Python的进程及进程池详解
目录
- 进程
- 进程和程序
- 进程的状态
- Python中的进程
- 创建⼦进程
- 全局变量问题
- 守护进程
- 进程池
- 总结
进程
进程是操作系统分配资源的基本单元,是程序隔离的边界。
进程和程序
程序只是一组指令的集合,它本身没有任何运行的含义,它是静态的。
进程程序的执行实例,是动态的,有自己的生命周期,有创建有撤销,存在是暂时的。
进程和程序不是一一对应的,一个程序可以对应多个进程,一个进程也可以执行一个或者多个程序。
我们可以这样理解:编写完的代码,没有运行时称为程序,正在运行的代码,会启动一个(或多个)进程。

进程的状态
在我们的操作系统⼯作时,任务数往往⼤于cpu核心数,即⼀定有⼀些任务正在执⾏,⽽另外⼀些任务在等待cpu,因此导致了进程有不同的状态。

- 就绪状态:已满⾜运⾏条件,等待cpu执⾏
- 执⾏状态:cpu正在执⾏
- 等待状态:等待某些条件满⾜,比如⼀个程序sleep了,此时就处于等待状态
Python中的进程
在Python中,进程是通过multiprocessing多进程模块来创建的,multiprocessing模块提供了⼀个Process类来创建进程对象。
创建⼦进程
Process语法结构:
Process(group, target, name, args, kwargs)
group:指定进程组,⼤多数情况下⽤不到target:表示调用对象,即子进程要执行的任务name:子进程的名称,可以不设定args:给target指定的函数传递的参数,以元组的⽅式传递kwargs:给target指定的函数传递命名参数
Process常用方法
p.start()启动进程,并调用该子进程中的p.run()方法p.join(timeout):主进程等待⼦进程执⾏结束再结束,timeout是可选的超时时间is_alive():判断进程⼦进程是否还存活p.run()进程启动时运行的方法,正是它去调用target指定的函数p.terminate()⽴即终⽌⼦进程
Process创建的实例对象的常⽤属性
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
pid:当前进程的pid(进程号)
import multiprocessing
import os
import time
def work(name):
print("子进程work正在运行......")
time.sleep(0.5)
print(name)
# 获取进程的名称
print("子进程name", multiprocessing.current_process())
# 获取进程的pid
print("子进程pid", multiprocessing.current_process().pid, os.getpid())
# 获取父进程的pid
print("父进程pid", os.getppid())
print("子进程运行结束......")
if __name__ == '__main__':
print("主进程启动")
# 获取进程的名称
print("主进程name", multiprocessing.current_process())
# 获取进程的pid
print("主进程pid", multiprocessing.current_process().pid, os.getpid())
# 创建进程
p = multiprocessing.Process(group=None, target=work, args=("tigeriaf", ))
# 启动进程
p.start()
print("主进程结束")

通过上述代码我们发现,multiprocessing.Process帮我们创建一个子进程,并且成功运行,但是我们发现,在子进程还没执行完的时候主进程就已经死了,那么这个子进程在主进程结束后就是一个孤儿进程,那么我们可以让主进程等待子进程结束后再结束吗?答案是可以的。 那就是通过p.join(),join()的作用是让主进程等子进程执行完再退出。
import multiprocessing
import os
import time
def work(name):
print("子进程work正在运行......")
time.sleep(0.5)
print(name)
# 获取进程的名称
print("子进程name", multiprocessing.current_process())
# 获取进程的pid
print("子进程pid", multiprocessing.current_process().pid, os.getpid())
# 获取父进程的pid
print("父进程pid", os.getppid())
print("子进程运行结束......")
if __name__ == '__main__':
print("主进程启动")
# 获取进程的名称
print("主进程name", multiprocessing.current_process())
# 获取进程的pid
print("主进程pid", multiprocessing.current_process().pid, os.getpid())
# 创建进程
p = multiprocessing.Process(group=None, target=work, args=("tigeriaf", ))
# 启动进程
p.start()
p.join()
print("主进程结束")
运行结果:
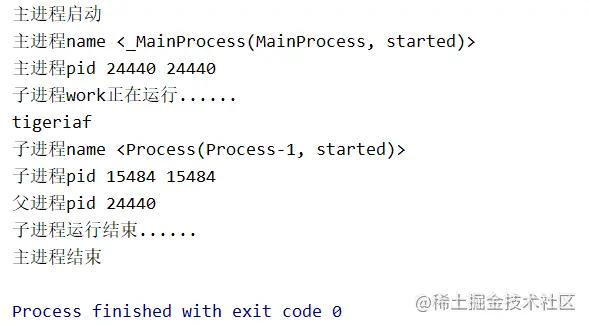
可以看出,主进程是在子进程结束后才结束的。
全局变量问题
全局变量在多个进程中不共享,进程之间的数据是独立的,默认情况下互不影响。
import multiprocessing
# 定义全局变量
num = 99
def work1():
print("work1正在运行......")
global num # 在函数内部声明使⽤全局变量num
num = num + 1 # 对num值进⾏+1
print("work1 num = {}".format(num))
def work2():
print("work2正在运行......")
print("work2 num = {}".format(num))
if __name__ == '__main__':
# 创建进程p1
p1 = multiprocessing.Process(group=None, target=work1)
# 启动进程p1
p1.start()
# 创建进程p2
p2 = multiprocessing.Process(group=None, target=work2)
# 启动进程p2
p2.start()
运行结果:
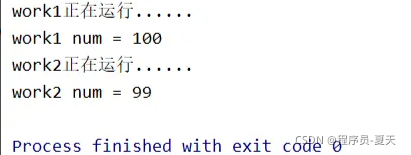
从运⾏结果可以看出,work1()函数对全局变量num的修改,在work2中并没有获取到,⽽还是原来的99,所以,进程之间是不够共享变量的。
守护进程
上面说到,可以使用p.join()让主进程等待子进程结束后再结束,那么可不可以让子进程在主进程结束的时候就结束呢?答案是肯定的。 我们可以使用p.daemon = True或者p2.terminate()进行设置:
import multiprocessing
import time
def work1():
print("work1正在运行......")
time.sleep(4)
print("work1运行完毕")
def work2():
print("work2正在运行......")
time.sleep(10)
print("work2运行完毕")
if __name__ == '__main__':
# 创建进程p1
p1 = multiprocessing.Process(group=None, target=work1)
# 启动进程p1
p1.start()
# 创建进程p2
p2 = multiprocessing.Process(group=None, target=work2)
# 设置p2守护主进程
# 第⼀种⽅式
# p2.daemon = True 在start()之前设置,不然会抛异常
# 启动进程p2
p2.start()
time.sleep(2)
print("主进程运行完毕!")
# 第⼆种⽅式
p2.terminate()
执行结果如下:
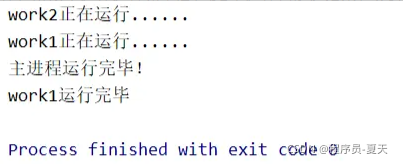
由于p2设置了守护主进程,所以主进程运行完毕后,p2子进程也随之结束,work2任务停止,而work1继续运行至结束。
进程池
当需要创建的⼦进程数量不多时, 可以直接利⽤multiprocessing.Process动态生成多个进程, 但如果要创建很多进程时,⼿动创建的话⼯作量会非常大,此时就可以⽤到multiprocessing模块提供的Pool去创建一个进程池。
multiprocessing.Pool常⽤函数:
apply_async(func, args, kwds):使⽤⾮阻塞⽅式调⽤func(任务并⾏执⾏),args为传递给func的参数列表,kwds为传递给func的关键字参数列表apply(func, args, kwds):使⽤阻塞⽅式调⽤func,必须等待上⼀个进程执行完任务后才能执⾏下⼀个进程,了解即可,几乎不用close():关闭Pool,使其不再接受新的任务terminate():不管任务是否完成,⽴即终⽌join():主进程阻塞,等待⼦进程的退出,必须在close或terminate之后使⽤
初始化Pool时,可以指定⼀个最⼤进程数,当有新的任务提交到Pool中时,如果进程池还没有满,那么就会创建⼀个新的进程⽤来执⾏该任务,但如果进程池已满(池中的进程数已经达到指定的最⼤值),那么该任务就会等待,直到池中有进程结束才会创建新的进程来执⾏。
from multiprocessing import Pool
import time
def work(i):
print("work'{}'执行中......".format(i), multiprocessing.current_process().name, multiprocessing.current_process().pid)
time.sleep(2)
print("work'{}'执行完毕......".format(i))
if __name__ == '__main__':
# 创建进程池
# Pool(3) 表示创建容量为3个进程的进程池
pool = Pool(3)
for i in range(10):
# 利⽤进程池同步执⾏work任务,进程池中的进程会等待上⼀个进程执行完任务后才能执⾏下⼀个进程
# pool.apply(work, (i, ))
# 使⽤异步⽅式执⾏work任务
pool.apply_async(work, (i, ))
# 进程池关闭之后不再接受新的请求
pool.close()
# 等待po中所有子进程结束,必须放在close()后面, 如果使⽤异步⽅式执⾏work任务,主线程不再等待⼦线程执⾏完毕再退出!
pool.join()
执行结果为:
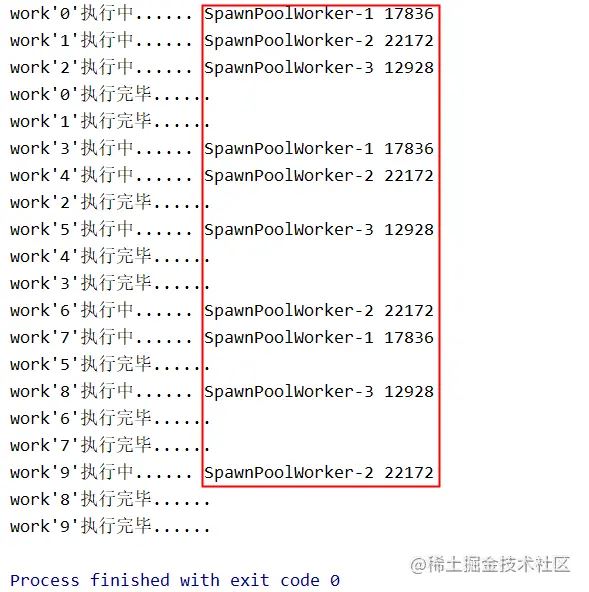
从结果我们可以看出,只有3个子进程在执行任务,此处我们使用的是异步⽅式(pool.apply_async(work, (i, )))执⾏work任务,如果是以同步方式(pool.apply(work, (i, )))执行,进程池中的进程会等待上⼀个进程执行完任务后才能执⾏下⼀个进程。
总结
本篇只介绍了什么是进程、进程与程序的关系、进程的创建与使用、创建进程池等,并没有介绍进程同步及进程通信等,下篇文章将会介绍。
相关推荐
-
python 进程池pool使用详解
和选用线程池来关系多线程类似,当程序中设置到多进程编程时,Python 提供了更好的管理多个进程的方式,就是使用进程池. 在利用 Python 进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间. 当被操作对象数目不大时,可以直接利用 multiprocessing 中的 Process 动态生成多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效. Pool可以提供指定数量的进程供用户调用,当
-
Python进程池Pool应用实例分析
本文实例讲述了Python进程池Pool应用.分享给大家供大家参考,具体如下: 当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法. 初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求:但如果池中的进程数已经达到指定的最大值,那么该请求就会
-
解决Python 进程池Pool中一些坑
1 from multiprocessing import Pool,Queue. 其中Queue在Pool中不起作用,具体原因未明. 解决方案: 如果要用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue, 与multiprocessing中的Queue不同 q=Manager().Queue()#Manager中的Queue才能配合Pool po = Pool() # 无穷多进程 2 使用进程池,在进程中调用io读写操作. 例如: p=Pool()
-
Python多进程multiprocessing、进程池用法实例分析
本文实例讲述了Python多进程multiprocessing.进程池用法.分享给大家供大家参考,具体如下: 内容相关: multiprocessing: 进程的创建与运行 进程常用相关函数 进程池: 为什么要有进程池 进程池的创建与运行:串行.并行 回调函数 多进程multiprocessing: python中的多进程需要使用multiprocessing模块 多进程的创建与运行: 1.进程的创建:进程对象=multiprocessing.Process(target=函数名,args=(参
-
python进程池实现的多进程文件夹copy器完整示例
本文实例讲述了python进程池实现的多进程文件夹copy器.分享给大家供大家参考,具体如下: 应用:文件夹copy器(多进程版) import multiprocessing import os import time import random def copy_file(queue, file_name,source_folder_name, dest_folder_name): """copy文件到指定的路径""" f_read = op
-
Python基于进程池实现多进程过程解析
1.注意:pool必须在 if __name__ == '__main__' 下面运行,不然会报错 2.多进程内出现错误会直接跳过该进程,并且默认不会打印错误信息 3.if__name__下面的数据需要通过参数传入主函数里面,不然主函数获取不到该数据值而报错. 4.若不通过传参形式传入数据,可以定义全局变量.但是全局变量的值不能在多进程里面进行修改. 代码如下 from multiprocessing import Pool # 进程池,用于多进程 import os # 用于获取当前执行的文件
-
对Python中创建进程的两种方式以及进程池详解
在Python中创建进程有两种方式,第一种是: from multiprocessing import Process import time def test(): while True: print('---test---') time.sleep(1) if __name__ == '__main__': p=Process(target=test) p.start() while True: print('---main---') time.sleep(1) 上面这段代码是在window
-
构建高效的python requests长连接池详解
前文: 最近在搞全网的CDN刷新系统,在性能调优时遇到了requests长连接的一个问题,以前关注过长连接太多造成浪费的问题,但因为系统都是分布式扩展的,针对这种各别问题就懒得改动了. 现在开发的缓存刷新系统,对于性能还是有些敏感的,我后面会给出最优的http长连接池构建方式. 老生常谈: python下的httpclient库哪个最好用? 我想大多数人还是会选择requests库的.原因么?也就是简单,易用! 如何蛋疼的构建reqeusts的短连接请求: python requests库默认就
-
Docker守护进程安全配置项目详解
本文将为大家介绍docker守护进程的相关安全配置项目. 一.测试环境 1.1 安装 CentOS 7 CentOS Linux release 7.7.1908 (Core) 升级内核,重启 # yum update kernel [root@localhost docker]# uname -a Linux localhost 3.10.0-1062.12.1.el7.x86_64 #1 SMP Tue Feb 4 23:02:59 UTC 2020 x86_64 x86_64 x86_64
-
用python构建IP代理池详解
目录 概述 提供免费代理的网站 代码 导包 网站页面的url ip地址 检测 整理 必要参数 总代码 总结 概述 用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉.对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问:而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题. 目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差
-

Python封装数据库连接池详解
目录 一.数据库封装 1.1数据库基本配置 1.2 编写单例模式注解 1.3 构建连接池 1.4 封装Python操作MYSQL的代码 二.连接池测试 场景一:同一个实例,执行2次sql 场景二:依次创建2个实例,各自执行sql 场景三:启动2个线程,但是线程在创建连接池实例时,有时间间隔 场景四:启动2个线程,线程在创建连接池实例时,没有时间间隔 前言: 线程安全问题:当2个线程同时用到线程池时,会同时创建2个线程池.如果多个线程,错开用到线程池,就只会创建一个线程池,会共用一个线程池.我用的
-
Python中协程用法代码详解
本文研究的主要是python中协程的相关问题,具体介绍如下. Num01–>协程的定义 协程,又称微线程,纤程.英文名Coroutine. 首先我们得知道协程是啥?协程其实可以认为是比线程更小的执行单元. 为啥说他是一个执行单元,因为他自带CPU上下文.这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程. 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的. Num02–>协程和线程的差异 那么这个过程看起来和线程差不多.其实不然, 线程切换从系统层面远不止保存和恢复 CP
-
Python定时任务APScheduler的实例实例详解
APScheduler 支持三种调度任务:固定时间间隔,固定时间点(日期),Linux 下的 Crontab 命令.同时,它还支持异步执行.后台执行调度任务. 一.基本架构 触发器 triggers:设定触发任务的条件 描述一个任务何时被触发,按日期或按时间间隔或按 cronjob 表达式三种方式触发 任务存储器 job stores:存放任务,可以放内存(默认)或数据库 注:调度器之间不能共享任务存储器 执行器 executors:用于执行任务,可设定执行模式 将指定的作业提交到线程池或者进程
-
Python 列表与链表的区别详解
目录 python 列表和链表的区别 列表的实现机制 链表 链表与列表的差异 python 列表和链表的区别 python 中的 list 并不是我们传统意义上的列表,传统列表--通常也叫作链表(linked list)是由一系列节点来实现的,其中每个节点都持有一个指向下一节点的引用. class Node: def __init__(self, value, next=None): self.value = value self.next = next 接下来,我们就可以将所有的节点构造成一个
-
Python OpenCV使用dlib进行多目标跟踪详解
目录 1.使用dlib进行多目标跟踪 2.项目结构 3.dlib多对象跟踪的简单“朴素”方法 4.快速.高效的dlib多对象跟踪实现 5.完整代码 6.改进和建议 在本教程中,您将学习如何使用 dlib 库在实时视频中有效地跟踪多个对象. 我们当然可以使用 dlib 跟踪多个对象:但是,为了获得可能的最佳性能,我们需要利用多处理并将对象跟踪器分布在处理器的多个内核上. 正确利用多处理使我们能够将 dlib 多对象跟踪每秒帧数 (FPS) 提高 45% 以上! 1.使用 dlib 进行多目标跟踪
-
nginx源码分析线程池详解
nginx源码分析线程池详解 一.前言 nginx是采用多进程模型,master和worker之间主要通过pipe管道的方式进行通信,多进程的优势就在于各个进程互不影响.但是经常会有人问道,nginx为什么不采用多线程模型(这个除了之前一篇文章讲到的情况,别的只有去问作者了,HAHA).其实,nginx代码中提供了一个thread_pool(线程池)的核心模块来处理多任务的.下面就本人对该thread_pool这个模块的理解来跟大家做些分享(文中错误.不足还请大家指出,谢谢) 二.thread_