pandas 使用insert插入一列
把value插入dataframe的指定位置loc中,若插入的数据value已在DataFrame中,则返回 错误ValueError,如想完成重复值的插入需要把allow_duplicates设置为True
insert方法详解
DataFrame.insert(loc, column, value, allow_duplicates=False)
参数:
Raises a ValueError if column is already contained in the DataFrame, unless allow_duplicates is set to True.
Parameters:
loc :参数column插入的位置,如果想插入到第一例则为0,取值范围: 0 <= loc <= len(columns),其中len(columns)为Dataframe的列数
column :给 插入数据value取列名,可为数字,字符串等
value :可以是整数,Series或者数组等
allow_duplicates : 默认 False
1.创建数据
import pandas as pd
import numpy as np
data = {
'school' : ['北京大学', '清华大学', '山西大学', '山西大学', '武汉大学'],
'name' : ['江路离', '沈希梦', '来使鹭', '陈曦冉', '姜浩然'],
'No.' : [20001943, 300044451, 20190006, 20191234, 1242522]
}
# data = list(data) <-> data = list(data.keys)
# data = list(data.values())
frame = pd.DataFrame(data)
print(frame)
结果:

2.插入数据
frame.insert(0, 'num', np.ones(5)) print(frame)
结果:

frame.insert(len(frame.columns), 'list', [x for x in range(5)]) print(frame)
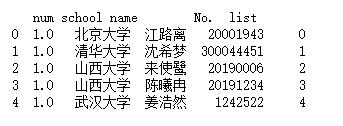
3.插入已存在数据
结果:
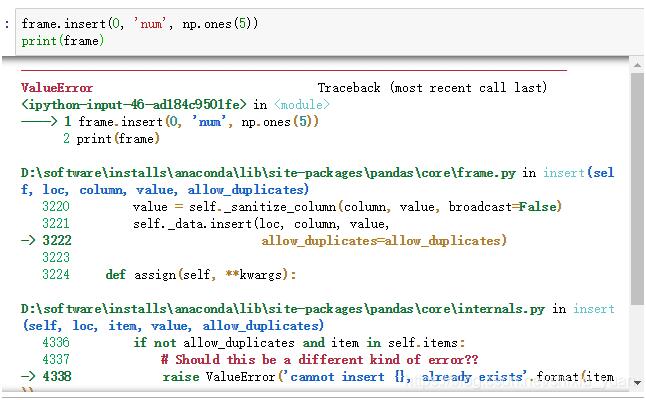
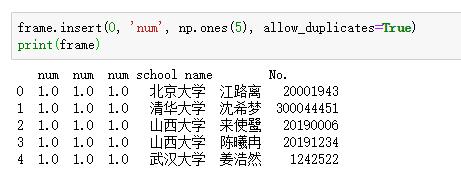
4.把allow_duplicates设置为True,可实现重复值的插入
frame.insert(0, 'num', np.ones(5), allow_duplicates=True) print(frame)
补充:pandas 中的insert(), pop()在DataFrame的指定位置中插入某一列
在pandas中,del、drop和pop方法都可以用来删除数据,insert可以在指定位置插入数据。
可以看看以下示例。
import pandas as pd
from pandas import DataFrame, Series
data = DataFrame({'name':['yang', 'jian', 'yj'], 'age':[23, 34, 22], 'gender':['male', 'male', 'female']})
#data数据
'''
In[182]: data
Out[182]:
age gender name
0 23 male yang
1 34 male jian
2 22 female yj
'''
#删除gender列,不改变原来的data数据,返回删除后的新表data_2。axis为1表示删除列,0表示删除行。inplace为True表示直接对原表修改。
data_2 = data.drop('gender', axis=1, inplace=False)
'''
In[184]: data_2
Out[184]:
age name
0 23 yang
1 34 jian
2 22 yj
'''
#改变某一列的位置。如:先删除gender列,然后在原表data中第0列插入被删掉的列。
data.insert(0, '性别', data.pop('gender'))#pop返回删除的列,插入到第0列,并取新名为'性别'
'''
In[185]: data
Out[186]:
性别 age name
0 male 23 yang
1 male 34 jian
2 female 22 yj
'''
#直接在原数据上删除列
del data['性别']
'''
In[188]: data
Out[188]:
age name
0 23 yang
1 34 jian
2 22 yj
'''
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Pandas DataFrame数据的更改、插入新增的列和行的方法
一.更改DataFrame的某些值 1.更改DataFrame中的数据,原理是将这部分数据提取出来,重新赋值为新的数据. 2.需要注意的是,数据更改直接针对DataFrame原数据更改,操作无法撤销,如果做出更改,需要对更改条件做确认或对数据进行备份. 代码: import pandas as pd df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['
-
pandas 空的dataframe 插入列名的示例
如下所示: colum = ['性别','年龄','M','样本类型'] + muta_list + ['B'] data1 = pd.DataFrame(columns=colum) 以上这篇pandas 空的dataframe 插入列名的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python实现在pandas.DataFrame添加一行
实例如下所示: from pandas import * from random import * df = DataFrame(columns=('lib', 'qty1', 'qty2'))#生成空的pandas表 for i in range(5):#插入一行<span id="transmark" style="display:none;"></span> df.loc[i] = [randint(-1,1) for n in ran
-

pandas 使用insert插入一列
把value插入dataframe的指定位置loc中,若插入的数据value已在DataFrame中,则返回 错误ValueError,如想完成重复值的插入需要把allow_duplicates设置为True insert方法详解 DataFrame.insert(loc, column, value, allow_duplicates=False) 参数: Raises a ValueError if column is already contained in the DataFrame,
-
在Pandas DataFrame中插入一列的方法实例
目录 引言 示例1:插入新列作为第一列 示例2:插入新列作为中间列 示例3:插入新列作为最后一列 补充:按条件选择分组分别赋值 总结 引言 通常,您可能希望在 Pandas DataFrame 中插入一个新列.幸运的是,使用 pandas insert()函数很容易做到这一点,该函数使用以下语法: insert(loc, column, value, allow_duplicates=False) 在哪里: loc: 插入列的索引.第一列是 0. column: 赋予新列的名称. value:
-
SQL Server手工插入标识列的方法
如果我们在标识列中插入值,例如: 复制代码 代码如下: insert member(id,username) values(10,'admin') 则在查询分析器里面会返回错误信息: [plain] 引用内容 服务器: 消息 544,级别 16,状态 1,行 1 当 IDENTITY_Insert 设置为 OFF 时,不能向表 'member' 中的标识列插入显式值. 有的情况我们需要手动插入标识列的值,例如删除了一些记录后,标识列并不连续,而我们又想把它补齐.我们利用一个开关可以
-
Mysql使用insert插入多条记录 批量新增数据
如果要向table1中插入5条记录,下面写法是错误的: INSERT INTO table1 (id,name) VALUES(1,小明,2,小强,3,小杜,4,小李,5,小白); MySQL将会抛出下面的错误 ERROR 1136: Column count doesn't match value count at row 1 而正确的写法应该是这样: INSERT INTO t able1(i,name) VALUES(1,'小明'),(2,'小强'),(3,'小杜'),(4,'小李'),(
-
pandas将DataFrame的几列数据合并成为一列
目录 1.1 方法归纳 1.2 .str.cat函数详解 1.2.1 语法格式: 1.2.2 参数说明: 1.2.3 核心功能: 1.2.4 常见范例: 1.1 方法归纳 使用 + 直接将多列合并为一列(合并列较少): 使用pandas.Series.str.cat方法,将多列合并为一列(合并列较多): 范例如下: dataframe["newColumn"] = dataframe["age"].map(str) + dataframe["phone&q
-
python中pandas.DataFrame对行与列求和及添加新行与列示例
本文介绍的是python中pandas.DataFrame对行与列求和及添加新行与列的相关资料,下面话不多说,来看看详细的介绍吧. 方法如下: 导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFrame(np.random.randn(4, 5), columns=['A', 'B', 'C', 'D', 'E']) DataFrame数据预览: A
-
MyBatis在insert插入操作时返回主键ID的配置(推荐)
很多时候,在向数据库插入数据时,需要保留插入数据的id,以便进行后续的update操作或者将id存入其他表作为外键. 但是,在默认情况下,insert操作返回的是一个int值,并且不是表示主键id,而是表示当前SQL语句影响的行数... 接下来,我们看看MyBatis如何在使用MySQL和Oracle做insert插入操作时将返回的id绑定到对象中. MySQL用法: <insert id="insert" parameterType="com.test.User&qu
-
pandas.DataFrame 根据条件新建列并赋值的方法
实例如下所示: import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'], 'year': [2016,2016,2015,2017,2016, 2016], 'population': [2100, 2300, 1000, 700, 500, 500]} frame = pd.DataFrame(
-
pandas数据框,统计某列数据对应的个数方法
现在要解决的问题如下: 我们有一个数据的表 第7列有许多数字,并且是用逗号分隔的,数字又有一个对应的关系: 我们要得到第7列对应关系的统计,就是每一行的第7列a有多少个,b有多少个 好了,我给的解决方法如下: #!/bin/python #-*-coding:UTF-8-*- import pandas as pd import numpy as np dfidspec = pd.read_table("one.txt")#这个是对应关系的文件 dfmgs = pd.read_tabl
-
pandas 取出表中一列数据所有的值并转换为array类型的方法
如下所示: # -*-coding: utf-8 -*- import pandas as pd #读取csv文件 df=pd.read_csv('A_2+20+DoW+VC.csv') #求'ave_time'的平均值 aveTime=df['ave_time'].mean() #把ave_time这列的缺失值进进行填充,填充的方法是按这一列的平均值进行填充 df2=df.fillna(aveTime) #取表中的第3列的所有值 col=df2.iloc[:,2] #取表中的第3列的所有值 a