pytorch collate_fn的基础与应用教程
目录
- 作用
- 原则
- 基础
- dataset
- dataloader
- 应用情形
- 总结
作用
collate_fn:即用于collate的function,用于整理数据的函数。
说到整理数据,你当然要会用数据,即会用数据制作工具torch.utils.data.Dataset,虽然我们今天谈的是torch.utils.data.DataLoader,但是,其实:
- 这两个你如何定义;
- 从装载器dataloader中取数据后做什么处理;
- 模型的forward()中如何处理。
这三部分都是有机统一而不可分割的,一个地方改了,其他地方就要改。
emmm…,小小总结,collate_fn笼统的说就是用于整理数据,通常我们不需要使用,其应用的情形是:各个数据长度不一样的情况,比如第一张图片大小是28*28,第二张是50*50,这样的话就如果不自己写collate_fn,而使用默认的,就会报错。
原则
其实说起来,我们也没有什么原则,但是如今大多数做深度学习都是使用GPU,所以这个时候我们需要记住一个总则:只有tensor数据类型才能运行在GPU上,list和numpy都不可以。
从而,我们什么时候将我们的数据转化为tensor是一个问题,我的答案是前一节中的三个部分都可以来转化,只是我们大多数的人都习惯在部分一转化。
基础
dataset
我们必须先看看torch.utils.data.Dataset如何使用,以一个例子为例:
import torch.utils.data as Data
class mydataset(Data.Dataset):
def __init__(self,train_inputs,train_targets):#必须有
super(mydataset,self).__init__()
self.inputs=train_inputs
self.targets=train_targets
def __getitem__(self, index):#必须重写
return self.inputs[index],self.targets[index]
def __len__(self):#必须重写
return len(self.targets)
#构造训练数据 datax=torch.randn(4,3)#构造4个输入 datay=torch.empty(4).random_(2)#构造4个标签
#制作dataset dataset=mydataset(datax,datay)
下面,可以对dataset进行一系列操作,这些操作返回的结果和你之前那个class的三个函数定义都息息相关。我想说,那三个函数非常自由,你想怎么定义就怎么定义,上述只是一种常见的而已,你可以定制一个特色的。
len(dataset)#调用了你上面定义的def __len__()那个函数 #4
dataset[0]#调用了你上面定义的def __getitem__()那个函数 #(tensor([-1.1426, -1.3239, 1.8372]), tensor(0.))
所以我再三强调的是上面的输出结果和你的定义有关,比如你完全可以把def __getitem__()改成:
def __getitem__(self, index):
return self.inputs[index]#不输出标签
那么,
dataset[0]#此时当然变化。 #tensor([-1.1426, -1.3239, 1.8372])
可以看到,是非常随便的,你随便定制就好。
dataloader
torch.utils.data.DataLoader
dataloader=Data.DataLoader(dataset,batch_size=2)
4个数据,batch_size=2,所以一共有2个batch。
collate_fn如果你不指定,会调用pytorch内部的,也就是说这个函数是一定会调用的,而且调用这个函数时pytorch会往这个函数里面传入一个参数batch。
def my_collate(batch): return xxx
这个batch是什么?这个东西和你定义的dataset, batch_size息息相关。batch是一个列表[x,...,xx],长度就是batch_size,里面每一个元素是dataset的某一个元素,即dataset[i](我在上一节展示过dataset[0])。
在我们的例子中,由于我们没有对dataloader设置需要打乱数据,即shuffle=True,那么第1个batch就是前两个数据,如下:
print(datax) print(datay) batch=[dataset[0],dataset[1]]#所以才说和你dataset中get_item的定义有关。 print(batch)

对,你没有看错,上述代码展示的batch就会传入到pytorch默认的collate_fn中,然后经过默认的处理,输出如下:
it=iter(dataloader) nex=next(it)#我们展示第一个batch经过collate_fn之后的输出结果 print(nex)
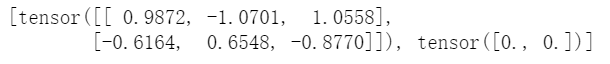
其实,上面就是我们常用的,经典的输出结果,即输入和标签是分开的,第一项是输入tensor,第二项是标签tensor,输入的维度变成了(batch_size,input_size)。
但是我们乍一看,将第一个batch变成上述输出结果很容易呀,我们也会!我们下面就来自己写一个collate_fn实现这个功能。
# a simple custom collate function, just to show the idea
# `batch` is a list of tuple where first element is input tensor and the second element is corresponding label
def my_collate(batch):
inputs=[data[0].tolist() for data in batch]
target = torch.tensor([data[1] for data in batch])
return [data, target]
dataloader=Data.DataLoader(dataset,batch_size=2,collate_fn=my_collate)
print(datax) print(datay)

it=iter(dataloader) nex=next(it) print(nex)
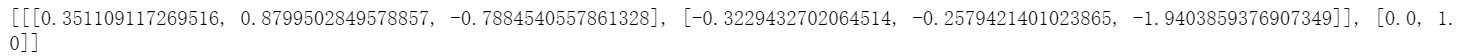
这不就和默认的collate_fn的输出结果一样了嘛!无非就是默认的还把输入变成了tensor,标签变成了tensor,我上面是列表,我改就是了嘛!如下:
def my_collate(batch):
inputs=[data[0].tolist() for data in batch]
inputs=torch.tensor(inputs)
target =[data[1].tolist() for data in batch]
target=torch.tensor(target)
return [inputs, target]
dataloader=Data.DataLoader(dataset,batch_size=2,collate_fn=my_collate)
it=iter(dataloader) nex=next(it) print(nex)
这下好了吧!
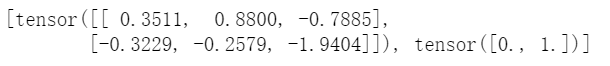
对了,作为彩蛋,告诉大家一个秘密:默认的collate_fn函数中有一些语句是转tensor以及tensor合并的操作,所以你的dataset如果没有设计成经典模式的话,使用默认的就容易报错,而我们自己会写collate_fn,当然就不存在这个问题啦。同时,给大家的一个经验就是,一般dataset是不会报错的,而是根据dataset制作dataloader的时候容易报错,因为默认collate_fn把dataset的类型限制得比较死。
应用情形
假设我们还是4个输入,但是维度不固定的。
a=[[1,2],[3,4,5],[1],[3,4,9]] b=[1,0,0,1] dataset=mydataset(a,b) dataloader=Data.DataLoader(dataset,batch_size=2) it=iter(dataloader) nex=next(it) nex
使用默认的collate_fn,直接报错,要求相同维度。

这个时候,我们可以使用自己的collate_fn,避免报错。
不过话说回来,我个人感受是:
在这里避免报错好像也没有什么用,因为大多数的神经网络都是定长输入的,而且很多的操作也要求相同维度才能相加或相乘,所以:这里不报错,后面还是报错。如果后面解决这个问题的方法是:在不足维度上进行补0操作,那么我们为什么不在建立dataset之前先补好呢?所以,collate_fn这个东西的应用场景还是有限的。
总结
到此这篇关于pytorch collate_fn的基础与应用的文章就介绍到这了,更多相关pytorch collate_fn应用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch技巧:DataLoader的collate_fn参数使用详解
DataLoader完整的参数表如下: class torch.utils.data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None) D
-

pytorch collate_fn的基础与应用教程
目录 作用 原则 基础 dataset dataloader 应用情形 总结 作用 collate_fn:即用于collate的function,用于整理数据的函数. 说到整理数据,你当然要会用数据,即会用数据制作工具torch.utils.data.Dataset,虽然我们今天谈的是torch.utils.data.DataLoader,但是,其实: 这两个你如何定义; 从装载器dataloader中取数据后做什么处理; 模型的forward()中如何处理. 这三部分都是有机统一而不可分割的,
-
Ajax基础详解教程(一)
什么是Ajax? 在研究ajax之前首先让我们先来讨论一个问题 --什么是Web 2.0 .听到 Web 2.0 这个词的时候,应该首先问一问 "Web 1.0 是什么?" 虽然很少听人提到 Web 1.0,实际上它指的就是具有完全不同的请求和响应模型的传统 Web.比如,到 hdu.edu.cn 网站上点击一个按钮.就会对服务器发送一个请求,然后响应再返回到浏览器.该请求不仅仅是新内容和项目列表,而是另一个完整的 HTML 页面.因此当 Web 浏览器用新的 HTML 页面重绘时,可
-
Ajax基础详解教程(二)
在上篇文章给大家介绍了Ajax基础详解教程(一),讲到Ajax中open方法的第三个参数异步和同步的问题,今天呢,就来继续往下唠,先接着上回的代码 var oBtn = document.getElementById('btn'); oBtn.onclick = function(){ var xhr = null; if(window.XMLHttpRequest){ xhr = new XMLHttpRequest(); }else{ xhr = new ActiveXObject('Mic
-
windows版本下mysql的安装启动和基础配置图文教程详解
下载: 第一步 : 打开网址(进入官网下载) :https://www.mysql.com ,点击downloads之后跳转到https://www.mysql.com/downloads 第二步 :跳转至网址https://dev.mysql.com/downloads/,选择Community选项 第三步 :点击MySQL Community Server进入https://dev.mysql.com/downloads/mysql/页面,再点击5.6版本的数据库 第四步:windows操作
-
Pytorch 神经网络—自定义数据集上实现教程
第一步.导入需要的包 import os import scipy.io as sio import numpy as np import torch import torch.nn as nn import torch.backends.cudnn as cudnn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms, ut
-
springboot整合websocket最基础入门使用教程详解
项目最终的文件结构 1 添加maven依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <
-
汇编基础程序编写教程示例
目录 源程序 1.1 构成 寄存器与段的关联假设 标号 定义一个段 程序结束标记 程序返回 程序运行 1.2 源程序中的"程序" 1.3 段结束.程序结束.程序返回 1.4 语法错误和逻辑错误 2 程序执行的过程 2.1 一个汇编语言程序从写出到最终执行的简要过程: 2.2 连接 2.3 可执行文件 2.4 程序执行过程的跟踪 总结 3 程序编写 3.1 两个基本的问题 3.2 数据在哪里 立即数(idata) 寄存器 段地址(SA)和偏移地址(EA) 3.3 指令处理的数据有多长 3
-
TypeScript基础class类教程示例
目录 class类 示例 构造函数 继承 class 类 类是面向对象语言的程序设计中的概念,是面向对象编程的基础. 类是创建对象的模板,是对现实生活中一类具有共同特征的事物的抽象 类的内部封装了属性和方法,用于操作自身的成员 示例 将每条狗看做一个对象,那他的属性就有 品种.颜色,方法(行为)舔.叫.吃. class Dog { breed: string; color: string; lick(): void { console.log(` 我仍认为我们作为一个舔狗的真正目的是为了拥有一份
-
javascript基础数据类型转换教程示例
目录 数值型转换为字符串类型 字符串类型转换为数值型 转换为布尔型 结语 数值型转换为字符串类型 方式 说明 案例 toString() 转成字符串 var num =1; alert ( num.toString()); String() 强制转换 转成字符串 var num =1; alert ( String ( num )); 加号拼接字符串 和字符串拼接的结果都是字符串 var num =1; alert ( num +"我是字符串"); // 1.将数字型转换为字符串类型 var n
-
spring security需求分析与基础环境准备教程
目录 前言 一.需求分析 二.环境准备 前言 Spring Security企业安全认证系列文章,本专栏内容目前已经比较系统了,核心内容也相对完整,本系列文章会根据Spring Security社区的发展逐步的更新内容.请大家多多关注我们~ 前文传送门: SpringSecurity框架简介及与shiro特点对比 一.需求分析 login.html登录页面,登录页面访问不受限制 在登录页面登录之后,进入index.html首页(登录验证Authentication) 首页可以看到syslog.s