Python爬虫代理IP池实现方法
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来。不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而来?
刚自学爬虫的时候没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有个别代理能用。当然,如果你有更好的代理接口也可以自己接入。 免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然别人为什么还提供付费的(不过事实是很多代理商的付费IP也不稳定,也有很多是不能用)。所以采集回来的代理IP不能直接使用,可以写检测程序不断的去用这些代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方式,因为检测代理是个很慢的过程。
采集回来的代理如何存储?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫很好中间存储工具。
如何让爬虫更简单的使用这些代理?
答案肯定是做成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多好处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检测程序更加靠谱。
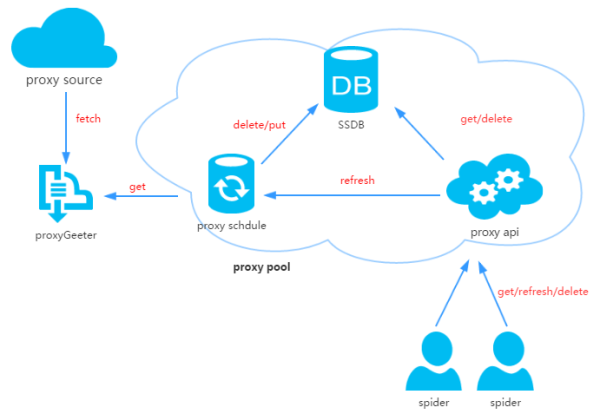
2、代理池设计
代理池由四部分组成:
ProxyGetter:
代理获取接口,目前有5个免费代理源,每调用一次就会抓取这个5个网站的最新代理放入DB,可自行添加额外的代理获取接口;
DB:
用于存放代理IP,现在暂时只支持SSDB。至于为什么选择SSDB,大家可以参考这篇文章,个人觉得SSDB是个不错的Redis替代方案,如果你没有用过SSDB,安装起来也很简单,可以参考这里;
Schedule:
计划任务用户定时去检测DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理放入DB;
ProxyApi:
代理池的外部接口,由于现在这么代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等接口,方便爬虫直接使用。
[HTML_REMOVED] 设计
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它非常适合于快速应用开发,也适合于作为胶水语言连接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api: api接口相关代码,目前api是由Flask实现,代码也非常简单。客户端请求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB: 数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩展其他类型数据库;
Manager: get/delete/refresh/get_all等接口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和账号的绑定等等;
ProxyGetter: 代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩展代理接口;
Schedule: 定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程方式;
Util: 存放一些公共的模块方法或函数,包含GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重写ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性计算。等等;
其他文件: 配置文件:Config.ini,数据库配置和代理获取接口配置,可以在GetFreeProxy中添加新的代理获取方法,并在Config.ini中注册即可使用;
4、安装
下载代码:
git clone git@github.com:jhao104/proxy_pool.git 或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
安装依赖:
pip install -r requirements.txt
启动:
需要分别启动定时任务和api 到Config.ini中配置你的SSDB 到Schedule目录下: >>>python ProxyRefreshSchedule.py 到Api目录下: >>>python ProxyApi.py
5、使用
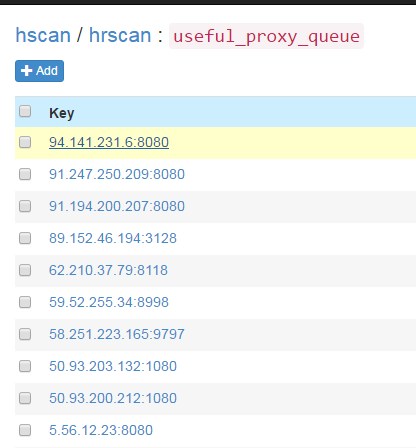
定时任务启动后,会通过代理获取方法fetch所有代理放入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大概一两分钟后,便可在SSDB中看到刷新出来的可用的代理:
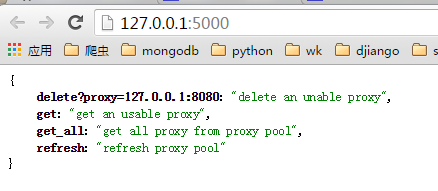
启动ProxyApi.py后即可在浏览器中使用接口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:

爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6、最后
时间仓促,功能和代码都比较简陋,以后有时间再改进。喜欢的在github上给个star。感谢!
相关推荐
-
Python开发中爬虫使用代理proxy抓取网页的方法示例
本文实例讲述了Python开发中爬虫使用代理proxy抓取网页的方法.分享给大家供大家参考,具体如下: 代理类型(proxy):透明代理 匿名代理 混淆代理和高匿代理. 这里写一些python爬虫使用代理的知识, 还有一个代理池的类. 方便大家应对工作中各种复杂的抓取问题. urllib 模块使用代理 urllib/urllib2使用代理比较麻烦, 需要先构建一个ProxyHandler的类, 随后将该类用于构建网页打开的opener的类,再在request中安装该opener. 代理格式是"h
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文实例讲述了Python爬虫实现网页信息抓取功能.分享给大家供大家参考,具体如下: 首先实现关于网页解析.读取等操作我们要用到以下几个模块 import urllib import urllib2 import re 我们可以尝试一下用readline方法读某个网站,比如说百度 def test(): f=urllib.urlopen('http://www.baidu.com') while True: firstLine=f.readline() print firstLine 下面我们说
-

零基础写python爬虫之使用urllib2组件抓取网页内容
版本号:Python2.7.5,Python3改动较大,各位另寻教程. 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源. 在Python中,我们使用urllib2这个组件来抓取网页. urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件. 它以urlopen函数的形式提供了一个非常简单的接口. 最简
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
Python使用代理抓取网站图片(多线程)
一.功能说明:1. 多线程方式抓取代理服务器,并多线程验证代理服务器ps 代理服务器是从http://www.cnproxy.com/ (测试只选择了8个页面)抓取2. 抓取一个网站的图片地址,多线程随机取一个代理服务器下载图片二.实现代码 复制代码 代码如下: #!/usr/bin/env python#coding:utf-8 import urllib2import reimport threadingimport timeimport random rawProxyList = []ch
-
通过Python爬虫代理IP快速增加博客阅读量
写在前面 题目所说的并不是目的,主要是为了更详细的了解网站的反爬机制,如果真的想要提高博客的阅读量,优质的内容必不可少. 了解网站的反爬机制 一般网站从以下几个方面反爬虫: 1. 通过Headers反爬虫 从用户请求的Headers反爬虫是最常见的反爬虫策略.很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer). 如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agen
-
尝试使用Python多线程抓取代理服务器IP地址的示例
这里以抓取 http://www.proxy.com.ru 站点的代理服务器为例,代码如下: #!/usr/bin/env python #coding:utf-8 import urllib2 import re import threading import time import MySQLdb rawProxyList = [] checkedProxyList = [] #抓取代理网站 targets = [] for i in xrange(1,42): target = r"htt
-
Python实现的异步代理爬虫及代理池
使用python asyncio实现了一个异步代理池,根据规则爬取代理网站上的免费代理,在验证其有效后存入redis中,定期扩展代理的数量并检验池中代理的有效性,移除失效的代理.同时用aiohttp实现了一个server,其他的程序可以通过访问相应的url来从代理池中获取代理. 源码 Github 环境 Python 3.5+ Redis PhantomJS(可选) Supervisord(可选) 因为代码中大量使用了asyncio的async和await语法,它们是在Python3.5中才提供
-
Python代理抓取并验证使用多线程实现
没有使用队列,也没有线程池还在学习只是多线程 复制代码 代码如下: #coding:utf8 import urllib2,sys,re import threading,os import time,datetime ''''' 这里没有使用队列 只是采用多线程分发对代理量不大的网页还行但是几百几千性能就很差了 ''' def get_proxy_page(url): '''''解析代理页面 获取所有代理地址''' proxy_list = [] p = re.compile(r'''''<d
-
python抓取网页图片示例(python爬虫)
复制代码 代码如下: #-*- encoding: utf-8 -*-'''Created on 2014-4-24 @author: Leon Wong''' import urllib2import urllibimport reimport timeimport osimport uuid #获取二级页面urldef findUrl2(html): re1 = r'http://tuchong.com/\d+/\d+/|http://\w+(?<!photos).tuchong.co