
-
python代码实现将列表中重复元素之间的内容全部滤除
1. 引言 因为在学习遗传算法路径规划的内容,其中遗传算法中涉及到了种群的初始化,而在路径规划的种群初始化中,种群初始化就是先找到一条条从起点到终点的路径,也因此需要将路径中重复节点之间的路径删除掉(避免走回头路),这样子初始种群会比较优越,也能加快算法收敛速度.然后我在搜资料的时候发现,许多的代码都是滤除列表中相同元素的,并没有滤除相同元素中间段的代码,因此就自己写了. 2. 代码部分 我在python程序中把每一条路径用列表表示的,因此每一个列表就是一条路径比如 a = [0,1,3,4,5
-
Python/ArcPy遍历指定目录中的MDB文件方法
如下所示: #遍历指定目录中的MDB文件,构造FeatureClass名 >>> target_folder = 'D:\T20161202' ... file_names=('BOUAN','BOULK','BOUNT','BOUPT','CTRLK','CTRPT','HYDAN','HYDLK','HYDNT','HYDPT','PIPAN','PIPLK','PIPNT','PIPPT','RESAN','RESLK','RESNT','RESPT','ROAAN','ROALK
-
python如何删除文件中重复的字段
本文实例为大家分享了python如何删除文件中重复字段的具体代码,供大家参考,具体内容如下 原文件内容放在list中,新文件内容按行查找,如果没有出现在list中则写入第三个文件中. import csv filetxt1 = 'E:/gg/log/log1.txt' filecsv1 = 'E:/gg/log/log1.csv' filecsv2 = 'E:/gg/log/log2.csv' filecsv3 = 'E:/gg/log/log3.csv' class operFileCsv()
-
Maven仓库无用文件和文件夹清理的方法实现
众所周知,随着经济社会的发展,我们的物质生活-不好意思,走错片场了- 今天来分享一个实用的代码- 大家都知道我们在使用Maven的时候,都会下载一堆依赖jar包,但是有时候因为网络问题,会下载一堆无用非jar文件.另外还有许多自己本地打包的无效版本等 下面使用代码将Maven仓库中的无用文件夹和不完整的jar包的版本统统删掉 先贴一个效果,如下图
-
Python 统计列表中重复元素的个数并返回其索引值的实现方法
需求:统计列表list1中元素3的个数,并返回每个元素的索引 list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2] 在实际工程中,可能会遇到以上需求,统计元素个数使用list.count()方法即可,不做多余说明 返回每个元素的索引需要做一些转换,简单整理了几个实现方法 1 list.index()方法 list.index()方法返回列表中首个元素的索引,当有重复元素时,可以通过更改index()方法__s
-
基于Python制作一键桌面整理工具
目录 前言 效果展示 开发思路 完整代码 前言 我承认我不是一个爱整理桌面的人,因为我觉得乱糟糟的桌面,反而容易找到文件. 哈哈,可是最近桌面实在是太乱了,自己都看不下去了,几乎占满了整个屏幕.虽然一键整理桌面的软件很多,但是对于其他路径下的文件,我同样需要整理,于是我想到使用Python,完成这个需求. 效果展示 我一共为将文件分为9个大类,分别是图片.视频.音频.文档.压缩文件.常用格式.程序脚本.可执行程序和字体文件. # 不同文件组成的嵌套字典 file_dict = { '图片': [
-
Python去除列表中重复元素的方法
本文实例讲述了Python去除列表中重复元素的方法.分享给大家供大家参考.具体如下: 比较容易记忆的是用内置的set l1 = ['b','c','d','b','c','a','a'] l2 = list(set(l1)) print l2 还有一种据说速度更快的,没测试过两者的速度差别 l1 = ['b','c','d','b','c','a','a'] l2 = {}.fromkeys(l1).keys() print l2 这两种都有个缺点,祛除重复元素后排序变了: ['a', 'c',