Pandas常用累计、同比、环比等统计方法实践过程
目录
- 1.(本年)累计
- 2.(上年)同期累计
- 3. 上月(完成)
- 4. 同比(增长率)
- 5. 环比(增长率)
- 6. 总结
统计表中常常以本年累计、上年同期(累计)、当期(例如当月)完成、上月完成为统计数据,并进行同比、环比分析。
如下月报统计表所示样例,本文将使用Python Pandas工具进行统计。
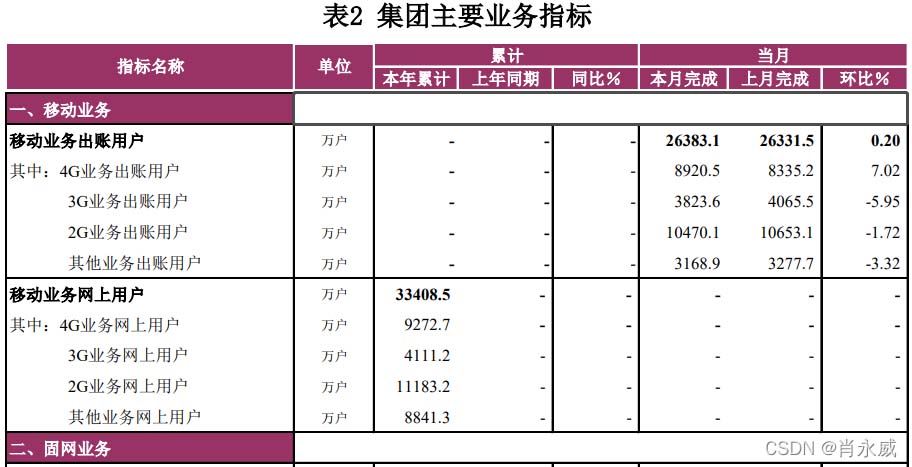
其中:
- (本年)累计:是指本年1月到截止月份的合计数
- (上年)同期(累计):是指去年1月到与本年累计所对应截止月份的合计数
- 同比(增长率)=(本期数-同期数)/同期数*100%
- 环比(增长率)=(本期数-上期数)/上期数*100%
注:这里的本期是指本月完成或当月完成,上期数是指上月完成。
示例数据:
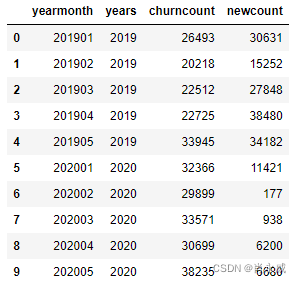
注:为了演示方便,本案例数据源仅使用2年,且每年5个月的数据。
1.(本年)累计
在做统计分析开发中,按年度、按月累计某些统计数据,是比较常见的需求。对于数据来说,就是按规则逐行累加数据。
Pandas中的cumsum()函数可以实现按某时间维度累计需求。
# 取本年累计值
import pandas as pd
df = pd.read_csv('data2021.csv')
cum_columns_name = ['cum_churncount','cum_newcount']
df[cum_columns_name] = df[['years','churncount','newcount']].groupby(['years']).cumsum()
注:其中分组‘years’是指年度时间维度累计。
计算结果如下:
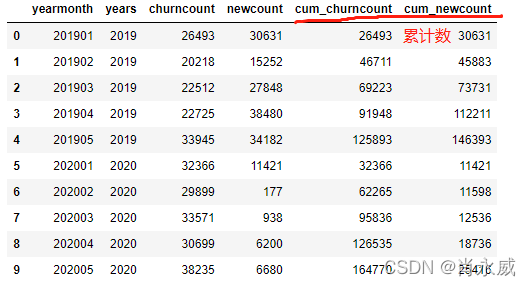
2.(上年)同期累计
对于(上年)同期累计,将直接取上一年度累计值的同月份数据。pandas DataFrame.shift()函数可以把数据移动指定的行数。
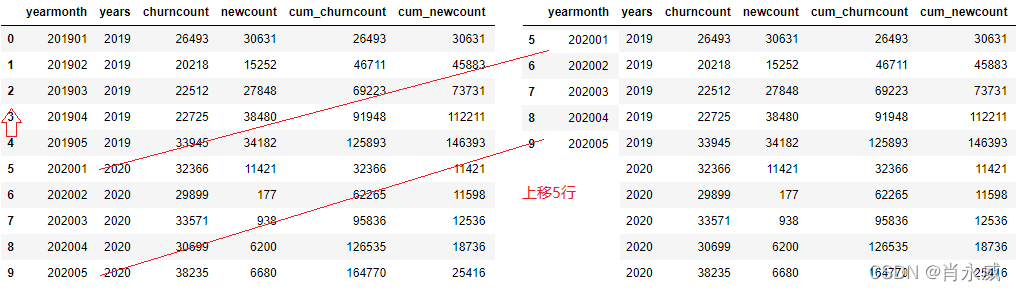
接续上列,读取同期数据。首先是把‘yearmonth’上移五行,如上图所示得到新的DataFrame,通过‘yearmonth’进行两表数据关联(左关联:左侧为原表,右侧为移动后的新表),实现去同期数据效果。
cum_columns_dict = {'cum_churncount':'cum_same_period_churncount',
'cum_newcount':'cum_same_period_newcount'}
df_cum_same_period = df[['cum_churncount','cum_newcount','yearmonth']].copy()
df_cum_same_period = df_cum_same_period.rename(columns=cum_columns_dict)
#df_cum_same_period.loc[:,'yearmonth'] = df_cum_same_period['yearmonth'].shift(-12) # 一年12个月
df_cum_same_period.loc[:,'yearmonth'] = df_cum_same_period['yearmonth'].shift(-5) # 由于只取5个月数据的原因
df = pd.merge(left=df,right=df_cum_same_period,on='yearmonth',how='left')
3. 上月(完成)
取上月的数据,使用pandas DataFrame.shift()函数把数据移动指定的行数。
接续上列,读取上期数据。(与取同期原理一样,略)
last_mnoth_columns_dict = {'churncount':'last_month_churncount',
'newcount':'last_month_newcount'}
df_last_month = df[['churncount','newcount','yearmonth']].copy()
df_last_month = df_last_month.rename(columns=last_mnoth_columns_dict)
df_last_month.loc[:,'yearmonth'] = df_last_month['yearmonth'].shift(-1) # 移动一行
df = pd.merge(left=df,right=df_last_month,on='yearmonth',how='left')
4. 同比(增长率)
计算同比涉及到除法,需要剔除除数为零的数据。
df.fillna(0,inplace=True) # 空值填充为0 # 计算同比 df.loc[df['cum_same_period_churncount']!=0,'cum_churncount_rat'] = (df['cum_churncount']-df['cum_same_period_churncount'])/df['cum_same_period_churncount'] # 除数不能为零 df.loc[df['cum_same_period_newcount']!=0,'cum_newcount_rat'] = (df['cum_newcount']-df['cum_same_period_newcount'])/df['cum_same_period_newcount'] # 除数不能为零 df[['yearmonth','cum_churncount','cum_newcount','cum_same_period_churncount','cum_same_period_newcount','cum_churncount_rat','cum_newcount_rat']]
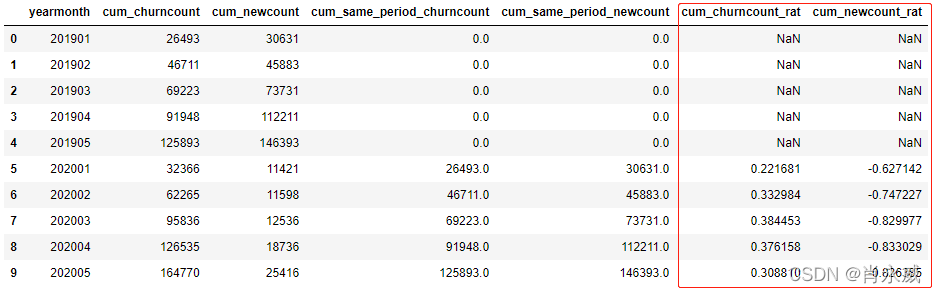
5. 环比(增长率)
# 计算环比 df.loc[df['last_month_churncount']!=0,'churncount_rat'] = (df['churncount']-df['last_month_churncount'])/df['last_month_churncount'] # 除数不能为零 df.loc[df['last_month_newcount']!=0,'newcount_rat'] = (df['newcount']-df['last_month_newcount'])/df['last_month_newcount'] # 除数不能为零 df[['yearmonth','churncount','newcount','last_month_churncount','last_month_newcount','churncount_rat','newcount_rat']]
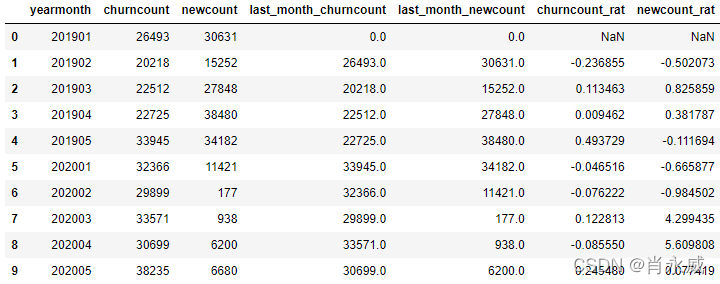
6. 总结
pandas做统计计算功能方法比较多,这里总结用到的技术有累计cumsum()函数、移动数据shift()函数、表合并关联merge()函数,以及通过loc条件修改数据。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas如何计算同比环比增长
目录 计算同比环比增长 问题描述 数据准备 计算环比增长 计算同比增长 同比和环比计算公式 计算同比环比增长 问题描述 我有2017.1-2018.12的销售数据,计算每一个月的 同比和环比增长,没有的话 用null代替 注释: 同比 和 环比 都是为了显示数据的变化速度,但是基数不同,同比侧重长期数据趋势变化,环比侧重于短期内数据趋势变化 同比是指在同一时期内的数据趋势变化,用于本期与同期的对比,例如本期2018-02月销售额与同期2017-02月销售额做对比.[(本期 - 同期)/ 同期]
-

使用pandas计算环比和同比的方法实例
目录 前言 1.数据准备 2.环比计算 3.同比计算 4.关于pct_change()函数 5.后记 前言 在进行业务数据分析时,往往需要使用pandas计算环比.同比及增长率等指标,为了能够更加方便的进行的统计数据,整理方法如下. 1.数据准备 为方便进行演示,此处提前生成需要进行统计的数据,数据已经是按照时间维度进行排序. months = pd.date_range(start='2010-01-01', end='2020-12-31', freq='M') test_df = pd.D
-
python学习教程之Numpy和Pandas的使用
前言 本文主要给大家介绍了关于python中Numpy和Pandas使用的相关资料,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 它们是什么? NumPy是Python语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库. Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas提供了大量能使我们快速便捷地处理数据
-
Pandas常用累计、同比、环比等统计方法实践过程
目录 1.(本年)累计 2.(上年)同期累计 3. 上月(完成) 4. 同比(增长率) 5. 环比(增长率) 6. 总结 统计表中常常以本年累计.上年同期(累计).当期(例如当月)完成.上月完成为统计数据,并进行同比.环比分析. 如下月报统计表所示样例,本文将使用Python Pandas工具进行统计. 其中: (本年)累计:是指本年1月到截止月份的合计数 (上年)同期(累计):是指去年1月到与本年累计所对应截止月份的合计数 同比(增长率)=(本期数-同期数)/同期数*100% 环比(增长率)=
-
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下. 1 import语句 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re 2 文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列名 index_col='
-
Python Pandas常用函数方法总结
初衷 NumPy.Pandas.Matplotlib.SciPy 等可以说是最最最常用的 Python 库了.我们在使用 Python 库的时候,通常会遇到两种情况.以 Pandas 举例. 我想对 Pandas 数据结构的数据实现某种操作,但是我不知道或者说在我的印象里似乎已经不记得是否有这样的函数方法,如果有,又该用哪个方法呢? 我想实现某种数据操作,我记得我用过或者见过某个函数可以实现这个功能,但是我死活想不起来那个函数叫啥了.或者,我想起来了哪个函数可以实现这个功能,但是我想知道是否有更
-
Pandas实现DataFrame的简单运算、统计与排序
目录 一.运算 二.统计 三.排序 在前面的章节中,我们讨论了Series的计算方法与Pandas的自动对齐功能.不光是Series,DataFrame也是支持运算的,而且还是经常被使用的功能之一. 由于DataFrame的数据结构中包含了多行.多列,所以DataFrame的计算与统计可以是用行数据或者用列数据.为了更方便我们的使用,Pandas为我们提供了常用的计算与统计方法: 操作 方法 操作 方法 求和 sum 最大值 max 求均值 mean 最小值 min 求方差 var 标准差 st
-
Pandas实现groupby分组统计的实践
目录 1.创建数据和导入包 2.分组使用聚合函数做数据统计 3.遍历groupby的结果理解执行流程 4.实例分组探索天气数据 类似SQL:select city,max(temperature) from city_weather group by city; groupby:先对数据分组,然后在每个分组上应用聚合函数.转换函数 本次演示:一.分组使用聚合函数做数据统计二.遍历groupby的结果理解执行流程三.实例分组探索天气数据 1.创建数据和导入包 import pandas as pd
-
Pandas常用的读取和保存数据的函数使用(csv,mysql,json,excel)
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis).pandas提供了大量能使我们快速便捷地处理数据的函数和方法.它是使Python成为强大而高效的数据分析环境的重要因素之一.pandas的IO工具支持非常多的数据输入输出方式.包括csv.json.Excel.数据库等. 本
-
python基础篇之pandas常用基本函数汇总
目录 前言 1.汇总函数 2.特征统计函数 3.唯一值函数 4.替换函数 总结 前言 这篇主要整理pandas常用的基本函数,主要分为五部分: 汇总函数 特征统计函数 唯一值函数 替换函数 排序函数 1.汇总函数 常用的主要是4个: tail(): 返回表或序列的后n行 head(): 返回表或序列的前n行 info(): 返回表的信息概况 describe(): 返回表中数值列对应的主要统计量 n默认为5 df.describe() #运行截图 Height Weight count 183.
-
python中pandas常用命令详解
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一. 1.pandas pandas 是一个多功能且功能强大的数据科学库. 2.读取数据 pd.read_csv("data.csv") 3.读取指定列 pd.read_csv(&quo
-
Pandas如何对Categorical类型字段数据统计实战案例
目录 一.Pandas如何对Categorical类型字段数据统计 1.1主要知识点 1.2创建 python 文件 1.3运行结果 二.Pandas如何从股票数据找出收盘价最低行 2.1主要知识点 2.2创建 python 文件 2.3运行结果 三.Pandas如何给股票数据新增年份和月份 3.1主要知识点 3.2创建 python 文件 3.3运行结果 四.Pandas如何获取表格的信息和基本数据统计 4.1主要知识点 4.2创建 python 文件 4.3运行结果 五.Pandas如何使用
-
对pandas的dataframe绘图并保存的实现方法
对dataframe绘图并保存: ax = df.plot() fig = ax.get_figure() fig.savefig('fig.png') 可以制定列,对该列各取值作统计: label_dis = df.label.value_counts() ax = label_dis.plot(title='label distribution', kind='bar', figsize=(18, 12)) fig = ax.get_figure() fig.savefig('label_d