C语言字符串的模式匹配之BF与KMP
目录
- BF算法(Brute-Force算法)
- KMP算法(快速的)
- KMP—yxc模板
- 总结
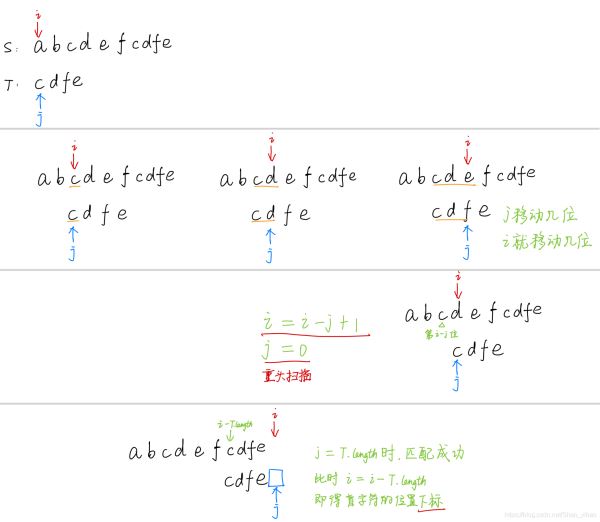
确定一个子串(模式串)在主串中第一次出现的位置。
BF算法(Brute-Force算法)
BF算法即朴素的简单匹配法,采用的是穷举的思路。从主串的每一个字符开始依次与模式串的字符进行比较。

int index_BF(SeqString S, SeqString T, int begin)//从S的第begin位(下标)开始进行匹配判断
{
int i = begin, j = 0;
while (i < S.length && j < T.length)
{
if (S.ch[i] == T.ch[j])
{
i ++;
j ++;//比较下一个字符
}
else
{
i = i - j + 1;
j = 0;//模式串回溯到起点
}
}
if (j == T.length) return i - T.length; //匹配成功,则返回该模式串在主串中第一次出现的位置下标
else return -1;
}
int index_BF(char S[], char T[], int beg)
{
int i = beg, j = 0;
while (i < strlen(S) && j < strlen(T))
{
if (S[i] == T[j])
{
i ++;
j ++;
}
else
{
i = i - j + 1;
j = 0;
}
}
if (i == strlen(S)) return i - strlen(T);
else return -1;
}
int main()
{
char str1[10] = "abcde";
char str2[10] = "cde";
printf("%d", index_BF(str1, str2, 0));
return 0;
}
KMP算法(快速的)
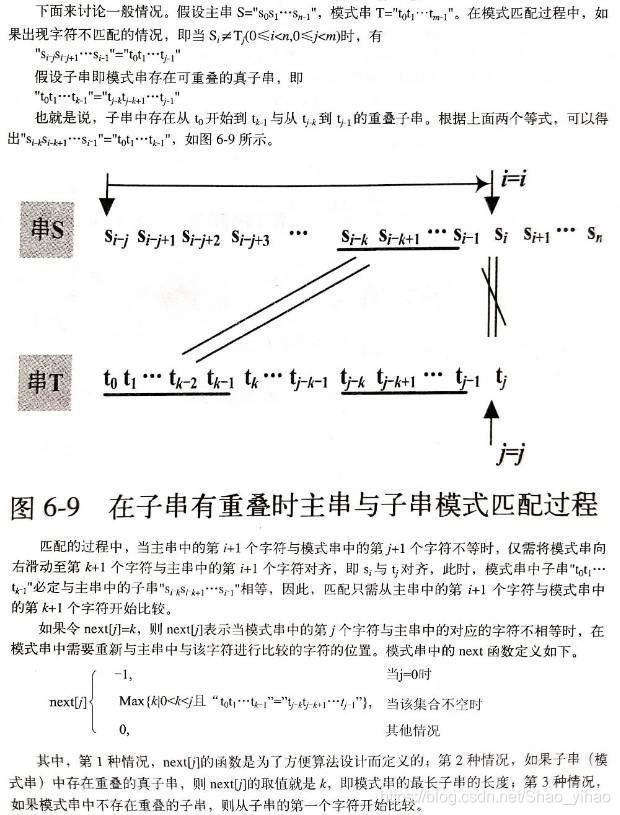
基本思想为:主串的指针 i i i不必回溯,利用已经得到前面“部分匹配”的结果,将模式串向右滑动若干个字符,继续与主串中的当前字符进行比较,减少了一些不必要的比较。
时间复杂度为 O ( n + m )
KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组。
首先要明白什么是字符串的前缀和后缀。
如果字符串A和B,存在A=BS,其中S是任意的非空字符串,那就称B为A的前缀。例如,”Harry”的前缀包括{”H”, ”Ha”,”Har”, ”Harr”},我们把所有前缀组成的集合,称为字符串的前缀集合。
同样可以定义后缀A=SB,其中S是任意的非空字符串,那就称B为A的后缀,例如,”Potter”的后缀包括{”otter”, ”tter”, ”ter”, ”er”, ”r”},然后把所有后缀组成的集合,称为字符串的后缀集合。
要注意的是,字符串本身并不是自己的前缀或后缀。
PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。
比如,对于字符串”ababa”,它的前缀集合为{”a”, ”ab”, ”aba”, ”abab”},它的后缀集合为{”baba”, ”aba”, ”ba”, ”a”}, 两个集合的交集为{”a”, ”aba”},其中最长的元素为”aba”,长度为3,即该字符串在PMT表中的值为3。性质为:该字符串前3个字符与后三个字符相同。
如果模式串有 j个字符,则PMT表中就有 j 个数值。其中第一个数值总为0。



int index_KMP(SeqString S, SeqString T, int begin)//从S的第begin位(下标)开始进行匹配判断
{
int i = begin, j = 0;
while (i < S.length && j < T.length)
{
if (j == -1 || S.ch[i] == T.ch[j])
{
i ++;
j ++;
}
else j = next[j];//即PMT[j-1]
}
if (j == T.length) return i - T.length; //匹配成功,则返回该模式串在主串中第一次出现的位置下标
else return -1;
}
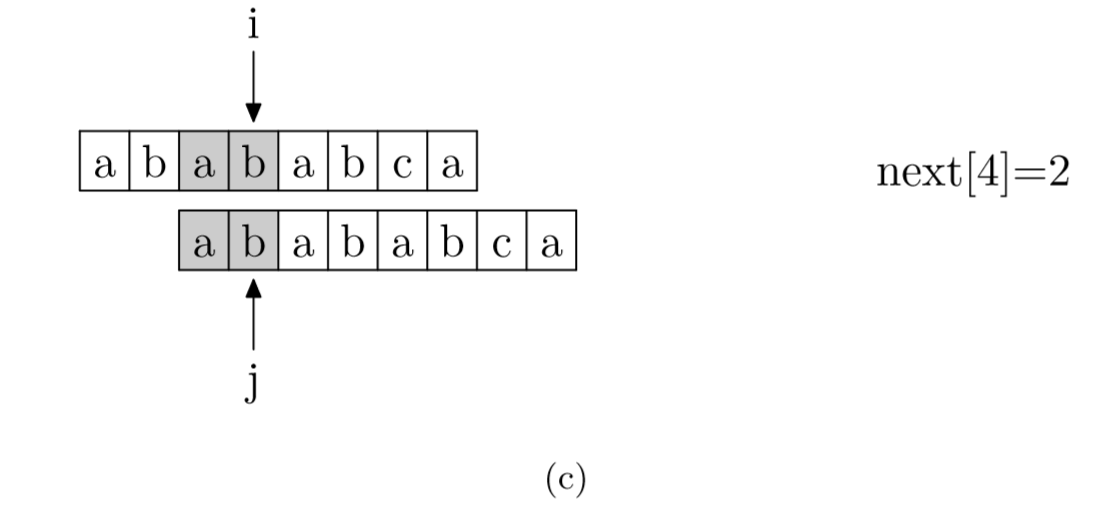
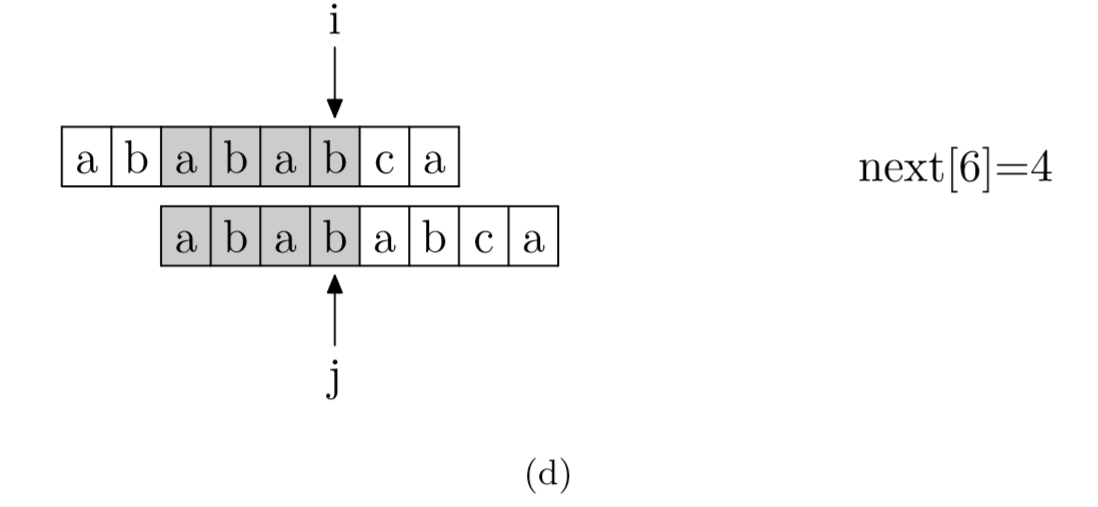
那么该如何求出next数组呢?

其实,求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度。
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前i位置的next值。如下图所示。



void GetNext(SeqString T, int next[])
{
next[0] = -1;
int j = 0, k = -1;//起始时k落后j一位
while (j < T.length)//j遍历一遍模式串,对于每个字符得到该位置的next数组的值
{
if (k == -1 || T.ch[j] == T.ch[k])
{
j ++;
next[j] = k + 1;//将j视为指向一个子串(后缀)结束后的下一个字符,k指向一个子串(前缀)的最后一个字符,则这两个子串的重叠部分的长度(k下标从0开始)即PMT[j-1]的值
k ++;
/*也可以简便地写为(易记):
j ++;
k ++;
next[j] = k;
最简单的形式为:
next[++ j] = ++ k;
*/
}
else k = next[k];//k回溯,即将第二个子串(右滑)(减小匹配的前缀长度)
}
}
即:
#include <stdio.h>
#include <string.h>
int next[10];//全局数组
void GetNext(char T[])
{
int j = 0, k = -1;
next[0] = -1;
while (j < strlen(T))
{
if (k == -1 || T[j] == T[k])
{
j ++;
next[j] = k + 1;
k ++;
}
else k = next[k];
}
}
int index_KMP(char S[], char T[], int begin)//从S的第begin位(下标)开始进行匹配判断
{
int i = begin, j = 0;
while (i < strlen(S) && strlen(T))
{
if (j == -1 || S[i] == T[j])
{
i ++;
j ++;
}
else j = next[j];//即PMT[j-1]
}
if (j == strlen(T)) return i - strlen(T); //匹配成功,则返回该模式串在主串中第一次出现的位置下标
else return -1;
}
int main()
{
char str1[10] = "abcde";
char str2[10] = "cde";
GetNext(str2);
printf("%d", index_KMP(str1, str2, 0));
return 0;
}
求next数组的方法也可进行优化:
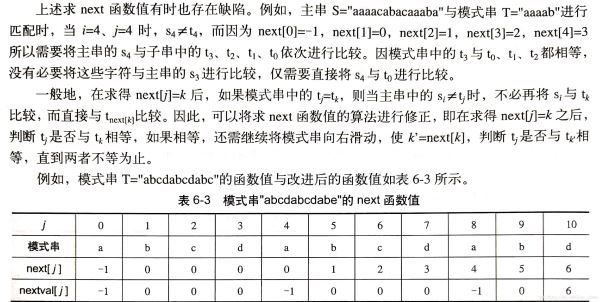
void GetNextVal(SeqString T, int nextval[])
{
nextval[0] = -1;
int j = 0, k = -1;
while (j < T.length)
{
if (k == -1 || T.ch[j] == T.ch[k])
{
j ++;
k ++;
if (T.ch[j] != T.ch[k])
nextval[j] = k;
else
nextval[j] = nextval[k];
}
else k = nextval[k];
}
}
即:
int nextval[10];//全局数组
void GetNextVal(char T[])
{
int j = 0, k = -1;
nextval[0] = -1;
while (j < strlen(T))
{
if (k == -1 || T[j] == T[k])
{
j ++;
k ++;
if (T[j] != T[k]) nextval[j] = k;
else nextval[j] = nextval[k];
}
else k = nextval[k];
}
}
int index_KMP(char S[], char T[], int begin)//从S的第begin位(下标)开始进行匹配判断
{
int i = begin, j = 0;
while (i < strlen(S) && strlen(T))
{
if (j == -1 || S[i] == T[j])
{
i ++;
j ++;
}
else j = nextval[j];
}
if (j == strlen(T)) return i - strlen(T); //匹配成功,则返回该模式串在主串中第一次出现的位置下标
else return -1;
}
int main()
{
char str1[10] = "abcde";
char str2[10] = "bcde";
GetNextVal(str2);
printf("%d", index_KMP(str1, str2, 0));
return 0;
}
KMP—yxc模板
字符串从数组下标1开始存
#include <iostream>
using namespace std;
const int M = 1000010, N = 100010;
char S[M], p[N];
int ne[N]; //全局变量数组,初始化全为0
int main()
{
int m, n;
cin >> m;
for (int i = 1; i <= m; i ++) cin >> S[i];
cin >> n;
for (int i = 1; i <= n; i ++) cin >> p[i];//主串与模式串均由数组下标1开始存储
// 也可以简写为 cin >> m >> S + 1 >> n >> p + 1;
for (int i = 2, j = 0; i <= n; i ++)//求模式串各字符处的next值,即求串p[1~i]的前后缀最大交集的长度
{ //由于字符串由下标1开始存储,next[i]+1也是模式串下次比较的起始下标
while (j && p[i] != p[j + 1]) j = ne[j];//记录的最大交集的长度减小,直到为0,表示p[1~i]前后缀无交集
if (p[i] == p[j + 1]) j ++;//该位匹配成功
ne[i] = j;//j即该位的ne值
}
for (int i = 1, j = 0; i <= m; i ++)//遍历一遍主串
{
while (j && S[i] != p[j + 1]) j = ne[j];//不匹配且并非无路可退,则j后滑。j==0意味着当前i所指的字符与模式串的第一个字符都不一样,只能等该轮循环结束i++,之后再比较
if (S[i] == p[j + 1]) j ++;//该位匹配成功
if (j == n)//主串与模式串匹配成功
{
cout << i - n << ' ';//匹配时,输出 模式串首元素在主串中的下标
j = ne[j];//j后滑,准备继续寻找下一个匹配处
}
}
return 0;
}
字符串从数组下标为开始存
const int N = 1000010;
char s[N], p[N];
int ne[N];
int main()
{
int n, m;
cin >> m >> p >> n >> s;
ne[0] = -1;//ne[0]初始化为-1
for (int i = 1, j = -1; i < m; i ++ )//从模式串的第2位2开始求next值
{
while (j != -1 && p[j + 1] != p[i]) j = ne[j];
if (p[j + 1] == p[i]) j ++ ;
ne[i] = j;
}
for (int i = 0, j = -1; i < n; i ++ )//遍历一遍主串
{
while (j != -1 && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == m - 1)//扫描到模式串结尾,说明匹配完成
{
cout << i - j << ' ';
j = ne[j];
}
}
return 0;
}
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

C 语言基础之C 语言三大语句注意事项
目录 1.分支语句 2.if语句 3.switch语句 3.1语句结构 4.循环语句 4.1 while循环(do while类似) 4.2 do while循环 4.3 for循环 5.goto语句 在今天的内容介绍之前我们要知道:C语言中,由一个分号( ; )隔开的就是一条语句. 很好理解,如: int a=3;//语句1 printf("请大家多多指教!");//语句2 ;//语句3----空语句 今天讲解的内容,则是自己对于这三种语句一些细节的介绍.(并不是具体讲解这些语句)
-
C 语言基础实现青蛙跳台阶和汉诺塔问题
目录 一.青蛙跳台阶 题目 思路 分析 1. 从跳法次数分析 2. 从过程分析 二.青蛙跳台阶变式1 题目 分析 三.青蛙跳台阶变式2 题目 分析 四.汉诺塔问题(求步数) 题目 思路 分析 五.汉诺塔问题(求移动过程) 题目 思路 分析 一.青蛙跳台阶 题目 一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶.求该青蛙跳上一个 n 级的台阶总共有多少种跳法 思路 遇见题目我们可以在纸上先动手画画,把最简单的几种方式列出来,作比较,找规律. 分析 按照上面表格可以从跳法次数,过程,或者两者结合找规
-
C语言 函数缺省参数详情
目录 一.函数简介 1.函数声明 2.函数定义 3.函数调用 4.函数形参和实参 二.函数缺省参数 1.函数全缺省参数 2.函数半缺省参数 三.注意事项 一.函数简介 1.函数声明 函数声明只是一个空壳,不会有具体的函数实现,而定义要实现函数的实现,例如: int sub(int x,int y); //只需要声明即可,不需要实现这个函数的功能 2.函数定义 函数的定义需要实现这个函数的功能,例如: int sub(int x,int y) ////需要实现这个函数的功能 { return (x
-
C语言中的常量详解
目录 C语言中的常量 字面常量 #define定义的标识符常量 枚举常量 C语言中的常量 C编程中的常量是一些固定的值,它在整个程序运行过程中无法被改变. 字面常量 字面常量是直接写出的固定值,它包含C语言中可用的数据类型,可分为整型常量,字符常量等.如:9.9,"hello"等就属于这一类常量. ##const修饰的常变量 有的时候我们希望定义这么一种变量:值不能被修改,在整个作用域中都维持原值.为了满足用户需求,C语言标准提供了const关键字.在定义变量的同时,在变量名之前加上c
-
C语言指针笔试题全面解析
目录 前言 一.指针笔试题 1.题目如图: 2.题目如图: 3.题目如图: 4.题目如图: 5.题目如图: 6.题目如图: 7.题目如图: 8.题目如图: 总结 前言 通过8道指针笔试题的解析,可以充分的复习到指针的相关知识,并且题目中会结合许多之前的相关知识,希望通过本篇文章,对大家所学的知识进行一个复习. 提示:以下是本篇文章正文内容,下面案例可供参考 一.指针笔试题 1.题目如图: 逐条语句分析: ①.定义了一个大小为5的整型数组,并进行了初始化 ②.定义了一个整型指针变量ptr用来存放地
-
C语言位运算符的具体使用
目录 布尔位运算符 移位运算符 对于更多紧凑的数据,C 程序可以用独立的位或多个组合在一起的位来存储信息.文件访问许可就是一个常见的应用案例.位运算符允许对一个字节或更大的数据单位中独立的位做处理:可以清除.设定,或者倒置任何位或多个位.也可以将一个整数的位模式(bit pattern)向右或向左移动. 整数类型的位模式由一队按位置从右到左编号的位组成,位置编号从 0 开始,这是最低有效位(least significant bit).例如,考虑字符值'*',它的 ASCII 编码为 42,相当
-
C语言:陷阱与缺陷详解
目录 一.前言 二.字符指针 三.边界计算与不对称边界 1.经典错误① 2.经典错误② 3.小结 四.求值顺序 五.运算符&& ||和! 总结 一.前言 二.字符指针 结论一:复制指针并不会复制指针所指向的内容.两个指针所指向位置相同,实际为同一个指针. 结论而:开辟两个数组,即使两个数组内容相同,地址也绝不相同. 三.边界计算与不对称边界 1.经典错误① int main() { int i = 0; int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9,
-
C语言递归之汉诺塔和青蛙跳台阶问题
递归就是一个函数执行过程中调用自己,在c语言中有很多关于递归的经典问题,例如:斐波那契数列问题.汉诺塔问题等,在研究递归问题时我们要注意三点: 1.递归的结束条件 2.递归在每次进行过程中,都得离条件越来越近 3.相邻两次递归调用之间的关联关系 汉诺塔问题: 有三根杆子A, B, C.A杆上有N个(N > 1)穿孔圆盘, 盘的尺寸由下到上依次变小.要求按下列规则将所有圆盘移至C杆: 1.每次只能移动一个圆盘: 2.大盘不能叠在小盘上面,可将圆盘临时置于B杆, 也可将从A杆移出的圆盘重新移回A杆,
-
C 语言基础之C语言的常见关键字
目录 1.auto 2.register 3.signed和unsigned 4.typedef 5.extern 6.拓展 首先我们简单的和这些关键字见见面(被高亮的关键字是今天要介绍的) 这其中有大家熟知的数据类型:int,char,float,double- 也有控制语句用到的:if,for,do- 还有一些就是今天主要介绍的关键字. 至于还有一些新增的关键字,以上表格未曾提到,大家如果想去了解,可自行查找. 个别术语介绍(可先跳过,后文如若遇到不懂,可回来了解) 自动变量:指的是局部作
-
C 语言基础之初识 C 语言常量
目录 1.字面常量 2.const修饰的常变量 3.#define定义的标识符常量(也叫预处理) 4.枚举常量 C语言中的常量分为以下几种: 字面常量 const修饰的常变量 #define定义的标识符常量 枚举常量 1.字面常量 即字面意思不能改变的量.如1就是1,你不能说让1等于2:如人的血型有固定的几种(A,B,O,AB):如人的性别也只分为男性,女性,以及更深奥的一种形态. 在C语言中:1,3.14,'a',"hello"-这些都叫做常量. 2.const修饰的常变量 可以通过
-
关于C语言 const 和 define 区别
目录 一.const 使用 1.const 修饰变量 2.const 修饰指针 3.const 修饰在函数名前面当 4.const 修饰在函数名后面 5.const 修饰函数参数 二.define 使用 1.define 定义常量 2.define 定义函数 3.define 定义多行函数 4.define 防止头文件重复包含 三.const 和 define 区别 四.const 优点 一.const 使用 const 是 constant 的缩写,"恒定不变"的意思.被 const