Python采集C站高校信息实战示例
目录
- 前言
- 功能实现
- 内容获取
- 总结
前言
大家好,我们今天来爬取c站的高校名单,把其高校名单,成员和内容数获取下来,不过,我们发现这个网站比我们平时多了一个验证,下面看看我是怎么解决的。
功能实现
话不多说,我们和平时一样,发送我们的请求,按照平时,我们看看代码怎么写。
url = 'https://bizapi.csdn.net/community-cloud/v1/homepage/community/by/tag?deviceType=PC&tagId=37'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
response = requests.get(url=url,headers=headers)
我们在这里使用 requests 库发送 GET 请求,并将 URL 和请求头作为参数传递给 get 方法。请求的 URL 是 https://bizapi.csdn.net/community-cloud/v1/homepage/community/by/tag?deviceType=PC&tagId=37,表示查询社区根据标签分类的数据。请求头包含了 User-Agent 和 Accept 字段,分别表示客户端的 User-Agent 和 Accept 协议类型。
不过我们会发现,我们得不到数据,就说明我们被反爬了,我尝试了很多次,我们发现它做了一个验证。
headers = {
'accept': 'application/json, text/plain, */*',
'origin': 'https://bbs.csdn.net',
'referer': 'https://bbs.csdn.net/college?utm_source=csdn_bbs_toolbar&spm=1035.2022.3001.8850&category=37',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'x-ca-key': '203899271',
'x-ca-nonce': '13b10c23-6a9b-423e-92a7-b114bc2c7f48',
'x-ca-signature': 'Hhnf/RUARDM2jddNAkl2tJ6hpXfweWbY1U4/yh6FCZM=',
'x-ca-signature-headers': 'x-ca-key,x-ca-nonce',
}
我们这里科普一下,x-ca-signature 是对请求内容的签名,用于验证请求的完整性和可信性。 签名通常是通过使用私钥和一种哈希算法(如 SHA256)对请求内容进行计算得到的。 如果请求头中出现这三个参数,放心,是为了反爬用的,当然也可以用于限制请求频率,防止恶意攻击。
在解决该反爬问题时,第一步就是要找到他们的加密点。寻找 x-ca-key、x-ca-nonce、x-ca-signature 加密位置这一步主要看你对开发者工具的使用熟练程度了,寻找任意一个携带该请求头参数的请求,然后添加相应断点。通过请求地址中的部分关键字,即可添加 XHR 断点。再次刷新页面,可进入断点中,一般会停留在send()函数位置。 下面的步骤就是比较枯燥的了,需要一点点的解密,例如在本函数头部找到headers,发现其参数 x-ca-key、x-ca-nonce、x-ca-signature 已经被赋值。
这里我们没有做多页爬虫,就没有去解密了,感兴趣的朋友自己去尝试。
内容获取
我们拿到了数据,接下来就可以提取内容了,我们看看代码怎么写,这里就很简单了。
data =responses.json()['data']
for list in data:
tagName = list['tagName']
list_url= list['url']
res = requests.get(list_url)
num = re.findall('<div title="(\d+)"',res.text)
print(tagName,list_url,num)
我们这里使用 responses.json()['data'] 读取 API 响应 JSON 数据,并在一个数组中提取数据。然后,它使用一个 for 循环遍历数组中的每个元素,提取 tagName 和 url 两个字段,并使用 requests.get() 发送 GET 请求获取数据。最后,它使用正则表达式从响应文本中提取 num 数据,并将其打印到控制台上。
总结
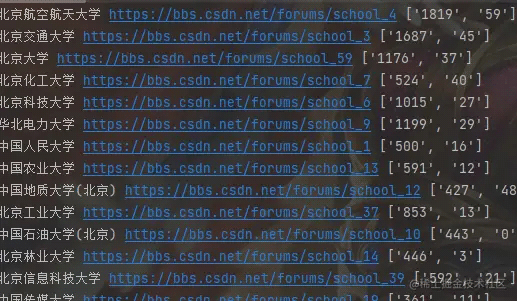
我们这样就获取到了内容,本文仅供学习,更多关于Python采集C站高校信息的资料请关注我们其它相关文章!
相关推荐
-
Python采集二手车数据的超详细讲解
目录 数据采集 发送请求 明确需求: 解析数据 保存数据 总结 数据采集 XPath,XML路径语言的简称.XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言.XPath主要用于解析XML文档,可以用来获取XML文档中某个元素的位置.属性值等信息.XPath可以用于XML文档解析.XML数据抽取.XML路径匹配等方面. 发送请求 首先,我们要进行数据来源分析,知道我们的需求是什么? 明确需求: 明确采集网站是什么? 明确采集数据是什么
-
Python采集热搜数据实现详解
目录 功能实现 发送请求 解析数据 获取内容 拓展内容 总结 功能实现 随着互联网的发展,信息的传播越来越快速和便捷.在这个信息爆炸的时代,如何快速获取有用的信息已经成为了一个重要的能力.而爬取网站信息则是获取信息的一种重要方式.本文将介绍如何使用Python爬取百度热搜,并对爬取过程进行详细说明. 其实,这个并不难.现在,看我是如何一步一步获取到数据的. 发送请求 我们首先确定网址,我们先使用开发者工具,定位到我们要的数据.发现,内容就在网页源代码中. urllib = 'https://to
-
Python采集某评论区内容的实现示例
目录 前言 发送请求 解析数据 总结 前言 我们知道在这个互联网时代,评论已经在我们的生活到处可见,评论区里面的信息是一个非常有趣和有争议的地方.我们今天,就来获取某技术平台的评论,和大家分享一下,我获取数据的过程,也是一个尝试的过程. 发送请求 我们首先,确定我们要获取哪一个文章下面的评论区.我们先使用开发者工具,定位到我们要的数据. 我们通过数据抓取,我们发现,这个平台的评论区数据,放在了一个叫getlist数据包里面了. 我们就不难明白,我们只要请求这个url,在传一个关于文章的参数,我们
-
Python采集C站热榜数据实战示例
目录 前言 功能实现 解析数据 保存数据 总结 前言 大家好,我们今天来爬取c站的热搜榜,把其文章名称,链接和作者获取下来,我们保存到本地,我们通过测试,发现其实很简单,我们只要简单获取数据就可以.没有加密的东西. 功能实现 我们话不多说,我们先找到url,也就是请求地址.我们代码如下: url = 'https://blog.csdn.net/phoenix/web/blog/hot-rank?page=0&pageSize=25&type=' headers = { 'user-age
-
Python采集情感音频的实现示例
目录 前言 发送请求 获取数据 解析数据 保存数据 总结 前言 我最近喜欢去听情感类的节目,比如说,婚姻类,我可能老了吧.我就想着怎么把音乐下载下来了,保存到手机上,方便我们业余时间去听. 发送请求 首先,我们要确定我们的目标网址,我们想要获取到每一个音频的地址. 我们发送请求,获取网页源代码.我们相信大家这里的代码都会写了. url = 'https://www.ximalaya.com/album/37453303' headers = { 'User-Agent': 'Mozilla/5.
-
Python爬取附近餐馆信息代码示例
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): # 模拟使用浏览器浏览大众点评的方式浏览大众点评 headers = {'User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} ope
-
Python获取B站粉丝数的示例代码
要使用代码,需要安装Python 3.x,并且要安装库,在cmd输入pip install requests json time 复制代码,修改最上方变量改成你自己的UID,保存为xxx.py,运行就可以了 用于学习了解的核心代码: import requests import json bilibili_api = requests.get("http://api.bilibili.com/x/relation/stat?vmid=1") # 访问网址,数据存到变量,1是用户UID
-

Python爬取城市租房信息实战分享
目录 一.单线程爬虫 二.优化为多线程爬虫 三.使用asyncio进一步优化 四.存入Mysql数据库 (一)建表 (二)将数据存入数据库中 五.最终效果图 (已打码) 思路:先单线程爬虫,测试可以成功爬取之后再优化为多线程,最后存入数据库 以爬取郑州市租房信息为例 注意:本实战项目仅以学习为目的,为避免给网站造成太大压力,请将代码中的num修改成较小的数字,并将线程改小 一.单线程爬虫 # 用session取代requests # 解析库使用bs4 # 并发库使用concurrent impo
-
Python爬虫实战演练之采集拉钩网招聘信息数据
目录 本文要点: 环境介绍 本次目标 爬虫块使用 内置模块: 第三方模块: 代码实现步骤: (爬虫代码基本步骤) 开始代码 导入模块 发送请求 解析数据 加翻页 保存数据 运行代码,得到数据 本文要点: 爬虫的基本流程 requests模块的使用 保存csv 可视化分析展示 环境介绍 python 3.8 pycharm 2021专业版 激活码 Jupyter Notebook pycharm 是编辑器 >> 用来写代码的 (更方便写代码, 写代码更加舒适) python 是解释器 >&
-
Python编程实现下载器自动爬取采集B站弹幕示例
目录 实现效果 UI界面 数据采集 小结 大家好,我是小张! 在<Python编程实现小姐姐跳舞并生成词云视频示例>文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕:思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数.写代码,重复单调: 因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载 实现效果 基于此,借助 PyQt5
-
ffmpeg+Python实现B站MP4格式音频与视频的合并示例代码
安装 官网下载 http://ffmpeg.org/ 选择需要的版本 在这个网址下载ffmpeg,https://github.com/BtbN/FFmpeg-Builds/releases 将解压后得到的以下几个文件放置在E:\FFmpeg下 环境变量 此电脑--属性--高级系统设置--环境变量 在系统变量(也就是下面那一半)处找到新建,按如下所示的方法填写 再将%FFMPEG_HOME%以及%FFMPEG_HOME%\bin写入系统变量的Path中 然后一路确定即可 验证 win+R,cmd
-
Python探索之爬取电商售卖信息代码示例
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 下面有一个示例代码,分享给大家: #! /usr/bin/env python # encoding = 'utf-8'# Filename: spider_58center_sth.py from bs4 import BeautifulSoup import time import requests url_58 = 'http://nj.58.c
-
python登录并爬取淘宝信息代码示例
本文主要分享关于python登录并爬取淘宝信息的相关代码,还是挺不错的,大家可以了解下. #!/usr/bin/env python # -*- coding:utf-8 -*- from selenium import webdriver import time import datetime import traceback import logging import os from selenium.webdriver.common.action_chains import ActionC
-
Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码
一位伙计自己开了个游戏室,想在群里拉点人,就用所学知识帮帮忙,于是就有了这篇文章,今天小编特此通过实例代码给大家介绍下Python selenium 加载并保存QQ群成员去除其群主.管理员信息的示例代码 模拟登陆页面 页面分析 思路: 点击登陆按钮 选择要登陆的账号 代码实现 # Author:smart_num_1 # Blog:https://blog.csdn.net/smart_num_1 # WeChat:Be_a_lucky_dog from selenium import webd
-
Python爬取网页信息的示例
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初始网址,逐层查找链接,直到找到需要获取的内容. 在打开的界面中,点击鼠标右键,在弹出的对话框中,选择"检查",则在界面会显示该网页的源代码,在具体内容处点击查找,可以定位到需要查找的内容的源码. 注意:代码显示的方式与浏览器有关,有些浏览器不支持显示源代码功能(360浏览器,谷歌浏览器,火