python如何实现排序,并标上序号
目录
- python排序并标上序号
- (1)method =‘first’ 时
- (2)method='min’时
- (3)method='max’时
- (4)method='dense’时
- Python常见排序算法汇总
- 排序的稳定性
- 内排序和外排序
- Python常用排序算法
python排序并标上序号
需求:利用python实现排序功能
测试数据:data.csv
"id","date","amount" "1","2019-02-08","6214.23" "1","2019-02-08","6247.32" "1","2019-02-09","85.63" "2","2019-02-14","943.18" "2","2019-02-15","369.76" "2","2019-02-18","795.15" "2","2019-02-19","715.65" "2","2019-02-21","537.71" "2","2019-02-24","1037.71" "3","2019-02-09","967.36" "3","2019-02-10","85.69" "3","2019-02-12","769.85" "3","2019-02-13","943.86" "3","2019-02-19","843.86" "3","2019-02-11","85.69" "3","2019-02-14","843.86" "1","2019-02-10","985.63" "1","2019-02-09","285.63" "1","2019-02-11","1285.63"
第一种常见排序: 将上面数据按照amount字段进行排序
import pandas as pd filename="data.csv" df=pd.read_csv(filename) #增加一个rank排序字段 df['rank']=df['amount'].rank(ascending=0, method='first')
说明:ascending :1 表示升序,0表示降序
method:此参数的作用是,当遇到两个值相同时,排序处理的方式。可以取的值有 first、max、min、dense
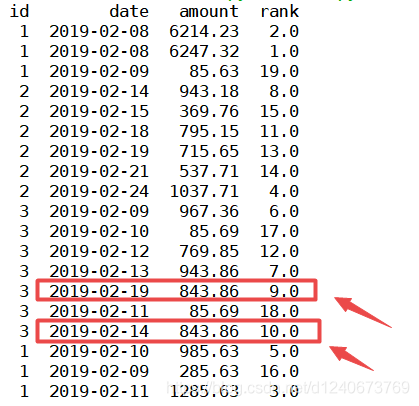
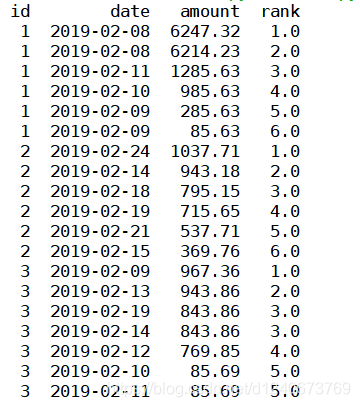
(1)method =‘first’ 时
表示排序时,序号不会重复且是连续的,遇到相同的值时,会按照数据的先后顺序标序号,如下图:
df['rank']=df['amount'].rank(ascending=0, method='first') print(df)
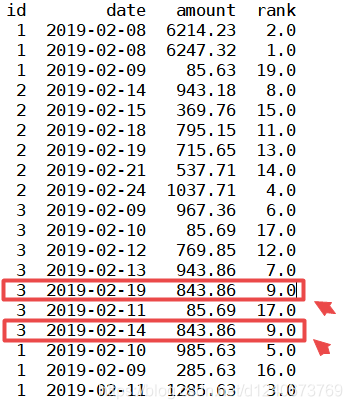
(2)method='min’时
表示排序时,遇到相同的值时,后面数的序号与最先出现的数的序号保持一致,如下图,843.86值重复两次,排名均为9,且排序中没有序号10(序号不连续)
df['rank']=df['amount'].rank(ascending=0, method='min') print(df)
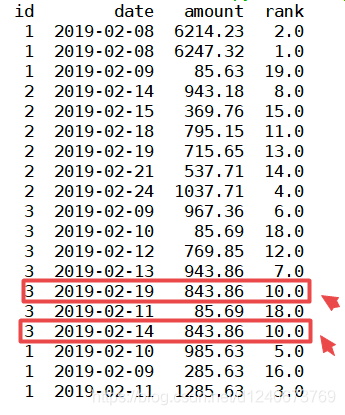
(3)method='max’时
表示排序时,遇到相同的值时,后面数的序号与最后出现的数的序号保持一致,如下图,843.86值重复两次,排名均为10,且排序中没有序号9(序号不连续)
df['rank']=df['amount'].rank(ascending=0, method='max') print(df)
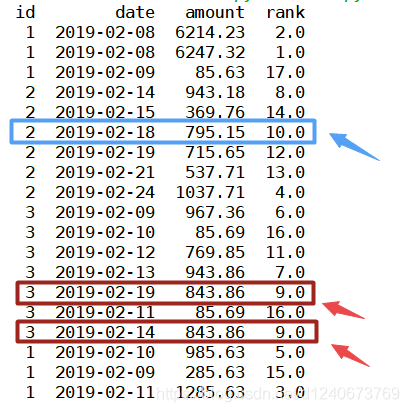
(4)method='dense’时
表示排序时,遇到相同的值时,重复值序号保持一致,如下图,843.86值重复两次,排名均为9,且下一个数序号为10,序号保持连续
df['rank']=df['amount'].rank(ascending=0, method='dense') print(df)
第二种常见排序:组内排序 ,将上面数据根据id分组,并按照amount字段进行组内排序
df['rank']=df['amount'].groupby(df['id']).rank(ascending=0, method='dense') #对结果按照id和rank进行升序排列 data=df.sort_values(by=['id','rank'],ascending=(1,1))
Python常见排序算法汇总
所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。排序算法,就是如何使得记录按照要求排列的方法。
排序的稳定性
经过某种排序后,如果两个记录序号同等,且两者在原无序记录中的先后秩序依然保持不变,则称所使用的排序方法是稳定的,反之是不稳定的。
内排序和外排序
- 内排序:排序过程中,待排序的所有记录全部放在内存中
- 外排序:排序过程中,使用到了外部存储。
通常讨论的都是内排序。
影响内排序算法性能的三个因素:
- 时间复杂度:即时间性能,高效率的排序算法应该是具有尽可能少的关键字比较次数和记录的移动次数
- 空间复杂度:主要是执行算法所需要的辅助空间,越少越好。
- 算法复杂性。主要是指代码的复杂性。
Python常用排序算法
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python实现排序方法常见的四种
1.冒泡排序,相邻位置比较大小,将比较大的(或小的)交换位置 def maopao(a): for i in range(0,len(a)): for j in range(0,len(a)-i-1): if a[j]>a[j+1]: temp = a[j+1] a[j+1] = a[j] a[j] = temp #print(a) #print(a) print(a) 2.选择排序,遍历选择一个最小的数与当前循环的第一个数交换 def xuanze(a): for i in range(0,l
-
python pandas 组内排序、单组排序、标号的实例
摘要:本文主要是讲解一下,如何进行排序.分为两种情况,不分组进行排序和组内进行排序.什么意思呢?具体来说,我举个栗子. ****注意**** 如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了.下文是关于如何把序号也打上的 ---------------------------- 我们有一个数据集如下: 我们下面想进行两种排序.先说第一种比较简单的也是很常用的,简单的对某一列进行排序然后添加一列序号. 例如,我们队comment_num这一列进行从大到小的
-
python 实现对文件夹内的文件排序编号
使用时,需更改rootdir, 即文件保存的路径,以及要保存的格式,例如'.jpg' 如果排序前后文件格式一样,建议先随便换个格式,然后再换回来,也就是程序运行两次,第一次随便换个格式,第二次换成想要的格式. #!usr/bin/env python import os import os.path rootdir = "C:\\Users\\IronMan\\Desktop\\launch\\" files = os.listdir(rootdir) b=0 for name in
-

python排序算法的简单实现方法
1 冒泡排序 1.1 算法步骤: 比较相邻的元素.如果第一个比第二个大,就交换他们两个. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.这步做完后,最后的元素会是最大的数. 针对所有的元素重复以上的步骤,除了最后一个. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较. (1) 不管原始数组是否有序,时间复杂度都是O(n2) (2) 空间复杂度是O(1) (3) 冒泡排序是从最后一位开始确定最大或最小的数,保证后面的数都是有序的且都大于或小于前面的数 1.2 算
-
python如何实现排序,并标上序号
目录 python排序并标上序号 (1)method =‘first’ 时 (2)method='min’时 (3)method='max’时 (4)method='dense’时 Python常见排序算法汇总 排序的稳定性 内排序和外排序 Python常用排序算法 python排序并标上序号 需求:利用python实现排序功能 测试数据:data.csv "id","date","amount" "1","2019
-
python实现八大排序算法(2)
本文接上一篇博客python实现的八大排序算法part1,将继续使用python实现八大排序算法中的剩余四个:快速排序.堆排序.归并排序.基数排序 5.快速排序 快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的. 算法思想: 已知一组无序数据a[1].a[2].--a[n],需将其按升序排列.首先任取数据a[x]作为基准.比较a[x]与其它数据并排序,使a[x]排在数据的第k位,并且使a[1]~a[k-1]中的每一个数据<a[x],a[k+1]~a[n]中的每一个数
-
python实现八大排序算法(1)
排序 排序是计算机内经常进行的一种操作,其目的是将一组"无序"的记录序列调整为"有序"的记录序列.分内部排序和外部排序.若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序.反之,若参加排序的记录数量很大,整个序列的排序过程不可能完全在内存中完成,需要访问外存,则称此类排序问题为外部排序.内部排序的过程是一个逐步扩大记录的有序序列长度的过程. 看图使理解更清晰深刻: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序
-
Python实现八大排序算法
如何用Python实现八大排序算法 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的.个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为 O(n^2).是稳定的排序方法.插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插 入的位置),而第二部分就只包含这一个元素(即待插入元素).在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中. 代码实现 def insert_
-
Python实现希尔排序算法的原理与用法实例分析
本文实例讲述了Python实现希尔排序算法的原理与用法.分享给大家供大家参考,具体如下: 希尔排序(Shell Sort)是插入排序的一种.也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本. 希尔排序的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个"增量"的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序.因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高
-
Python八大常见排序算法定义、实现及时间消耗效率分析
本文实例讲述了Python八大常见排序算法定义.实现及时间消耗效率分析.分享给大家供大家参考,具体如下: 昨晚上开始总结了一下常见的几种排序算法,由于之前我已经写了好几篇排序的算法的相关博文了现在总结一下的话可以说是很方便的,这里的目的是为了更加完整详尽的总结一下这些排序算法,为了复习基础的东西,从冒泡排序.直接插入排序.选择排序.归并排序.希尔排序.桶排序.堆排序.快速排序入手来分析和实现,在最后也给出来了简单的时间统计,重在原理.算法基础,其他的次之,这些东西的熟练掌握不算是对之后的工作或者
-
python爬虫租房信息在地图上显示的方法
本人初学python是菜鸟级,写的不好勿喷. python爬虫用了比较简单的urllib.parse和requests,把爬来的数据显示在地图上.接下里我们话不多说直接上代码: 1.安装python环境和编辑器(自行度娘) 2.本人以58品牌公寓为例,爬取在杭州地区价格在2000-4000的公寓. #-*- coding:utf-8 -*- from bs4 import BeautifulSoup from urllib.parse import urljoin import requests
-
python按时间排序目录下的文件实现方法
废话不多说,直接上代码: python文件夹遍历,文件操作,获取文件修改创建时间可以去网上参考其他文章. 如: os.path.getmtime() 函数是获取文件最后修改时间 os.path.getctime() 函数是获取文件最后创建时间 def get_file_list(file_path): dir_list = os.listdir(file_path) if not dir_list: return else: # 注意,这里使用lambda表达式,将文件按照最后修改时间顺序升序排
-
python给list排序的简单方法
大家有没有发现,当在网站上检索,想找到的内容,输入一个关键词时,检索栏下会出现输入关键词的拓词和问题.输入的关键词越多,越有可能找的你想要的问题.其实会出现这种情况是由于计算机算法的排序,会根据关键词关联.搜索量等原因排序.那你知道在python中如何给列表排序吗?今天,小编教教大家如何给列表排序. sort()方法 会对list中元素按照大小进行排序 list.sort(key=None,reverse=False) 实例: In [57]: l=[27,47,3,42,19,9] In [5
-
Python关于拓扑排序知识点讲解
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前. 通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列.简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序. 在图论中,由一个有向无环图的顶点组成的序列,当且仅当满足下列条件时,称为该图的一个拓扑排序(英语:Topolog