python 利用panda 实现列联表(交叉表)
交叉表(cross-tabulation,简称crosstab)是⼀种⽤于计算分组频率的特殊透视表。
语法详解:
pd.crosstab(index, # 分组依据 columns, # 列 values=None, # 聚合计算的值 rownames=None, # 列名称 colnames=None, # 行名称 aggfunc=None, # 聚合函数 margins=False, # 总计行/列 dropna=True, # 是否删除缺失值 normalize=False # )
1 crosstab() 实例1
1.1 读取数据
import os
import numpy as np
import pandas as pd
file_name = os.path.join(path, 'Excel_test.xls')
df = pd.read_excel(io=file_name, # 工作簿路径
sheetname='透视表', # 工作表名称
skiprows=1, # 要忽略的行数
parse_cols='A:D' # 读入的列
)
df

1.2 pd.crosstab() 默认生成以行和列分类的频数表
pd.crosstab(df['客户名称'], df['产品类别'])
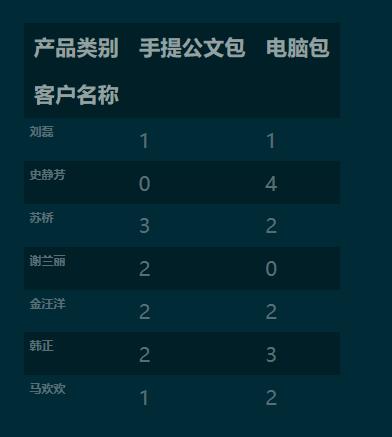
1.3 设置跟多参数实现分类汇总
pd.crosstab(index=df['客户名称'],
columns=df['产品类别'],
values=df['销量'],
aggfunc='sum',
margins=True
).round(0).fillna(0).astype('int')

注:因为交叉表示透视表的特例,所以交叉表可以用透视表的函数实现。又因为透视表可以用更 python 的方式 groupby-apply 实现,所以,交叉表完全可以用 groupby-apply 的方式实现。
2 用分类汇总的方法实现 交叉表
df.groupby(['客户名称', '产品类别']).apply(sum)

2.1 分类汇总、重新索引、设置数值格式综合应用
c_tbl = df.groupby(['客户名称', '产品类别']).apply(sum)['销量'].unstack()
c_tbl['总计'] = c_tbl.sum(axis=1) # 添加总计列
c_tbl.fillna(0).round(0).astype('int')

软件信息:

补充:使用python(pandas)将数据处理成交叉分组表
交叉分组表是汇总两种变量数据的方法, 在很多场景可以用到, 本文会介绍如何使用pandas将包含两个变量的数据集处理成交叉分组表.
环境
pandas
python 2.7
原理
用坐标轴来进行比喻, 其中一个变量作为x轴, 另一个作为y轴, 如果定位到数据则累加一, 将所有数据遍历一遍, 最后的坐标轴就是一张交叉分组表(使用坐标轴展示的数据一般是连续的, 交叉分组表的数据是离散的).
具体实现
示例数据:
quality price 0 bad 18 1 bad 17 2 great 52 3 good 28 4 excellent 88 5 great 63 6 bad 8 7 good 22 8 good 68 9 excellent 98 10 great 53 11 bad 13 12 great 62 13 good 48 14 excellent 78 15 great 63 16 good 37 17 great 69 18 good 28 19 excellent 81 20 great 43 21 good 32 22 great 62 23 good 28 24 excellent 82 25 great 53
代码:
import pandas as pd
from pandas import DataFrame, Series
#生成数据
df = DataFrame([['bad', 18], ['bad', 17], ['great', 52], ['good', 28], ['excellent', 88], ['great', 63]
, ['bad', 8], ['good', 22], ['good', 68], ['excellent', 98], ['great', 53]
, ['bad', 13], ['great', 62], ['good', 48], ['excellent', 78], ['great', 63]
, ['good', 37], ['great', 69], ['good', 28], ['excellent', 81], ['great', 43]
, ['good', 32], ['great', 62], ['good', 28], ['excellent', 82], ['great', 53]], columns = ['quality', 'price'])
#广播使用的函数
def quality_cut(data):
s = Series(pd.cut(data['price'], np.arange(0, 100, 10)))
return pd.groupby(s, s).count()
#进行分组处理
df.groupby(df['quality']).apply(quality_cut)
结果:

交叉分组
详细分析
从逻辑上来看, 为了达到对示例数据的交叉分组, 需要完成以下工作:
将数据以quality列进行分组.
将每个分组的数据分别进行cut, 以10为间隔.
将cut过的数据, 以cut的范围为列进行分组
将所有数据组合到一起, row为quality, columns为cut的范围
步骤1, pandasgroupby(...)接口, 会按照指定的列进行分组处理, 每一个分组, 存储相同类别的数据
<class 'pandas.core.frame.DataFrame'> quality price 0 bad 18 1 bad 17 6 bad 8 11 bad 13
而我们需要的, 只是price这列的数据, 所以单独将这列拿出来, 进行cut, 最后得到我们要的series(步骤2, 步骤3)
price (0, 10] 1 (10, 20] 3 (20, 30] 0 (30, 40] 0 (40, 50] 0 (50, 60] 0 (60, 70] 0 (70, 80] 0 (80, 90] 0
使用pandas
apply()的广播特性, 每一个分组的数据都会经过上述几个步骤的处理, 最后与第一次分组row进行组合.
后记
估计能力有限, 这个问题想了很长时间, 没想到pandas这么可以这么方便达成交叉分组的效果. 思考的时候主要是卡在数据组合上, 当数据量很大时通过多个步骤进行数据组合, 肯定是低效而且错误的. 最后仔细研究了groupby, dataframe, series, dataframeIndex等数据模型, 使用广播特性用几句代码就完成了. 证明了pandas的高性能, 也提醒自己遇见问题一定要耐心分析。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python Pandas分组聚合的实现方法
Pycharm 鼠标移动到函数上,CTRL+Q可以快速查看文档,CTR+P可以看基本的参数. apply(),applymap()和map() apply()和applymap()是DataFrame的函数,map()是Series的函数. apply()的操作对象是DataFrame的一行或者一列数据,applymap()是DataFrame的每一个元素.map()也是Series中的每一个元素. apply()对dataframe的内容进行批量处理, 这样要比循环来得快.如df.apply(
-
python之pandas用法大全
一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1)) df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001
-
Python3 pandas 操作列表实例详解
1.首先需要安装pandas, 安装的时候可能由依赖的包需要安装,根据运行时候的提示,缺少哪个库,就pip 安装哪个库. 2.示例代码 import pandas as pd from pandas import ExcelWriter EX_PATH = "E:\\code\\test2.xlsx" #读取excel里面的内容 data = pd.read_excel(EX_PATH,sheet_name='Sheet1') #新增加一列内容 lista = [21, 21, 20,
-
Python pandas用法最全整理
1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as npimport pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1))df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001,1002,1003
-

python 利用panda 实现列联表(交叉表)
交叉表(cross-tabulation,简称crosstab)是⼀种⽤于计算分组频率的特殊透视表. 语法详解: pd.crosstab(index, # 分组依据 columns, # 列 values=None, # 聚合计算的值 rownames=None, # 列名称 colnames=None, # 行名称 aggfunc=None, # 聚合函数 margins=False, # 总计行/列 dropna=True, # 是否删除缺失值 normalize=False # ) 1 c
-
mysql 行列动态转换的实现(列联表,交叉表)
(1)动态,适用于列不确定情况 create table table_name( id int primary key, col1 char(2), col2 char(2), col3 int ); insert into table_name values (1 ,'A1','B1',9), (2 ,'A2','B1',7), (3 ,'A3','B1',4), (4 ,'A4','B1',2), (5 ,'A1','B2',2), (6 ,'A2','B2',9), (7 ,'A3','B
-
Python利用prettytable库输出好看的表格
目录 1.前言 2.安装 3.示例 4.添加数据 5.表格输出格式 6.选择性输出 7.表格的样式 1.前言 最近在用 Python 写一个小工具,这个工具主要就是用来管理各种资源的信息,比如阿里云的 ECS 等信息,因为我工作的电脑使用的是 LINUX,所以就想着用 python 写一个命令行的管理工具,基本的功能就是同步阿里云的资源的信息到数据库,然后可以使用命令行查询. 因为信息是展现在命令行中的,众所周知,命令行展现复杂的文本看起来着实累人,于是就想着能像表格那样展示,那看起来就舒服多了
-
Python利用PyMuPDF实现PDF文件处理
目录 1.PyMuPDF简介 介绍 功能 2.安装 关于命名fitz的说明 3.使用方法 导入库,查看版本 打开文档 Document的方法和属性 获取元数据 获取目标大纲 页面(Page) PDF操作 1.PyMuPDF简介 介绍 在介绍PyMuPDF之前,先来了解一下MuPDF,从命名形式中就可以看出,PyMuPDF是MuPDF的Python接口形式. MuPDF MuPDF 是一个轻量级的 PDF.XPS和电子书查看器.MuPDF 由软件库.命令行工具和各种平台的查看器组成. MuPDF
-
Python利用openpyxl库遍历Sheet的实例
方法一,利用 sheet.iter_rows() 获取 Sheet1 表中的所有行,然后遍历 import openpyxl wb = openpyxl.load_workbook('example.xlsx') sheet = wb.get_sheet_by_name('Sheet1') for row in sheet.iter_rows(): for cell in row: print(cell.coordinate, cell.value) print('--- END OF ROW
-
Python利用sqlacodegen自动生成ORM实体类示例
本文实例讲述了Python利用sqlacodegen自动生成ORM实体类.分享给大家供大家参考,具体如下: 在前面一篇<Python流行ORM框架sqlalchemy安装与使用>我们是手动创建了一个名叫Infos.py的文件,然后定义了一个News类,把这个类作为和我们news数据表的映射. from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() from sqlalchemy impo
-
Python利用scapy实现ARP欺骗的方法
一.实验原理. 本次用代码实现的是ARP网关欺骗,通过发送错误的网关映射关系导致局域网内其他主机无法正常路由.使用scapy中scapy.all模块的ARP.sendp.Ether等函数完成包的封装与发送.一个简单的ARP响应报文发送: eth = Ether(src=src_mac, dst=dst_mac)#赋值src_mac时需要注意,参数为字符串类型 arp = ARP(hwsrc=src_mac, psrc=src_ip, hwdst=dst_mac, pdst=dst_ip, op=
-
python利用thrift服务读取hbase数据的方法
因工作需要用python通过hbase的thrift服务读取Hbase表数据,发现公司的测试环境还不支持,于是自己动手准备环境,在此我将在安装步骤尽可能描述清楚,旨在给第一次动手安装的朋友,此过程亲测成功! 安装过程如下: 1.首先确保hbase安装测试成功,再者确认下hbase的thrift服务是否启动,注意目前的Hbase(本文基于版本0.98.17)有两套thrift接口thrift和thrift2,本文使用thrift,启动命令:hbase thrift -p 9090 start,确保
-
python利用微信公众号实现报警功能
微信公众号共有三种,服务号.订阅号.企业号.它们在获取AccessToken上各有不同. 其中订阅号比较坑,它的AccessToken是需定时刷新,重复获取将导致上次获取的AccessToken失效. 而企业号就比较好,AccessToken有效期同样为7200秒,但有效期内重复获取返回相同结果. 为兼容这两种方式,因此按照订阅号的方式处理. 处理办法与接口文档中的要求相同: 为了保密appsecrect,第三方需要一个access_token获取和刷新的中控服务器. 而其他业务逻辑服务器所使
-
python利用requests库模拟post请求时json的使用教程
我们都见识过requests库在静态网页的爬取上展现的威力,我们日常见得最多的为get和post请求,他们最大的区别在于安全性上: 1.GET是通过URL方式请求,可以直接看到,明文传输. 2.POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的. 3.GET请求会保存在浏览器历史纪录中,还可能会保存在Web的日志中. 两者用法上也有显著差异(援引自知乎): 1.GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等).动态数据展示(列表