OpenCV之理解KNN邻近算法k-Nearest Neighbour
目录
- 目标
- 理论
- OpenCV中的kNN
目标
在本章中,将理解
- k最近邻(kNN)算法的概念
理论
kNN是可用于监督学习的最简单的分类算法之一。这个想法是在特征空间中搜索测试数据的最近邻。用下面的图片来研究它。
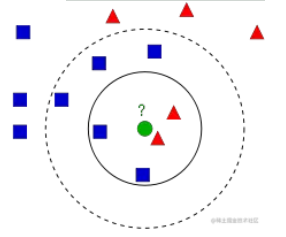
在图像中,有两个族类,蓝色正方形和红色三角形。称每一种为类(Class)。他们的房屋显示在他们的城镇地图中,我们称之为特征空间( Feature Space)。 (可以将特征空间视为投影所有数据的空间。例如,考虑一个2D坐标空间。每个数据都有两个特征,x和y坐标。可以在2D坐标空间中表示此数据;如果有三个特征,则需要3D空间;现在考虑N个特征,需要N维空间,这个N维空间就是其特征空间。在上图中,可以将其视为2D情况。有两个特征)。 现在有一个新成员进入城镇并创建了一个新房屋,显示为绿色圆圈。它应该被添加到这些蓝色/红色家族之一中。称该过程为分类(Classification)。这个新会员应该如何分类?本文使用kNN算法解决上述问题。
一种方法是检查谁是其最近邻。从图像中可以明显看出它是红色三角形家族。因此,它也被添加到了红色三角形中。此方法简称为最近邻(Nearest Neighbour )分类,因为分类仅取决于最近邻。 但这是有问题的。红三角可能是最近的。但是,如果附近有很多蓝色方块怎么办?然后,蓝色方块在该地区的权重比红色三角更大。因此,仅检查最接近的一个是不够的。相反,检查一些k个近邻的族。那么,看谁占多数,新样本就属于那个类。在上图中,假设设置k=3,即3个最近族。它有两个红色和一个蓝色(有两个等距的蓝色,但是由于k = 3,只取其中一个),所以它应该加入红色家族。但是,如果我们取k=7时,它有5个蓝色族和2个红色族,它应该加入蓝色族。因此,分类结果随着k的值而变化。更有趣的是,如果k=4时,它有2个红色邻居和2个蓝色邻居,这是一个平局!因此最好将k设置为奇数。由于分类取决 于k个最近的邻居,因此该方法称为k近邻。 同样,在kNN中,在考虑k个邻居时,对所有人都给予同等的重视,这公平吗?例如,以k=4的情况为例,按照数量来说这是平局。但是其中的两个红色族比其他两个蓝色族离它更近。因此,它更应该被添加到红色。那么如何用数学解释呢?根据每个家庭到新来者的距离来给他们一些权重。对于那些靠近它的人,权重增加,而那些远离它的人,权重减轻。 然后,分别添加每个族的总权重。谁得到的总权重最高,新样本归为那一族。这称为modified kNN或者** weighted kNN**。 因此,使用kNN算法时候,需要了解的重要信息如下:
- 需要了解镇上所有房屋的信息,因为必须检查新样本到所有现有房屋的距离,以找到最近的邻居。如果有许多房屋和家庭,则需要大量的内存,并且需要更多的时间进行计算
- 任何类型的“训练”或准备几乎是零时间。“学习”涉及在测试和分类之前记住(存储)数据
OpenCV中的kNN
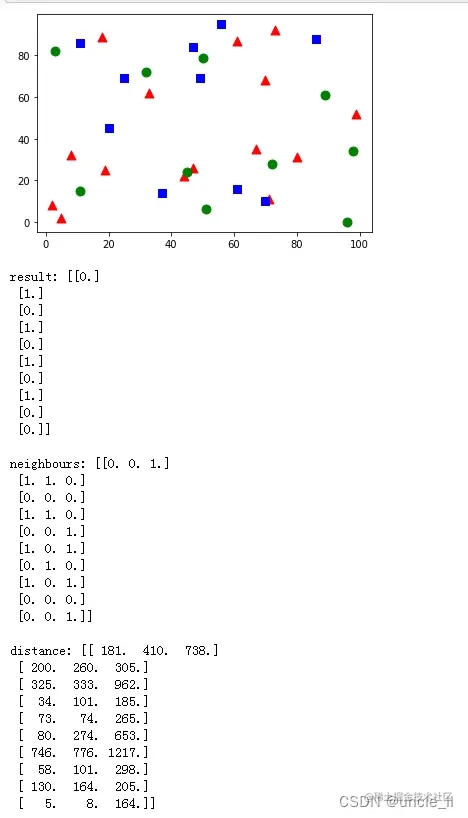
就像上面一样,将在这里做一个简单的例子,有两个族(类)。 因此,在这里,将红色系列标记为Class-0(用0表示),将蓝色系列标记为Class-1(用1表示)。创建25个族或25个训练数据,并将它们标记为0类或1类。借助Numpy中的Random Number Generator来完成所有这些工作。然后在Matplotlib的帮助下对其进行绘制。红色系列显示为红色三角形,蓝色系列显示为蓝色正方形。
import cv2 import numpy as np from matplotlib import pyplot as plt # Feature set containing (x,y) values of 25 known/training data trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32) # Label each one either Red or Blue with numbers 0 and 1 responses = np.random.randint(0, 2, (25, 1)).astype(np.float32) responses # Take Red neighbours and plot them red = trainData[responses.ravel()==0] plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^') # Take Blue neighbours and plot them blue = trainData[responses.ravel()==1] plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's') plt.show()
由于使用的是随机数生成器,因此每次运行代码都将获得不同的数据。 接下来启动kNN算法,并传递trainData和响应以训练kNN(它会构建搜索树)。 然后,将在OpenCV中的kNN的帮助下将一个新样本进行分类。在进入kNN之 前,需要了解测试数据(新样本数据)上的知识。数据应为浮点数组,其大小为number of testdata×number of features×number of features。然后找到新加入的最近邻。可以指定我们想要多少个邻居k(这里设置为3)。它返回:
- 给新样本的标签取决于kNN理论。如果要使用“最近邻居”算法,只需指定
k=1即可,其中k是邻居数 - k最近邻的标签
- 与新邻居的新距离相应的距离
下面看看它是如何工作的,新样本被标记为绿色。
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32)
# Label each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0, 2, (25, 1)).astype(np.float32)
# Take Red neighbours and plot them
red = trainData[responses.ravel()==0]
plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^')
# Take Blue neighbours and plot them
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's')
newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32)
plt.scatter(newcomer[:, 0], newcomer[:, 1], 80, 'g', 'o')
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomer, 3)
print("result: {}\n".format(results))
print("neighbours: {}\n".format(neighbours))
print("distance: {}\n".format(dist))
plt.show()
得到了如下的结果:

它说我们的新样本有3个近邻,一个来自Red家族,另外两个来自Blue家族。因此,他被标记为蓝色家庭。
如果有大量数据,则可以将其作为数组传递。获得的相应的结果是以数组的形式出现。
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32)
# Label each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0, 2, (25, 1)).astype(np.float32)
# Take Red neighbours and plot them
red = trainData[responses.ravel()==0]
plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^')
# Take Blue neighbours and plot them
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's')
# newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32)
newcomers = np.random.randint(0,100,(10,2)).astype(np.float32) # 10 new-comers
plt.scatter(newcomers[:, 0], newcomers[:, 1], 80, 'g', 'o')
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomers, 3) # The results also will contain 10 labels.
plt.show()
print("result: {}\n".format(results))
print("neighbours: {}\n".format(neighbours))
print("distance: {}\n".format(dist))
附加资源
- NPTEL notes on Pattern Recognition, Chapter 11
- Wikipedia article on Nearest neighbor search
- Wikipedia article on k-d tree
以上就是OpenCV之理解KNN k-Nearest Neighbour的详细内容,更多关于OpenCV理解KNN的资料请关注我们其它相关文章!
相关推荐
-
OpenCV 光流Optical Flow示例
目录 目标 光流 OpenCV 中的 Lucas-Kanade 光流 OpenCV 中的密集光流 目标 在本章中,将学习: 使用 Lucas-Kanade 方法理解光流的概念及其估计 使用cv2.calcOpticalFlowPyrLK()等函数来跟踪视频中的特征点 使用cv2.calcOpticalFlowFarneback()方法创建一个密集的光流场 光流 光流是由物体或相机的运动引起的图像物体在两个连续帧之间的明显运动的模式.它是二维向量场,其中每个向量都是一个位移向量,显示点从第一帧到第
-
OpenCV使用KNN完成OCR手写体识别
目录 目标 手写数字的OCR 也可以用来预测单个数字 英文字母的OCR 目标 在本章中,将学习 使用kNN来构建基本的OCR应用程 使用OpenCV自带的数字和字母数据集 手写数字的OCR 目标是构建一个可以读取手写数字的应用程序.为此,需要一些 train_data 和test_data .OpenCV git项目中有一个图片 digits.png (opencv/samples/data/ 中),其中包含 5000 个手写数字(每个数字500个),每个数字都是尺寸大小为 20x20 的图像.
-
OpenCV立体图像深度图Depth Map基础
目录 目标 基础 代码 目标 在本节中,将学习 根据立体图像创建深度图 基础 在上一节中,看到了对极约束和其他相关术语等基本概念.如果有两个场景相同的图像,则可以通过直观的方式从中获取深度信息.下面是一张图片和一些简单的数学公式证明了这种想法. 上图包含等效三角形.编写它们的等式将产生以下结果: xxx和x′x'x′是图像平面中与场景点3D相对应的点与其相机中心之间的距离.BBB是两个摄像机之间的距离(已知),fff是摄像机的焦距(已知).简而言之,上述方程式表示场景中某个点的深度与相应图像点及
-

基于Opencv图像识别实现答题卡识别示例详解
目录 1. 项目分析 2.项目实验 3.项目结果 总结 在观看唐宇迪老师图像处理的课程中,其中有一个答题卡识别的小项目,在此结合自己理解做一个简单的总结. 1. 项目分析 首先在拿到项目时候,分析项目目的是什么,要达到什么样的目标,有哪些需要注意的事项,同时构思实验的大体流程. 图1. 答题卡测试图像 比如在答题卡识别的项目中,针对测试图片如图1 ,首先应当实现的功能是: 能够捕获答题卡中的每个填涂选项. 将获取的填涂选项与正确选项做对比计算其答题正确率. 2.项目实验 在对测试图像进行形态学操
-
OpenCV特征匹配和单应性矩阵查找对象详解
目录 目标 基础 实现 附加资源 目标 在本章中,将学习 将从Calib3D模块中混淆特征匹配和找到(单应性矩阵)homography,以查找复杂图像中的已知对象. 基础 在之前的内容中,使用了一个query image,在其中找到了一些特征点,拍摄了另一张train image,也在该图像中找到了特征,找到了其中最好的匹配.简而言之,在另一张杂乱的图像中找到了物体某些部分的位置.该信息足以准确地在train image上找到对象. 为此,可以使用calib3d模块的函数,即cv2.findHo
-
OpenCV目标检测Meanshif和Camshift算法解析
目录 学习目标 Meanshift OpenCV中的Meanshift Camshift OpenCV中的Camshift 附加资源 学习目标 在本章中,将学习用于跟踪视频中对象的Meanshift和Camshift算法 Meanshift Meanshift背后的原理很简单,假设有点的集合(它可以是像素分布,例如直方图反投影). 给定一个小窗口(可能是一个圆形),必须将该窗口移动到最大像素密度(或最大点数)的区域.如下图所示: 初始窗口以蓝色圆圈显示,名称为“C1”.其原始中心以蓝色矩形标记,
-
python OpenCV实现图像特征匹配示例详解
目录 目标 Brute-Force匹配器的基础 使用ORB描述符进行Brute-Force匹配 什么是Matcher对象? 带有SIFT描述符和比例测试的Brute-Force匹配 基于匹配器的FLANN 目标 在本章中,将学习: 如何将一个图像中的特征与其他图像进行匹配 在OpenCV中使用Brute-Force匹配器和FLANN匹配器 Brute-Force匹配器的基础 暴力匹配器很简单.它使用第一组中一个特征的描述符,并使用一些距离计算将其与第二组中的所有其他特征匹配.并返回最接近的一个.
-
Python实现KNN邻近算法
简介 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有关.由于kNN
-
Python机器学习k-近邻算法(K Nearest Neighbor)实例详解
本文实例讲述了Python机器学习k-近邻算法.分享给大家供大家参考,具体如下: 工作原理 存在一份训练样本集,并且每个样本都有属于自己的标签,即我们知道每个样本集中所属于的类别.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后提取样本集中与之最相近的k个样本.观察并统计这k个样本的标签,选择数量最大的标签作为这个新数据的标签. 用以下这幅图可以很好的解释kNN算法: 不同形状的点,为不同标签的点.其中绿色点为未知标签的数据点.现在要对绿色点进行预测.由图不难得出
-
用Python实现KNN分类算法
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 KNN分类算法应该算得上是机器学习中最简单的分类算法了,所谓KNN即为K-NearestNeighbor(K个最邻近样本节点).在进行分类之前KNN分类器会读取较多数量带有分类标签的样本数据作为分类的参照数据,当它对类别未知的样本进行分类时,会计算当前样本与所有参照样本的差异大小:该差异大小是通过数据点在样本特征的多维度空间中的距离来进行衡量的,也就是说,如果两个样本点在在其特征数据多维度空间中的距离越近,则这
-
python实现KNN分类算法
一.KNN算法简介 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有
-
原生python实现knn分类算法
一.题目要求 用原生Python实现knn分类算法. 二.题目分析 数据来源:鸢尾花数据集(见附录Iris.txt) 数据集包含150个数据集,分为3类,分别是:Iris Setosa(山鸢尾).Iris Versicolour(杂色鸢尾)和Iris Virginica(维吉尼亚鸢尾).每类有50个数据,每个数据包含四个属性,分别是:Sepal.Length(花萼长度).Sepal.Width(花萼宽度).Petal.Length(花瓣长度)和Petal.Width(花瓣宽度). 将得到的数据集
-
C++基于特征向量的KNN分类算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.KNN算法中,所选择的邻居都是已经正确分类的对象.该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关.由于KNN方法主要靠周围有限的邻
-
使用python实现kNN分类算法
k-近邻算法是基本的机器学习算法,算法的原理非常简单: 输入样本数据后,计算输入样本和参考样本之间的距离,找出离输入样本距离最近的k个样本,找出这k个样本中出现频率最高的类标签作为输入样本的类标签,很直观也很简单,就是和参考样本集中的样本做对比.下面讲一讲用python实现kNN算法的方法,这里主要用了python中常用的numpy模块,采用的数据集是来自UCI的一个数据集,总共包含1055个样本,每个样本有41个real的属性和一个类标签,包含两类(RB和NRB).我选取800条样本作为参考样
-
Python KNN分类算法学习
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本"距离"最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类.简单的说就是让最相似的K个样本来投票决定. 这里所说的距
-
opencv python 基于KNN的手写体识别的实例
OCR of Hand-written Data using kNN OCR of Hand-written Digits 我们的目标是构建一个可以读取手写数字的应用程序, 为此,我们需要一些train_data和test_data. OpenCV附带一个images digits.png(在文件夹opencv\sources\samples\data\中),它有5000个手写数字(每个数字500个,每个数字是20x20图像).所以首先要将图片切割成5000个不同图片,每个数字变成一个单行400
-
python机器学习之KNN分类算法
本文为大家分享了python机器学习之KNN分类算法,供大家参考,具体内容如下 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本"距离"最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类.简单的说就是让最相似的K个样本来投票决定. 这里所说的距离,一