使用Pytorch实现two-head(多输出)模型的操作
如何使用Pytorch实现two-head(多输出)模型
1. two-head模型定义
先放一张我要实现的模型结构图:
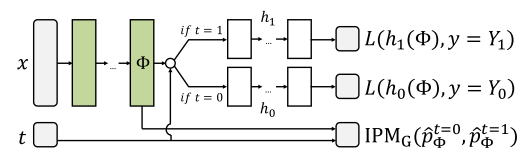
如上图,就是一个two-head模型,也是一个但输入多输出模型。该模型的特点是输入一个x和一个t,h0和h1中只有一个会输出,所以可能这不算是一个典型的多输出模型。
2.实现所遇到的困难 一开始的想法:
这不是很简单嘛,做一个判断不就完了,t=0时模型为前半段加h0,t=1时模型为前半段加h1。但实现的时候傻眼了,发现在真正前向传播的时候t是一个tensor,有0有1,没法儿进行判断。
灵机一动,又生一法:把这个模型变为三个模型,前半段是一个模型(r),后面的h0和h1分别为另两个模型。把数据集按t=0和1分开,分别训练两个模型:r+h0和r+h1。
但是后来搜如何进行模型串联,发现极为麻烦。
3.解决方案
后来在pytorch的官方社区中看到一个极为简单的方法:
(1) 按照一般的多输出模型进行实现,代码如下:
def forward(self, x):
#三层的表示层
x = F.elu(self.fcR1(x))
x = F.elu(self.fcR2(x))
x = F.elu(self.fcR3(x))
#two-head,两个head分别进行输出
y0 = F.elu(self.fcH01(x))
y0 = F.elu(self.fcH02(y0))
y0 = F.elu(self.fcH03(y0))
y1 = F.elu(self.fcH11(x))
y1 = F.elu(self.fcH12(y1))
y1 = F.elu(self.fcH13(y1))
return y0, y1
这样就相当实现了一个多输出模型,一个x同时输出y0和y1.
训练的时候分别训练,也即分别建loss,代码如下:
f_out_y0, _ = net(x0)
_, f_out_y1 = net(x1)
#实例化损失函数
criterion0 = Loss()
criterion1 = Loss()
loss0 = criterion0(f_y0, f_out_y0, w0)
loss1 = criterion1(f_y1, f_out_y1, w1)
print(loss0.item(), loss1.item())
#对网络参数进行初始化
optimizer.zero_grad()
loss0.backward()
loss1.backward()
#对网络的参数进行更新
optimizer.step()
先把x按t=0和t=1分为x0和x1,然后分别送入进行训练。这样就实现了一个two-head模型。
4.后记
我自以为多输出模型可以分为以下两类:
多个输出不同时获得,如本文情况。
多个输出同时获得。
多输出不同时获得的解决方法上文已说明。多输出同时获得则可以通过把y0和y1拼接起来一起输出来实现。
补充:PyTorch 多输入多输出模型构建
本篇教程基于 PyTorch 1.5版本
直接上代码!
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.distributed as dist
import torch.utils.data as data_utils
class Net(nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net, self).__init__()
self.hidden1 = nn.Linear(n_input, n_hidden)
self.hidden2 = nn.Linear(n_hidden, n_hidden)
self.predict1 = nn.Linear(n_hidden*2, n_output)
self.predict2 = nn.Linear(n_hidden*2, n_output)
def forward(self, input1, input2): # 多输入!!!
out01 = self.hidden1(input1)
out02 = torch.relu(out01)
out03 = self.hidden2(out02)
out04 = torch.sigmoid(out03)
out11 = self.hidden1(input2)
out12 = torch.relu(out11)
out13 = self.hidden2(out12)
out14 = torch.sigmoid(out13)
out = torch.cat((out04, out14), dim=1) # 模型层拼合!!!当然你的模型中可能不需要~
out1 = self.predict1(out)
out2 = self.predict2(out)
return out1, out2 # 多输出!!!
net = Net(1, 20, 1)
x1 = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 请不要关心这里,随便弄一个数据,为了说明问题而已
y1 = x1.pow(3)+0.1*torch.randn(x1.size())
x2 = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y2 = x2.pow(3)+0.1*torch.randn(x2.size())
x1, y1 = (Variable(x1), Variable(y1))
x2, y2 = (Variable(x2), Variable(y2))
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
loss_func = torch.nn.MSELoss()
for t in range(5000):
prediction1, prediction2 = net(x1, x2)
loss1 = loss_func(prediction1, y1)
loss2 = loss_func(prediction2, y2)
loss = loss1 + loss2 # 重点!
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 100 == 0:
print('Loss1 = %.4f' % loss1.data,'Loss2 = %.4f' % loss2.data,)
至此搞定!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
如何使用Pytorch搭建模型
1 模型定义 和TF很像,Pytorch也通过继承父类来搭建模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化模型内部结构和进行推理.其它功能比如计算loss和训练函数,你也可以继承在里面,当然这是可选的.下面搭建一个判别MNIST手写字的Demo,首先给出模型代码: import numpy as np import matplotlib.pyplot as plt import
-
pytorch构建多模型实例
pytorch构建双模型 第一部分:构建"se_resnet152","DPN92()"双模型 import numpy as np from functools import partial import torch from torch import nn import torch.nn.functional as F from torch.optim import SGD,Adam from torch.autograd import Variable fro
-

详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰. 希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式. 比如这里给出 很显然,这里我们只需要假定 这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可. 但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢? 只将一个x作为输入
-
pytorch模型存储的2种实现方法
1.保存整个网络结构信息和模型参数信息: torch.save(model_object, './model.pth') 直接加载即可使用: model = torch.load('./model.pth') 2.只保存网络的模型参数-推荐使用 torch.save(model_object.state_dict(), './params.pth') 加载则要先从本地网络模块导入网络,然后再加载参数: from models import AgeModel model = AgeModel()
-
使用Pytorch实现two-head(多输出)模型的操作
如何使用Pytorch实现two-head(多输出)模型 1. two-head模型定义 先放一张我要实现的模型结构图: 如上图,就是一个two-head模型,也是一个但输入多输出模型.该模型的特点是输入一个x和一个t,h0和h1中只有一个会输出,所以可能这不算是一个典型的多输出模型. 2.实现所遇到的困难 一开始的想法: 这不是很简单嘛,做一个判断不就完了,t=0时模型为前半段加h0,t=1时模型为前半段加h1.但实现的时候傻眼了,发现在真正前向传播的时候t是一个tensor,有0有1,没法儿
-
Pytorch中实现只导入部分模型参数的方式
我们在做迁移学习,或者在分割,检测等任务想使用预训练好的模型,同时又有自己修改之后的结构,使得模型文件保存的参数,有一部分是不需要的(don't expected).我们搭建的网络对保存文件来说,有一部分参数也是没有的(missed).如果依旧使用torch.load(model.state_dict())的办法,就会出现 xxx expected,xxx missed类似的错误.那么在这种情况下,该如何导入模型呢? 好在Pytorch中的模型参数使用字典保存的,键是参数的名称,值是参数的具体数
-
解决Pytorch 加载训练好的模型 遇到的error问题
这是一个非常愚蠢的错误 debug的时候要好好看error信息 提醒自己切记好好对待error!切记!切记! -----------------------分割线---------------- pytorch 已经非常友好了 保存模型和加载模型都只需要一条简单的命令 #保存整个网络和参数 torch.save(your_net, 'save_name.pkl') #加载保存的模型 net = torch.load('save_name.pkl') 因为我比较懒我就想直接把整个网络都保存下来,然
-
Pytorch distributed 多卡并行载入模型操作
一.Pytorch distributed 多卡并行载入模型 这次来介绍下如何载入模型. 目前没有找到官方的distribute 载入模型的方式,所以采用如下方式. 大部分情况下,我们在测试时不需要多卡并行计算. 所以,我在测试时只使用单卡. from collections import OrderedDict device = torch.device("cuda") model = DGCNN(args).to(device) #自己的模型 state_dict = torch.
-
PyTorch零基础入门之构建模型基础
目录 一.神经网络的构造 二.神经网络中常见的层 2.1 不含模型参数的层 2.2 含模型参数的层 (1)代码栗子1 (2)代码栗子2 2.3 二维卷积层 stride 2.4 池化层 三.LeNet模型栗子 三点提醒: 四.AlexNet模型栗子 Reference 一.神经网络的构造 PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活.Module 类是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型.
-
pytorch常用函数定义及resnet模型修改实例
目录 模型定义常用函数 利用nn.Parameter()设计新的层 nn.Sequential nn.ModuleList() nn.ModuleDict() nn.Flatten 模型修改案例 修改模型层 添加外部输入 模型定义常用函数 利用nn.Parameter()设计新的层 import torch from torch import nn class MyLinear(nn.Module): def __init__(self, in_features, out_features):
-
pytorch 加载(.pth)格式的模型实例
有一些非常流行的网络如 resnet.squeezenet.densenet等在pytorch里面都有,包括网络结构和训练好的模型. pytorch自带模型网址:https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-models/ 按官网加载预训练好的模型: import torchvision.models as models # pretrained=True就可以使用预训练的模型 resnet18 = mod
-
解决pytorch多GPU训练保存的模型,在单GPU环境下加载出错问题
背景 在公司用多卡训练模型,得到权值文件后保存,然后回到实验室,没有多卡的环境,用单卡训练,加载模型时出错,因为单卡机器上,没有使用DataParallel来加载模型,所以会出现加载错误. 原因 DataParallel包装的模型在保存时,权值参数前面会带有module字符,然而自己在单卡环境下,没有用DataParallel包装的模型权值参数不带module.本质上保存的权值文件是一个有序字典. 解决方法 1.在单卡环境下,用DataParallel包装模型. 2.自己重写Load函数,灵活.
-
在Pytorch中使用Mask R-CNN进行实例分割操作
在这篇文章中,我们将讨论mask R-CNN背后的一些理论,以及如何在PyTorch中使用预训练的mask R-CNN模型. 1.语义分割.目标检测和实例分割 之前已经介绍过: 1.语义分割:在语义分割中,我们分配一个类标签(例如.狗.猫.人.背景等)对图像中的每个像素. 2.目标检测:在目标检测中,我们将类标签分配给包含对象的包围框. 一个非常自然的想法是把两者结合起来.我们只想在一个对象周围识别一个包围框,并且找到包围框中的哪些像素属于对象. 换句话说,我们想要一个掩码,它指示(使用颜色或灰
-
ORM模型框架操作mysql数据库的方法
[什么是ORM] ORM 全称是(Object Relational Mapping)表示对象关系映射: 通俗理解可以理解为编程语言的虚拟数据库: [理解ORM] 用户地址信息数据库表与对象的映射 [ORM的重要特性] 1.面向对象的编程思想,方便扩充 2. 少写(几乎不写)sql,提升开发效率 3.支持多种类型的数据库(常用的mysql,pg,oracle等等),方便切换 4.ORM技术已经相当成熟,能解决绝大部分问题 [ORM模型框架的选择] [SQLAlchemy ORM模型] 众所周知,