C++使用opencv调用级联分类器来识别目标物体的详细流程
目录
- 前言:
- 流程讲解:
- 1.创建一个级联分类器对象
- 2.创建一个视频流
- 3.将传入的视频帧转换为灰度图
- 4.将多余的空通道进行压缩
- 5.直方图均衡化
- 6.调用级联分类器,并将内容框出,然后将此帧显示出来
- 总结
使用编译器:Qt Creator 4.2.1
前言:
相较于帧差法捕捉目标物体识别,级联分类器识别目标物体更加具有针对性,使用前者只要是动的物体都会被捕捉识别到,画面里有一点风吹草动,都会被捕捉识别下来,如果我想识别具体的人或者物,都无法做到精准的目标识别,所以有了级联分类器识别(即模型识别),会按照训练好的级联分类器(模型)来进行目标识别
流程讲解:
1.创建一个级联分类器对象
创建一个级联分类器对象,并读取已经已经训练好的模型
CascadeClassifier cascade;//级联分类器(模型)
cascade.load("D:/Qt_Opencv_Project/cars.xml");//读取级联分类器
2.创建一个视频流
读取一个要识别的视频路径
Mat frame;
VideoCapture cap("D:/VideoTraining/carMove.mp4");
while (cap.read(frame))
{
imshow("video",frame);//将读到的帧显示出来
datectCarDaw(frame,cascade,2);//将读到的帧传入函数用作识别
waitKey(25);//延时25ms,避免播放过快
}
3.将传入的视频帧转换为灰度图
转换为灰度图,色彩通道缩小一半,减少图片数据计算量,提升计算速度
Mat gray;
//转换为灰度图,色彩通道缩小一半
cvtColor(frame,gray,CV_RGB2GRAY);
效果如下:

4.将多余的空通道进行压缩
原通道为RGB三通道图片数据,转换为灰度图后,变为单通道数据,多余的通道可以压缩掉,可以看到图片减小三分之二
//再将灰度图缩小一半
Mat smalling(cvRound(frame.rows/scale),cvRound(frame.cols/scale),CV_8UC1);
resize(gray,smalling,smalling.size(),0,0,INTER_LINEAR);
效果如下:

可以发现,图一下子小了很多,大大降低了计算量
5.直方图均衡化
将缩小一半的灰度图进行均衡化,使其更加黑白分明,增强局部的对比度,便于计算机识别
//直方图均衡化:将缩小一半的灰度图进行均值化 使其更加黑白分明
equalizeHist(smalling,smalling);
效果如下:
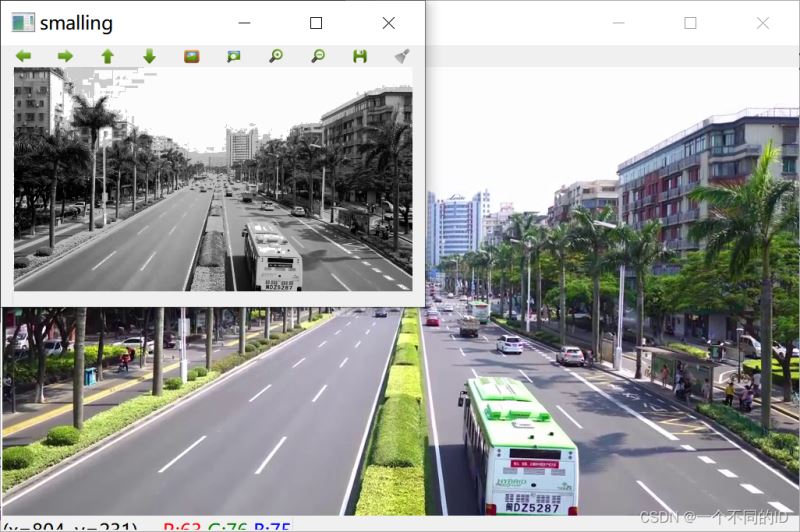
降低了渐进效果的像素数目,更加的黑白分明
6.调用级联分类器,并将内容框出,然后将此帧显示出来
调用读取已经训练好的模型,调用detectMultiScale函数器参数含义为:
待检测的图片帧(此处为均衡化后的图片帧)
被检测物体的矩形向量容器(调用前声明了一个向量容器cars)
每次搜索减小的图像比例(每次缩小1.05倍,扫描的细致一点)
检测目标周围相邻矩形的最小个数(此处设为5个,此处视道路情况可以适当增加个数)
类型(扫描类型)
目标区域可能的最小尺寸(此处为25*25,太小了会识别不到,太大了可能几辆车贴的很近可能只能识别出一辆)
//调用级联分类器进行模型匹配并框出内容
vector<Rect>cars;
//此函数参数说明: 待检测的图片帧 被检测物体的矩形向量容器 每次搜索减小的图像比例
//检测目标周围相邻矩形的最小个数(此处设为2个) 类型 目标区域的大小尺寸
cascade.detectMultiScale(smalling,cars,1.05,5,0|CV_HAAR_SCALE_IMAGE,Size(25,25));
vector<Rect>::const_iterator iter;
//绘制方块,标记目标,注意,标记要画在原帧上,要讲方框的大小和帧坐标扩大,因为是根据灰度图识别的,灰度图被缩小了
for(iter=cars.begin();iter!=cars.end();iter++)
{
rectangle(frame,
cvPoint(cvRound(iter->x*scale),cvRound(iter->y*scale)),
cvPoint(cvRound((iter->x+iter->width)*scale),cvRound((iter->y+iter->height)*scale)),
Scalar(0,255,0),2,8
);
}
imshow("frame",frame);
效果如下:

循环显示每一帧,最终成果展示:
博主所使用的这个模型训练的样本较为有限,主要训练的是普通轿车的车头,车尾训练较少,货车等其他车型没有做特别的训练,所以只能保证识别轿车的车头

可以根据实际车流量和车辆距离摄像头的距离来调整最小目标大小和最大矩形框个数
代码:
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
void datectCarDaw(Mat &frame,CascadeClassifier cascade,double scale)
{
Mat gray;
//转换为灰度图,色彩通道缩小一半
cvtColor(frame,gray,CV_RGB2GRAY);
//imshow("huidu",gray);
//再将灰度图缩小一半
Mat smalling(cvRound(frame.rows/scale),cvRound(frame.cols/scale),CV_8UC1);
resize(gray,smalling,smalling.size(),0,0,INTER_LINEAR);
//直方图均衡化:将缩小一半的灰度图进行均值化 使其更加黑白分明
equalizeHist(smalling,smalling);
//imshow("smalling",smalling);
//调用级联分类器进行模型匹配并框出内容
vector<Rect>cars;
//此函数参数说明: 待检测的图片帧 被检测物体的矩形向量容器 每次搜索减小的图像比例 检测目标周围相邻矩形的最小个数(此处设为2个) 类型 目标区域的大小尺寸
cascade.detectMultiScale(smalling,cars,1.05,5,0|CV_HAAR_SCALE_IMAGE,Size(25,25));
vector<Rect>::const_iterator iter;
//绘制方块,标记目标,注意,标记要画在原帧上,要讲方框的大小和帧坐标扩大,因为是根据灰度图识别的,灰度图被缩小了
for(iter=cars.begin();iter!=cars.end();iter++)
{
rectangle(frame,
cvPoint(cvRound(iter->x*scale),cvRound(iter->y*scale)),
cvPoint(cvRound((iter->x+iter->width)*scale),cvRound((iter->y+iter->height)*scale)),
Scalar(0,255,0),2,8
);
}
imshow("frame",frame);
}
int main(int argc, char *argv[])
{
CascadeClassifier cascade;//级联分类器(模型)
cascade.load("D:/Qt_Opencv_Project/cars.xml");//读取级联分类器
//cascade.load("D:/Qt_Opencv_Project/face.xml");
Mat frame;
VideoCapture cap("D:/VideoTraining/carMove.mp4");
//VideoCapture cap(0);
while (cap.read(frame))
{
imshow("video",frame);//将读到的帧显示出来
datectCarDaw(frame,cascade,2);//将读到的帧传入函数用作识别
waitKey(25);//延时25ms,避免播放过快
}
return 0;
}
有兴趣也可以看看无需使用模型但是只能捕捉动态目标的帧差法识别:
C++调用opencv完成运动目标捕捉
Qt Creator配置使用opencv:
Qt Creator下配置opencv环境
总结
到此这篇关于C++使用opencv调用级联分类器来识别目标物体的文章就介绍到这了,更多相关C++ opencv识别目标物体内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python3+opencv3识别图片中的物体并截取的方法
如下所示: 运行环境:python3.6.4 opencv3.4.0 # -*- coding:utf-8 -*- """ Note: 使用Python和OpenCV检测图像中的物体并将物体裁剪下来 """ import cv2 import numpy as np # step1:加载图片,转成灰度图 image = cv2.imread("353.jpg") gray = cv2.cvtColor(image, cv2.C
-

python+opencv实现动态物体识别
注意:这种方法十分受光线变化影响 自己在家拿着手机瞎晃的成果图: 源代码: # -*- coding: utf-8 -*- """ Created on Wed Sep 27 15:47:54 2017 @author: tina """ import cv2 import numpy as np camera = cv2.VideoCapture(0) # 参数0表示第一个摄像头 # 判断视频是否打开 if (camera.isOpened()
-
C++使用opencv调用级联分类器来识别目标物体的详细流程
目录 前言: 流程讲解: 1.创建一个级联分类器对象 2.创建一个视频流 3.将传入的视频帧转换为灰度图 4.将多余的空通道进行压缩 5.直方图均衡化 6.调用级联分类器,并将内容框出,然后将此帧显示出来 总结 使用编译器:Qt Creator 4.2.1 前言: 相较于帧差法捕捉目标物体识别,级联分类器识别目标物体更加具有针对性,使用前者只要是动的物体都会被捕捉识别到,画面里有一点风吹草动,都会被捕捉识别下来,如果我想识别具体的人或者物,都无法做到精准的目标识别,所以有了级联分类器识别(即模型
-
Python OpenCV调用摄像头检测人脸并截图
本文实例为大家分享了Python OpenCV调用摄像头检测人脸并截图的具体代码,供大家参考,具体内容如下 注意:需要在python中安装OpenCV库,同时需要下载OpenCV人脸识别模型haarcascade_frontalface_alt.xml,模型可在OpenCV-PCA-KNN-SVM_face_recognition中下载. 使用OpenCV调用摄像头检测人脸并连续截图100张 #-*- coding: utf-8 -*- # import 进openCV的库 import cv2
-
python通过opencv调用摄像头操作实例分析
实例源码: #pip3 install opencv-python import cv2 from datetime import datetime FILENAME = 'myvideo.avi' WIDTH = 1280 HEIGHT = 720 FPS = 24.0 # 必须指定CAP_DSHOW(Direct Show)参数初始化摄像头,否则无法使用更高分辨率 cap = cv2.VideoCapture(0, cv2.CAP_DSHOW) # 设置摄像头设备分辨率 cap.set(cv
-
基于python+opencv调用电脑摄像头实现实时人脸眼睛以及微笑识别
本文教大家调用电脑摄像头进行实时人脸+眼睛识别+微笑识别,供大家参考,具体内容如下 一.调用电脑摄像头进行实时人脸+眼睛识别 # 调用电脑摄像头进行实时人脸+眼睛识别,可直接复制粘贴运行 import cv2 face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_frontalface_default.xml') eye_cascade = cv2.CascadeClassifier(cv2.data.ha
-
超详细注释之OpenCV Haar级联检测器进行面部检测
目录 1. 效果图 2. 原理 2.1 Haar级联是什么? 2.2 Haar级联的问题与局限性 2.3 Haar级联预训练的模型 3. 源码 3.1 图像检测 3.2 实时视频流检测 参考 这篇博客将介绍如何使用预训练好的OpenCV Haar级联人脸.眼睛.嘴部检测器,并将它们应用于图片及实时视频流的检测. 人脸检测结果是最稳定和准确的.不幸的是,在许多情况下,眼睛检测和嘴巴检测结果是不可用的--对于面部特征/部分提取,强烈建议使用python,dlib,OpenCV提取眼睛,鼻子,嘴唇及下
-
opencv调用yolov3模型深度学习目标检测实例详解
目录 引言 建立相关目录 代码详解 附源代码 引言 opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解 对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn. 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码 建立相关目录 在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下
-
Python OpenCV 调用摄像头并截图保存功能的实现代码
0x01 OpenCV安装 通过命令pip install opencv-python 安装 pip install opencv-python 0x02 示例 import cv2 cap = cv2.VideoCapture(0) #打开摄像头 while(1): # get a frame ret, frame = cap.read() # show a frame cv2.imshow("capture", frame) #生成摄像头窗口 if cv2.waitKey(1)
-
python+openCV调用摄像头拍摄和处理图片的实现
在深度学习过程中想做手势识别相关应用,需要大量采集手势图片进行训练,作为一个懒人当然希望飞快的连续采集图片并且采集到的图片就已经被处理成统一格式的啦..于是使用python+openCV调用摄像头,在采集图片的同时顺便处理成想要的格式. 详细代码如下: import cv2 import os print("=============================================") print("= 热键(请在摄像头的窗口使用): =") pri
-
python 用opencv调用训练好的模型进行识别的方法
此程序为先调用opencv自带的人脸检测模型,检测到人脸后,再调用我自己训练好的模型去识别人脸,使用时更改模型地址即可 #!usr/bin/env python import cv2 font=cv2.FONT_HERSHEY_SIMPLEX cascade1 = cv2.CascadeClassifier("D:\\opencv249\\opencv\\sources\\data\\haarcascades\\haarcascade_frontalface_alt_tree.xml"
-
Python基于opencv调用摄像头获取个人图片的实现方法
接触图像领域的应该对于opencv都不会感到陌生,这个应该算是功能十分强劲的一个算法库了,当然了,使用起来也是很方便的,之前使用Windows7的时候出现多该库难以安装成功的情况,现在这个问题就不存在了,需要安装包的话可以去我的资源中下载使用,使用pip安装方式十分地便捷. 今天主要是基于opencv模块来调用笔记本的内置摄像头,然后从视频流中获取到人脸的图像数据用于之后的人脸识别项目,也就是为了构建可用的数据集.整个实现过程并不复杂,具体如下: #!usr/bin/env python #en