数据库性能优化二:数据库表优化提升性能
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分
优化①:设计规范化表,消除数据冗余
数据库范式是确保数据库结构合理,满足各种查询需要、避免数据库操作异常的数据库设计方式。满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以,在这里简单介绍一下前三范式
先给大家看一下百度百科给出的定义:
第一范式(1NF)无重复的列
所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
第二范式(2NF)属性
在1NF的基础上,非码属性必须完全依赖于码[在1NF基础上消除非主属性对主码的部分函数依赖]
第三范式(3NF)属性
在1NF基础上,任何非主属性不依赖于其它非主属性[在2NF基础上消除传递依赖]
通俗的给大家解释一下(可能不是最科学、最准确的理解)
第一范式:属性(字段)的原子性约束,要求属性具有原子性,不可再分割;
第二范式:记录的惟一性约束,要求记录有惟一标识,每条记录需要有一个属性来做为实体的唯一标识。
第三范式:属性(字段)冗余性的约束,即任何字段不能由其他字段派生出来,在通俗点就是:主键没有直接关系的数据列必须消除(消除的办法就是再创建一个表来存放他们,当然外键除外)
如果数据库设计达到了完全的标准化,则把所有的表通过关键字连接在一起时,不会出现任何数据的复本(repetition)。标准化的优点是明显的,它避免了数据冗余,自然就节省了空间,也对数据的一致性(consistency)提供了根本的保障,杜绝了数据不一致的现象,同时也提高了效率。
优化②:适当的冗余,增加计算列
数据库设计的实用原则是:在数据冗余和处理速度之间找到合适的平衡点
满足范式的表一定是规范化的表,但不一定是最佳的设计。很多情况下会为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。比如我们有一个表,产品名称,单价,库存量,总价值。这个表是不满足第三范式的,因为“总价值”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“总价值”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。合理的冗余可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
其中"总价值"就是一个计算列,在数据库中有两种类型:数据列和计算列,数据列就是需要我们手动或者程序给予赋值的列,计算列是源于表中其他的数据计算得来,比如这里的"总价值"
在SQL中创建计算列:
代码如下:
create table table1
(
number decimal(18,4),
price money,
Amount as number*price --这里就是计算列
)
也可以再表设计中,直接手动添加或修改列属性即可:如下图 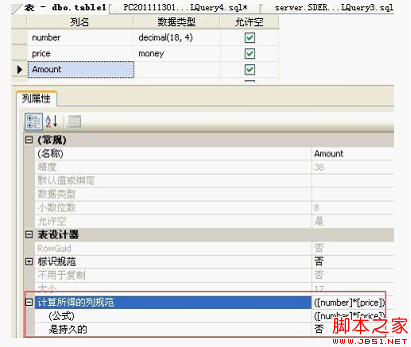
是否持久性,我们也需要注意:
如果是'否',说明这列是虚拟列,每次查询的时候计算一次,而且那么它是不可以用来做check,foreign key或not null约束。
如果是'是',就是真实的列,不需要每次都计算,可以再此列上创建索引等等。
优化③:索引
索引是一个表优化的重要指标,在表优化中占有极其重要的成分,所以将单独写一章”SQL索引一步到位“去告诉大家如何建立和优化索引
优化④:主键和外键的必要性
主键与外键的设计,在全局数据库的设计中,占有重要地位。 因为:主键是实体的抽象,主键与外键的配对,表示实体之间的连接。
主键:根据第二范式,需要有一个字段去标识这条记录,主键无疑是最好的标识,但是很多表也不一定需要主键,但是对于数据量大,查询频繁的数据库表,一定要有主键,主键可以增加效率、防止重复等优点。
主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。
主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前面。
外键:外键作为数据库对象,很多人认为麻烦而不用,实际上,外键在大部分情况下是很有用的,理由是:外键是最高效的一致性维护方法
数据库的一致性要求,依次可以用外键、CHECK约束、规则约束、触发器、客户端程序,一般认为,离数据越近的方法效率越高。
谨慎使用级联删除和级联更新,级联删除和级联更新作为SQL SERVER 2000当年的新功能,在2005作了保留,应该有其可用之处。我这里说的谨慎,是因为级联删除和级联更新有些突破了传统的关于外键的定义,功能有点太过强大,使用前必须确定自己已经把握好其功能范围,否则,级联删除和级联更新可能让你的数据莫名其妙的被修改或者丢失。从性能看级联删除和级联更新是比其他方法更高效的方法。
优化⑤:存储过程、视图、函数的适当使用
很多人习惯将复杂操作都放在应用程序层,但如果你要优化数据访问性能,将SQL代码移植到数据库上(使用存储过程,视图,函数和触发器)也是一个很大的改进原因如下:
1. 存储过程减少了网络传输、处理及存储的工作量,且经过编译和优化,执行速度快,易于维护,且表的结构改变时,不影响客户端的应用程序
2、使用存储过程,视图,函数有助于减少应用程序中SQL复制的弊端,因为现在只在一个地方集中处理SQL
3、使用数据库对象实现所有的TSQL有助于分析TSQL的性能问题,同时有助于你集中管理TSQL代码,更好的重构TSQL代码
优化⑥:传说中的‘三少原则'
①:数据库的表越少越好
②:表的字段越少越好
③:字段中的组合主键、组合索引越少越好
当然这里的少是相对的,是减少数据冗余的重要设计理念。
优化⑦:分割你的表,减小表尺寸
如果你发现某个表的记录太多,例如超过一千万条,则要对该表进行水平分割。水平分割的做法是,以该表主键的某个值为界线,将该表的记录水平分割为两个表。
如果你若发现某个表的字段太多,例如超过八十个,则垂直分割该表,将原来的一个表分解为两个表
优化⑧:字段设计原则
字段是数据库最基本的单位,其设计对性能的影响是很大的。需要注意如下:
A、数据类型尽量用数字型,数字型的比较比字符型的快很多。
B、 数据类型尽量小,这里的尽量小是指在满足可以预见的未来需求的前提下的。
C、 尽量不要允许NULL,除非必要,可以用NOT NULL+DEFAULT代替。
D、少用TEXT和IMAGE,二进制字段的读写是比较慢的,而且,读取的方法也不多,大部分情况下最好不用。
E、 自增字段要慎用,不利于数据迁移
相关推荐
-
优化Mysql数据库的8个方法
1.创建索引对于查询占主要的应用来说,索引显得尤为重要.很多时候性能问题很简单的就是因为我们忘了添加索引而造成的,或者说没有添加更为有效的索引导致.如果不加索引的话,那么查找任何哪怕只是一条特定的数据都会进行一次全表扫描,如果一张表的数据量很大而符合条件的结果又很少,那么不加索引会引起致命的性能下降.但是也不是什么情况都非得建索引不可,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引.2.复合索引比如有一条语句是这样的:select * from users
-

用实例详解Python中的Django框架中prefetch_related()函数对数据库查询的优化
实例的背景说明 假定一个个人信息系统,需要记录系统中各个人的故乡.居住地.以及到过的城市.数据库设计如下: Models.py 内容如下: from django.db import models class Province(models.Model): name = models.CharField(max_length=10) def __unicode__(self): return self.name class City(models.Model): name = models.Ch
-
海量数据库的查询优化及分页算法方案
海量数据库的查询优化及分页算法方案 原出处不详 摘自:www.21php.com 随着"金盾工程"建设的逐步深入和公安信息化的高速发展,公安计算机应用系统被广泛应用在各警种.各部门.与此同时,应用系统体系的核心.系统数据的存放地――数据库也随着实际应用而急剧膨胀,一些大规模的系统,如人口系统的数据甚至超过了1000万条,可谓海量.那么,如何实现快速地从这些超大容量的数据库中提取数据(查询).分析.统计以及提取数据后进行数据分页已成为各地系统管理员和数据库管理员亟待解决的难题. 在以下
-
MySQL 联合索引与Where子句的优化 提高数据库运行效率
网站系统上线至今,数据量已经不知不觉上到500M,近8W记录了.涉及数据库操作的基本都是变得很慢了,用的人都会觉得躁火~~然后把这个情况在群里一贴,包括机器配置什么的一说,马上就有群友发话了,而且帮我确定了不是机器配置的问题,"深圳-枪手"热心人他的机器512内存过百W的数据里也跑得飞快,甚至跟那些几W块的机器一样牛(吹过头了),呵呵~~~ 在群友的分析指点下,尝试把排序.条件等一个一个去除来做测试,结果发现问题就出在排序部分,去除排序的时候,执行时间由原来的48秒变成0.3x秒,这是
-
mysql中优化和修复数据库工具mysqlcheck详细介绍
一.mysqlcheck简介 mysqlcheck客户端可以检查和修复MyISAM表.它还可以优化和分析表. mysqlcheck的功能类似myisamchk,但其工作不同.主要差别是当mysqld服务器在运行时必须使用mysqlcheck,而myisamchk应用于服务器没有运行时.使用mysqlcheck的好处是不需要停止服务器来检查或修复表.使用myisamchk修复失败是不可逆的. Mysqlcheck为用户提供了一种方便的使用SQL语句CHECK TABLE.REPAIR TABLE.
-
MySQL数据库优化详解
mysql表复制 复制表结构+复制表数据 mysql> create table t3 like t1; mysql> insert into t3 select * from t1; mysql索引 ALTER TABLE用来创建普通索引.UNIQUE索引或PRIMARY KEY索引 ALTER TABLE table_name ADD INDEX index_name (column_list) ALTER TABLE table_name ADD UNIQUE (column_list)
-
服务器维护小常识(硬盘内容增加、数据库优化等)
为了方便大家在维护中了解一些维护内容的同时又能避免出现错误.下面就收集了一些服务器日常维护的常识供大家参考. 服务器日常维护常识之硬件维护 服务器日常维护常识硬件维护1.储存设备的扩充 当资源不断扩展的时候,服务器就需要更多的内存和硬盘容量来储存这些资源.所以,内存和硬盘的扩充是很常见的.增加内存前需要认定与服务器原有的内存的兼容性,最好是同一品牌的规格的内存.如果是服务器专用的ECC内存,则必须选用相同的内存,普通的SDRAM内存与ECC内存在同一台服务器上使用很可能会引起统严重出错.在增加硬
-
数据库性能优化一:数据库自身优化提升性能
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第一部分 优化①:增加次数据文件,设置文件自动增长(粗略数据分区) 1.1:增加次数据文件 从SQLSERVER2005开始,数据库不默认生成NDF数据文件,一般情况下有一个主数据文件(MDF)就够了,但是有些大型的数据库,由于信息很多,而且查询频繁,所以为了提高查询速度,可以把一些表或者一些表中的部分记录分开存储在不同的数据文件里 由于CPU和内存的速度远大于硬盘的读写速度,所以可以把不同的数据文件放在不同的物理硬盘
-
数据库学习建议之提高数据库速度的十条建议
很多网站的重要信息都是保存在数据库中的,用户通过提交访问数据库来获取用户信息.如果数据库速度非常的快,有助于节省服务器的资源,在这篇文章中,我收集了十个优化数据库速度的技巧. 0. 小心设计数据库 第一个技巧也许看来理所当然,但事实上大部分数据库的问题都来自于设计不好的数据库结构. 譬如我曾经遇见过将客户端信息和支付信息储存在同一个数据库列中的例子.对于系统和用数据库的开发者来说,这很糟糕. 新建数据库时,应当将信息储存在不同的表里,采用标准的命名方式,并采用主键. 来源: http://www
-
SQL Server 数据库优化
在开发工具.数据库设计.应用程序的结构.查询设计.接口选择等方面有多种选择,这取决于特定的应用需求以及开发队伍的技能.本文以SQL Server为例,从后台数据库的角度讨论应用程序性能优化技巧,并且给出了一些有益的建议.1 数据库设计 要在良好的SQL Server方案中实现最优的性能,最关键的是要有1个很好的数据库设计方案.在实际工作中,许多SQL Server方案往往是由于数据库设计得不好导致性能很差.所以,要实现良好的数据库设计就必须考虑这些问题. 1.1 逻辑库规范化问题 一般来说,逻辑
-
Codeigniter操作数据库表的优化写法总结
用codeigniter也有一段时间了,一直没有做什么总结.现在总结一些Codeigniter操作数据库表的优化写法,虽说不全,但是也确实可以帮助那些刚刚上手CI的同学. 链接数据库 复制代码 代码如下: $this->load->database();//手动连接数据库//连接多数据库$DB1 = $this->load->database('group_one', TRUE);$DB2 = $this->load->database('group_two', TRU
-
oracle数据库sql的优化总结
一:使用where少使用having; 二:查两张以上表时,把记录少的放在右边: 三:减少对表的访问次数: 四:有where子查询时,子查询放在最前: 五:select语句中尽量避免使用*(执行时会把*依次转换为列名): 六:尽量多的使用commit: 七:Decode可以避免重复扫描相同的记录或重复连接相同的表: 八:通过内部函数也可提高sql效率: 九:连接多个表时,使用别名并把别名前缀于每个字段上: 十:用exists代替in 十一:not exists代替 not in(not in 字
-
Postgre数据库Insert 、Query性能优化详解
一.前言以前的系统由于表设计比较复杂(多张表,表与表直接有主从关系),这个是业务逻辑决定的. 插入效率简直实在无法忍受,必须优化.在了解了Postgre的Copy,unlogged table 特性 之后,决定一探究竟. 二.测试用例 1.数据表结构:表示一个员工工作绩效的表(work_test):共15个字段id,no,name,sex,tel,address,provice,city,post,mobile,department,work,start_time,end_time,score索
-
mysql 数据库中my.ini的优化 2G内存针对站多 抗压型的设置
物理内存越大,设置就越大.默认为2402,调到512-1024最佳 innodb_additional_mem_pool_size=4M 默认为2M innodb_flush_log_at_trx_commit=1 (设置为0就是等到innodb_log_buffer_size列队满后再统一储存,默认为1) innodb_log_buffer_size=2M 默认为1M innodb_thread_concurrency=8 你的服务器CPU有几个就设置为几,建议用默认一般为8 key_buff
-
Oracle SQL tuning 数据库优化步骤分享(图文教程)
SQL Turning 是Quest公司出品的Quest Central软件中的一个工具.Quest Central是一款集成化.图形化.跨平台的数据库管理解决方案,可以同时管理 Oracle.DB2 和 SQL server 数据库. 一.SQL Tuning for SQL Server简介 SQL语句的优化对发挥数据库的最佳性能非常关键.然而不幸的是,应用优化通常由于时间和资源的因素而被忽略.SQL Tuning (SQL优化)模块可以对比和评测特定应用中SQL语句的运行性能,提出智能化的
-
asp.net程序优化 尽量减少数据库连接操作
项目以我自己的设计编码完成,并整合测试.初始化数据时,问题出现了.刚开始体现在客户端接受数据很慢.测试环境环境下,数据库服务器部署在国外,网站部署在公司内部,而且我一直认为我的程序在数据库数据处理这里已经做了足够的优化,包括索引和主键已经做到了合理使用.综上所述,起初的速度问题一直没有引起我的关注. 然而最后问题的关键恰恰出在数据库连接查询方面,频繁查询导致数据初始化速度很慢.刚开始我采取的方法是即用即查:需要数据的时候就从数据库查,有比较多的单表查询返回单个字段的情况.假如我有大概3000条左
-
开启SQLSERVER数据库缓存依赖优化网站性能
很多时候,我们服务器的性能瓶颈会是在查询数据库的时候,所以对数据库的缓存非常重要,那么有没有一种方法,可以实现SQL SERVER数据库的缓存,当数据表没有更新时,就从缓存中读取,当有更新的时候,才从数据表中读取呢,答案是肯定的,这样的话我们对一些常用的基础数据表就可以缓存起来,比如做新闻系统的新闻类别等,每次就不需要从数据库中读取了,加快网站的访问速度. 那么如何开启SQLSERVER数据库缓存依赖,方法如下: 第一步:修改Web.Config的<system.web>节的配置,代码如下,让