Mybatis 大数据量批量写优化的案例详解
目录
- Mybatis 大数据量批量写优化
- 附录:Mybatis批量处理优化
- 普通插入
- foreach 优化插入
Mybatis 大数据量批量写优化
在项目中使用批量数据插入,经常会用到 mybatis的 foreach,如下:
<insert id="batchInsert" parameterType="java.util.List">
insert into USER (id, name) values
<foreach collection="list" item="model" index="index" separator=",">
(#{model.id}, #{model.name})
</foreach>
</insert>
就是将
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
转换成
INSERT INTO `table1` (`field1`, `field2`)
VALUES ("data1", "data2"),
("data1", "data2"),
("data1", "data2"),
("data1", "data2"),
("data1", "data2");
从理论上将,复用conn,将多次io,转换成一次io,应该是提升效率的。但是实际上当数据量比较大的时候,用foreach效率非常低,速度非常慢
当表的列数较多(20+),以及一次性插入的行数较多(5000+)时,整个插入的耗时十分漫长,达到了14分钟,这是不能忍的
那为什么使用使用foreach效率如此之低呢??
Mybatis默认执行器类型为Simple,默认会为每一个sql产生一个PrepareStatement,而且对于foreach无法使用缓存。如果字段和行数非常多,那么sql必然也会很长,占位符也会非常多,除此之外还要建立占位符和参数之间的映射,那么解析时间必然会长。因此如果values行数越多,那么解析时间必然很长。执行效率低。
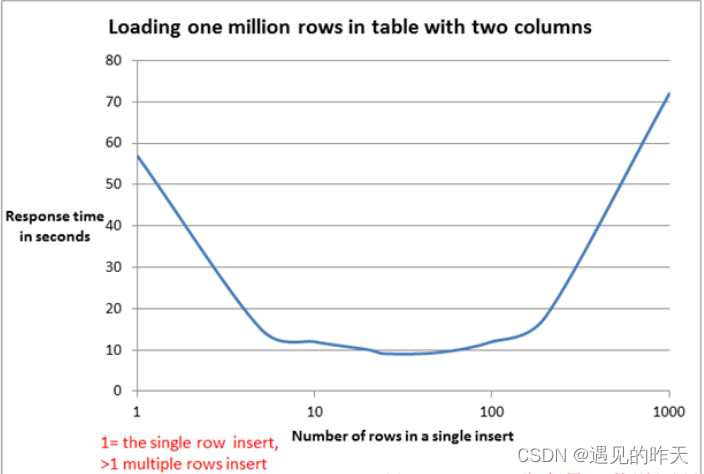
如果非要使用 foreach 的方式来进行批量插入的话,可以考虑减少一条 insert 语句中 values 的个数,最好能达到上面曲线的最底部的值,使速度最快。一般按经验来说,一次性插20~50行数量是比较合适的,时间消耗也能接受。
那么如果要用批量插入,改如何优化呢?
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
try {
SimpleTableMapper mapper = session.getMapper(SimpleTableMapper.class);
List<SimpleTableRecord> records = getRecordsToInsert(); // not shown
BatchInsert<SimpleTableRecord> batchInsert = insert(records)
.into(simpleTable)
.map(id).toProperty("id")
.map(firstName).toProperty("firstName")
.map(lastName).toProperty("lastName")
.map(birthDate).toProperty("birthDate")
.map(employed).toProperty("employed")
.map(occupation).toProperty("occupation")
.build()
.render(RenderingStrategy.MYBATIS3);
batchInsert.insertStatements().stream().forEach(mapper::insert);
session.commit();
} finally {
session.close();
}
基本思想是将 MyBatis session 的 executor type 设为 Batch ,然后通过遍历多次执行插入语句
就类似于JDBC的下面语句一样。
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/mydb?useUnicode=true&characterEncoding=UTF-8&useServerPrepStmts=false&rewriteBatchedStatements=true","root","root");
connection.setAutoCommit(false);
PreparedStatement ps = connection.prepareStatement(
"insert into tb_user (name) values(?)");
for (int i = 0; i < stuNum; i++) {
ps.setString(1,name);
ps.addBatch();
}
ps.executeBatch();
connection.commit();
connection.close();
附录:Mybatis批量处理优化
Mybatis内置的ExecutorType有3种,默认的是simple单句模式,该模式下它为每个语句的执行创建一个新的预处理语句,单句提交sql;batch模式重复使用已经预处理的语句,并且批量执行所有语句,大批量模式下性能更优。
请注意batch模式在Insert操作时事务没有提交之前,是没有办法获取到自增的id,所以请根据业务情况使用。
使用simple模式提交10000条数据,时间为19s,batch模式为6s ,大致情况如此,优化的具体还要看提交的语句情况。
如果需要使用 foreach来优化数据插入的话,需要将每次插入的记录控制在 10-100 左右是比较快的,建议每次100来分割数据,也就是分而治之思想。
普通插入
默认的插入方式是遍历insert语句,单条执行,效率肯定低下,如果成堆插入,更是性能有问题。
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
INSERT INTO `table1` (`field1`, `field2`) VALUES ("data1", "data2");
foreach 优化插入
如果要优化插入速度时,可以将许多小型操作组合到一个大型操作中。理想情况下,这样可以在单个连接中一次性发送许多新行的数据,并将所有索引更新和一致性检查延迟到最后才进行。
<insert id="batchInsert" parameterType="java.util.List">
insert into table1 (field1, field2) values
<foreach collection="list" item="t" index="index" separator=",">
(#{t.field1}, #{t.field2})
</foreach>
</insert>
翻译成sql语句也就是
INSERT INTO `table1` (`field1`, `field2`)
VALUES ("data1", "data2"),
("data1", "data2"),
("data1", "data2"),
("data1", "data2"),
("data1", "data2");
到此这篇关于Mybatis 大数据量批量写优化的文章就介绍到这了,更多相关Mybatis 批量写优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解mybatis批量插入10万条数据的优化过程
数据库 在使用mybatis插入大量数据的时候,为了提高效率,放弃循环插入,改为批量插入,mapper如下: package com.lcy.service.mapper; import com.lcy.service.pojo.TestVO; import org.apache.ibatis.annotations.Insert; import java.util.List; public interface TestMapper { @Insert("") Integer test
-
Java 处理高并发负载类优化方法案例详解
java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,java高负载数据) 一:高并发高负载类网站关注点之数据库 没错,首先是数据库,这是大多数应用所面临的首个SPOF.尤其是Web2.0的应用,数据库的响应是首先要解决的. 一般来说MySQL是最常用的,可能最初是一个mysql主机,当数据增加到100万以上,那么,MySQL的效能急剧下降.常用的优化措施是M-S(主-从)方式进行同步复制,将查询和操作和分别在不同的服务器上进行操作.我推荐的是M-M-Slaves
-
Java for循环常见优化方法案例详解
目录 方法一:最常规的不加思考的写法 方法二:数组长度提取出来 方法三:数组长度提取出来 方法四:采用倒序的写法 方法五:Iterator 遍历 方法六:jdk1.5后的写法 方法七:循环嵌套外小内大原则 方法八:循环嵌套提取不需要循环的逻辑 方法九:异常处理写在循环外面 前言 我们都经常使用一些循环耗时计算的操作,特别是for循环,它是一种重复计算的操作,如果处理不好,耗时就比较大,如果处理书写得当将大大提高效率,下面总结几条for循环的常见优化方式. 首先,我们初始化一个集合 list,如下
-
解决Mybatis 大数据量的批量insert问题
前言 通过Mybatis做7000+数据量的批量插入的时候报错了,error log如下: , ('G61010352', '610103199208291214', '学生52', 'G61010350', '610103199109920192', '学生50', '07', '01', '0104', ' ', , ' ', ' ', current_timestamp, current_timestamp ) 被中止,呼叫 getNextException 以取得原因. at org.p
-
大数据量高并发的数据库优化详解
如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. 一.数据库结构的设计 在一个系统分析.设计阶段,因为数据量较小,负荷较低.我们往往只注意到功能的实现,而很难注意到性能的薄弱之处,等到系统投入实际运行一段时间后,才发现系统的性能在降低,这时再来考虑提高系统性能则要花费更多的人力物力,而整个系统也不可避免的形成了一个打补丁工程. 所以在考虑整个系统的流程的时候,我们必须
-
一次Mysql使用IN大数据量的优化记录
mysql版本号是5.7.28,表A有390W条记录,使用InnoDB引擎,其中varchar类型字段mac已建立索引,索引方法为B-tree.B表仅有5000+条记录. 有一条SQL指令是这样写的: SELECT * FROM A WHERE mac IN("aa:aa:aa:aa:aa:aa","bb:bb:bb:bb:bb:b",...此外省略900+条) 通过查询出来的结果耗时294.428s.没错,将近5分钟. 使用EXPLAIN分析下: 访问类型type
-
java 较大数据量取差集,list.removeAll性能优化详解
今天在优化项目中的考勤同步功能时遇到将考勤机中的数据同步到数据库, 两边都是几万条数据的样子,老代码的做法差不多半个小时,优化后我本机差不多40秒,服务器速度会更加理想. 两个数据集取差集首先想到的方法便是List.removeAll方法,但是实验发现jdk自带的List.removeAll效率很低 List.removeAll效率低原因: List.removeAll效率低和list集合本身的特点有关 : List底层数据结构是数组,查询快,增删慢 1.List.contains()效率没有h
-
Mysql大数据量查询优化思路详析
目录 1. 千万级别日志查询的优化 2. 几百万黑名单库的查询优化 3. Mybatis批量插入处理问题 项目场景: Mysql大表查询优化,理论上千万级别以下的数据量Mysql单表查询性能处理都是可以的. 问题描述: 在我们线上环境中,出现了mysql几千万级别的日志查询.几百万级别的黑名单库查询分页查询及条件查询都慢的问题,针对Mysql表优化做了一些优化处理. 原因分析:首先说一下日志查询,在Mysql中如果索引加的比较合适,走索引情况下千万级别查询不会超过一秒,Mysql查询的速度和检索
-
大数据量时提高分页的效率
如我们在之前的教程里讨论的那样,分页可以通过两种方法来实现: 默认分页– 你仅仅只用选中data Web control的 智能标签的Enable Paging ; 然而,当你浏览页面的时候,虽然你看到的只是一小部分数据,ObjectDataSource 还是会每次都读取所有数据 自定义分页– 通过只从数据库读取用户需要浏览的那部分数据,提高了性能. 显然这种方法需要你做更多的工作. 默认的分页功能非常吸引人,因为你只需要选中一个checkbox就可以完成了.但是它每次都读取所有的数据,这种方式
-
针对Sqlserver大数据量插入速度慢或丢失数据的解决方法
我的设备上每秒将2000条数据插入数据库,2个设备总共4000条,当在程序里面直接用insert语句插入时,两个设备同时插入大概总共能插入约2800条左右,数据丢失约1200条左右,测试了很多方法,整理出了两种效果比较明显的解决办法: 方法一:使用Sql Server函数: 1.将数据组合成字串,使用函数将数据插入内存表,后将内存表数据复制到要插入的表. 2.组合成的字符换格式:'111|222|333|456,7894,7458|0|1|2014-01-01 12:15:16;1111|222
-
在ASP.NET 2.0中操作数据之二十五:大数据量时提高分页的效率
导言 如我们在之前的教程里讨论的那样,分页可以通过两种方法来实现: 1.默认分页– 你仅仅只用选中data Web control的 智能标签的Enable Paging ; 然而,当你浏览页面的时候,虽然你看到的只是一小部分数据,ObjectDataSource 还是会每次都读取所有数据 2.自定义分页– 通过只从数据库读取用户需要浏览的那部分数据,提高了性能. 显然这种方法需要你做更多的工作. 默认的分页功能非常吸引人,因为你只需要选中一个checkbox就可以完成了.但是它每次都读取所有的