关于Pandas count()与values_count()的用法及区别
目录
- Pandas count()与values_count()用法
- count()
- values_count()在指定的统计的列名上
- Pandas:count()与value_counts()对比
Pandas count()与values_count()用法
count()

values_count()在指定的统计的列名上
结果多了该列:
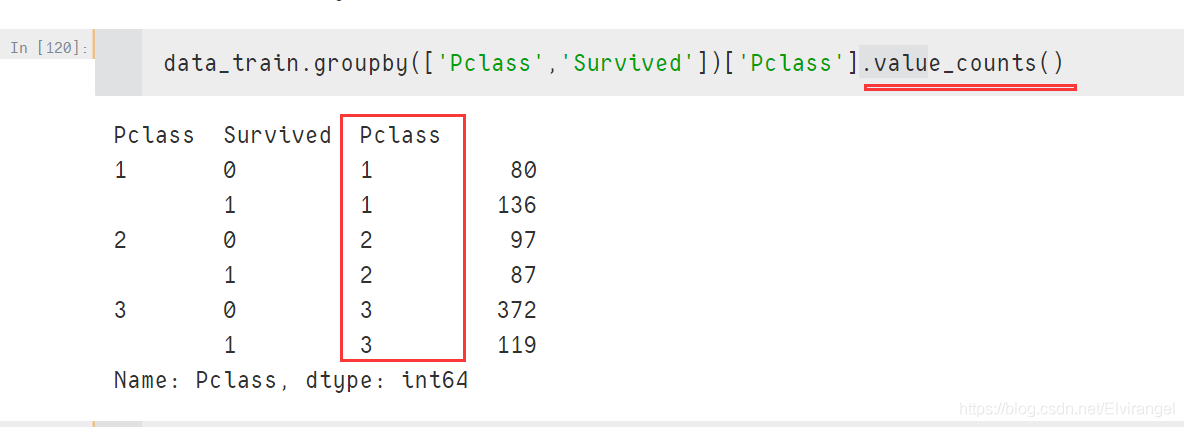
对比:
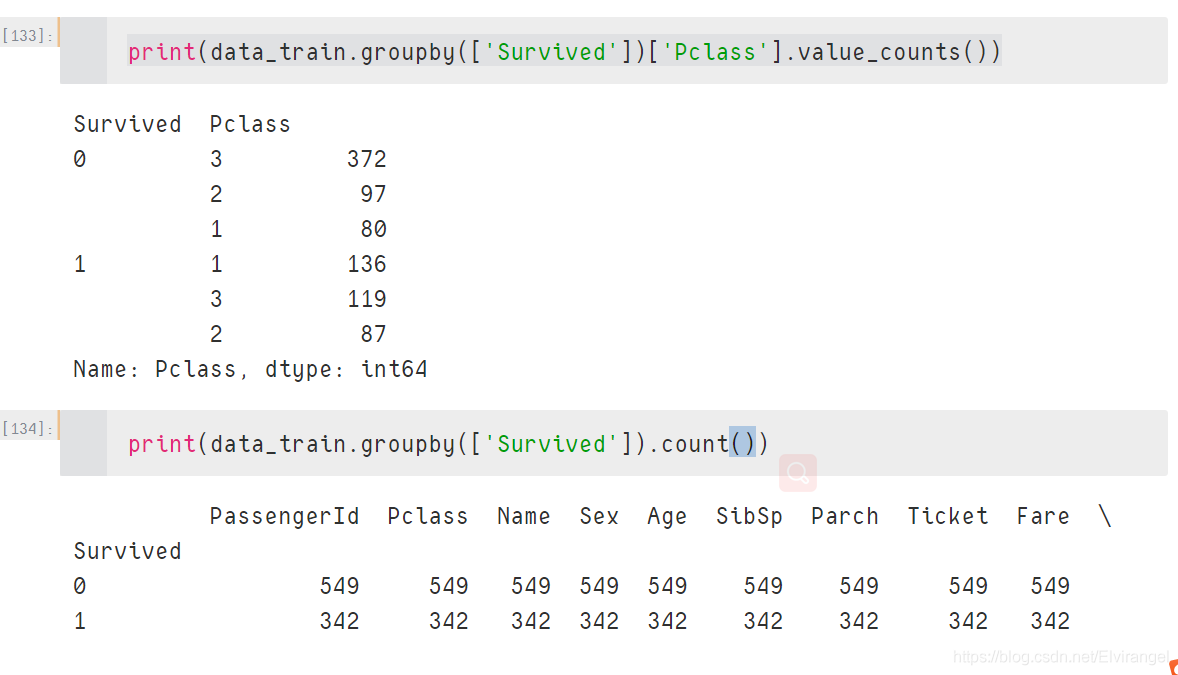
对比:
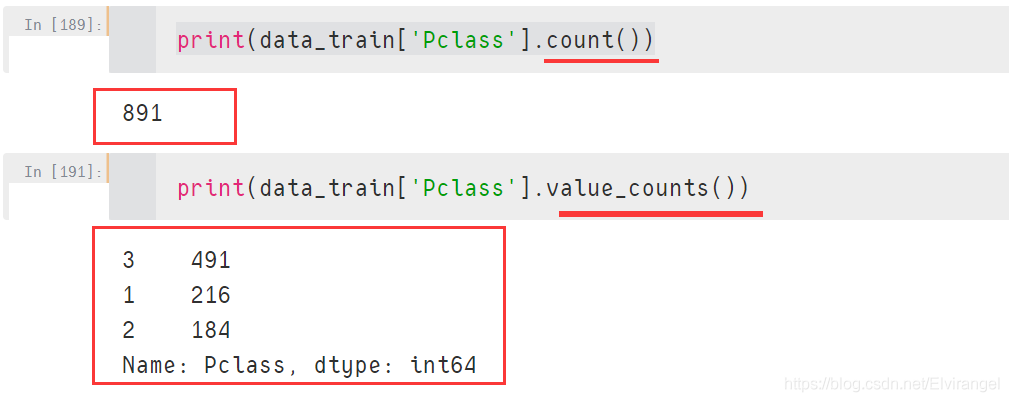
Pandas:count()与value_counts()对比
1. Series.value_counts(self, normalize=False, sort=True, ascending=False, bins=None, dropna=True)
返回一个包含所有值及其数量的 Series。 且为降序输出,即数量最多的第一行输出。
参数含义如下:
| Parameters: |
normalize : boolean, default False If True then the object returned will contain the relative frequencies of the unique values. sort : boolean, default True Sort by frequencies. ascending : boolean, default False Sort in ascending order. bins : integer, optional Rather than count values, group them into half-open bins, a convenience for pd.cut, only works with numeric data. dropna : boolean, default True Don’t include counts of NaN. |
|---|---|
| Returns: |
Series |
举例如下:
import pandas as pd index = pd.Index([3, 1, 2, 3, 4, np.nan]) index.value_counts() """ 输出为: 3.0 2 4.0 1 2.0 1 1.0 1 dtype: int64 """
如果 normalize 为 True的话,统计的结果会相加 = 1:
import pandas as pd s = pd.Series([3, 1, 2, 3, 4, np.nan]) s.value_counts(normalize=True) """ 输出为: 3.0 0.4 4.0 0.2 2.0 0.2 1.0 0.2 dtype: float64 """
2. Series.count(self, level=None)
返回非空值的数量。若是在 CSV 文件中可用来统计行数,如:
import pandas as pd
file = pd.read_csv('test.csv')
print(file['A'].count())
# 此时输出的即是 A 列的行数
参数含义如下:
| Parameters: |
level : int or level name, default None If the axis is a MultiIndex (hierarchical), count along a particular level, collapsing into a smaller Series. |
|---|---|
| Returns: |
int or Series (if level specified) Number of non-null values in the Series. |
举例如下:
import pands as pd s = pd.Series([0.0, 1.0, np.nan]) s.count() # 此时输出为 2
这就是两者的区别和各自的用途。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas计数 value_counts()的使用
在pandas里面常用value_counts确认数据出现的频率. 1. Series 情况下: pandas 的 value_counts() 函数可以对Series里面的每个值进行计数并且排序. import pandas as pd df = pd.DataFrame({'区域' : ['西安', '太原', '西安', '太原', '郑州', '太原'], '10月份销售' : ['0.477468', '0.195046', '0.015964', '0.259654', '0.856
-

python中pandas对多列进行分组统计的实现
使用groupby([ ]).size()统计的结果,值相同的字段值会不显示 如上图所示,第一个空着的行是982499 7 3388 1,因为此行与前面一行的这两个字段值是一样的,所以不显示.第二个空着的行是390192 22 4278 1,因为此行与前面一行的第一个字段值是一样的,所以不显示.这样的展示方式更直观,但对于刚用的人,可能会让其以为是缺失值. 如果还不明白可以看下面的全部数据及操作. import pandas as pd res6 = pd.read_csv('test.csv'
-
Python pandas之求和运算和非空值个数统计
目录 准备工作 1.非空值计数 1.1对全表进行操作 1.1.1求取每列的非空值个数 1.1.2 求取每行的非空值个数 1.2 对单独的一行或者一列进行操作 1.2.1 求取单独某一列的非空值个数 1.2.2 求取单独某一行的非空值个数 1.3 对多行或者多列进行操作 1.3.1 求取多列的非空值个数 1.3.2 求取多行的非空值个数 2 sum求和 2.1对全表进行操作 2.1.1对每一列进行求和 2.1.2 对每一行进行求和 2.2 对单独的一行或者一列进行操作 2.2.1 对某一列进行求和
-
关于Pandas count()与values_count()的用法及区别
目录 Pandas count()与values_count()用法 count() values_count()在指定的统计的列名上 Pandas:count()与value_counts()对比 Pandas count()与values_count()用法 count() values_count()在指定的统计的列名上 结果多了该列: 对比: 对比: Pandas:count()与value_counts()对比 1. Series.value_counts(self, normaliz
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
python pandas移动窗口函数rolling的用法
超级好用的移动窗口函数 最近经常使用移动窗口函数,觉得很方便,功能强大,代码简单,故将pandas中的移动窗口函数都做介绍.它都是以rolling打头的函数,后接具体的函数,来显示该移动窗口函数的功能. rolling_count 计算各个窗口中非NA观测值的数量 函数 pandas.rolling_count(arg, window, freq=None, center=False, how=None) arg : DataFrame 或 numpy的ndarray 数组格式 window :
-
Pandas数据类型之category的用法
创建category 使用Series创建 在创建Series的同时添加dtype="category"就可以创建好category了.category分为两部分,一部分是order,一部分是字面量: In [1]: s = pd.Series(["a", "b", "c", "a"], dtype="category") In [2]: s Out[2]: 0 a 1 b 2 c 3
-
pandas中pd.groupby()的用法详解
在pandas中的groupby和在sql语句中的groupby有异曲同工之妙,不过也难怪,毕竟关系数据库中的存放数据的结构也是一张大表罢了,与dataframe的形式相似. import numpy as np import pandas as pd from pandas import Series, DataFrame df = pd.read_csv('./city_weather.csv') print(df) ''' date city temperature
-
详解pandas df.iloc[]的典型用法
与df.loc[] 根据行标或者列标获取数据不同的是df.iloc[]则根据数据的坐标(position)获取,如下图红色数字所标识: iloc[] 同样接受两个参数,分别代表行坐标,列坐标.可以接受的参数 类型为数字,数字类型的列表以及切片 下面举例说明: name score grade id a bog 45 A c jiken 67 B d bob 23 A b j
-
Python Pandas数据合并pd.merge用法详解
目录 前言 语法 参数 1.连接键 2.索引连接 3.多连接键 4.连接方法 5.连接指示 总结 前言 实现类似SQL的join操作,通过pd.merge()方法可以自由灵活地操作各种逻辑的数据连接.合并等操作 可以将两个DataFrame或Series合并,最终返回一个合并后的DataFrame 语法 pd.merge(left, right, how = 'inner', on = None, left_on = None, right_on = None, left_index = Fal
-
Pandas数据分析之groupby函数用法实例详解
目录 正文 一.了解groupby 二.数据文件简介 三.求各个商品购买量 四.求各个商品转化率 五.转化率最高的30个商品及其转化率 小小の总结 正文 今天本人在赶学校课程作业的时候突然发现groupby这个分组函数还是蛮有用的,有了这个分组之后你可以实现很多统计目标. 当然,最主要的是,他的使用非常简单 本期我们以上期作业为例,单走一篇文章来看看这个函数可以实现哪些功能: (本期需要准备的行囊): jupyter notebook环境(anaconda自带) pandas第三方库 numpy
-
php中静态类与静态变量用法的区别分析
本文实例分析了php中静态类与静态变量用法的区别.分享给大家供大家参考.具体分析如下: static是定义一个静态对象或静态变量,关于static 定义的变量或类方法有什么特性我们看完本文章的相关实例后就见分晓了. 1. 创建对象$object = new Class(),然后使用"->"调用:$object->attribute/function,前提是该变量/方法可访问. 2. 直接调用类方法/变量:class::attribute/function,无论是静态/非静态
-
浅谈Pandas中map, applymap and apply的区别
1.apply() 当想让方程作用在一维的向量上时,可以使用apply来完成,如下所示 In [116]: frame = DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon']) In [117]: frame Out[117]: b d e Utah -0.029638 1.081563 1.280300 Ohio 0.647747 0.831136 -1.