MySQL分区之子分区详解
目录
- 介绍
- 一、创建子分区
- 1.不定义每个子分区
- 2.定义每个子分区
- 3.测试数据
- 二、分区管理
- 1.合并分区
- 2.拆分分区
- 3.删除分区
- 三、错误的子分区创建
- 四、移除表的分区
- 总结
介绍
子分区其实是对每个分区表的每个分区进行再次分隔,目前只有RANGE和LIST分区的表可以再进行子分区,子分区只能是HASH或者KEY分区。子分区可以将原本的数据进行再次的分区划分。
一、创建子分区
子分区由两种创建方法,一种是不定义每个子分区子分区的名字和路径由分区决定,二是定义每个子分区的分区名和各自的路径
1.不定义每个子分区
CREATE TABLE tb_sub (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='tb_sub';

2.定义每个子分区
定义子分区可以为每个子分区定义具体的分区名和分区路径
CREATE TABLE tb_sub_ev (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);

3.测试数据
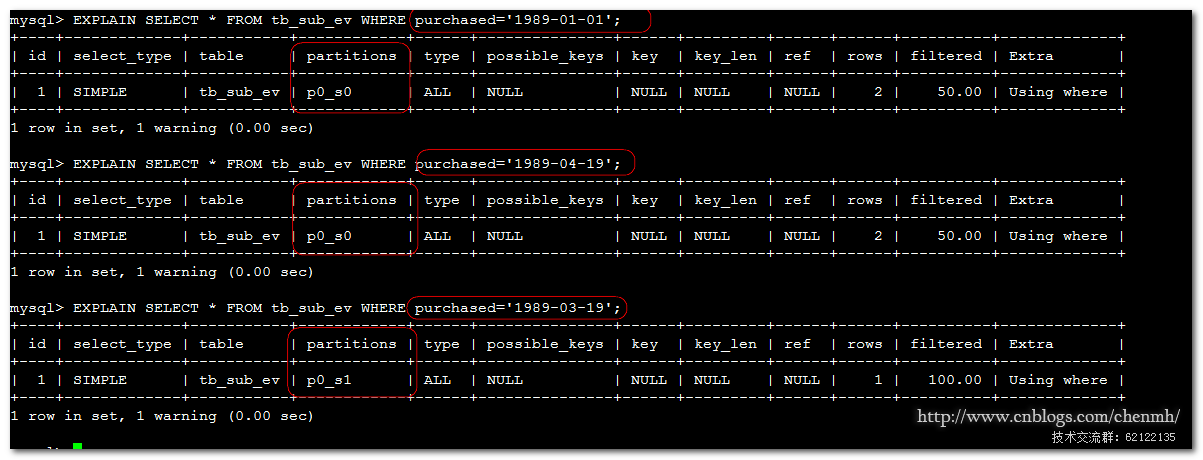
INSERT INTO tb_sub_ev() VALUES(1,'1989-01-01'),(2,'1989-03-19'),(3,'1989-04-19');
当往里面插入三条记录时,其中‘1989-01-01’和‘1989-04-19’存储在p0_s0分区中,‘1989-03-19’存储在p0_s1当中

二、分区管理
分区管理和RANGE、LIST的分区管理是一样的
1.合并分区
将p0,p1两个分区合并
ALTER TABLE tb_sub_ev REORGANIZE PARTITION p0,p1 INTO (
PARTITION m1 VALUES LESS THAN (2000)
( SUBPARTITION n0,
SUBPARTITION n1
)
);

注意:合并分区的子分区也必须是两个,这点需要理解,因为必须和创建分区时每个分区只有两个子分区保持一致,合并分区不会造成数据的丢失。
2.拆分分区
ALTER TABLE tb_sub_ev REORGANIZE PARTITION m1 INTO (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
)
);
同样,拆分分区也必须保证每个分区是两个子分区。
3.删除分区
ALTER TABLE tb_sub_ev DROP PARTITION P0;
注意:由于分区是RANGE和LIST分区,所以删除分区也是同RANGE和LIST分区一样,这里只能对每个分区进行删除,不能针对每个子分区进行删除操作,删除分区后子分区连同数据一并被删除。
三、错误的子分区创建
1.要不不定义各个子分区要不就每个都需要定义
CREATE TABLE tb_sub_ev_nex (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
这里由于分区p1没有定义子分区,所以创建分区失败
四、移除表的分区
ALTER TABLE tablename REMOVE PARTITIONING ;
注意:使用remove移除分区是仅仅移除分区的定义,并不会删除数据和drop PARTITION不一样,后者会连同数据一起删除
分区系列文章:
RANGE分区:https://www.jb51.net/article/244269.htm
COLUMN分区:https://www.jb51.net/article/96515.htm
LIST分区:https://www.jb51.net/article/244256.htm
HASH分区:https://www.jb51.net/article/244277.htm
KEY分区:https://www.jb51.net/article/244282.htm
子分区:https://www.jb51.net/article/244294.htm
指定各分区路径:https://www.jb51.net/article/244296.htm
分区索引以及分区介绍总结:https://www.jb51.net/article/244300.htm
总结
子分区的好处是可以对分区的数据进行再分,这样数据就更加的分散,同时还可以对每个子分区定义各自的存储路径,这部分内容在指定各分区路径的下一篇文章中单独进行讲解。
到此这篇关于MySQL分区之子分区的文章就介绍到这了,更多相关MySQL 子分区内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
创建mysql表分区的方法
表分区是最近才知道的哦 ,以前自己做都是分表来实现上亿级别的数据了,下面我来给大家介绍一下mysql表分区创建与使用吧,希望对各位同学会有所帮助.表分区的测试使用,主要内容来自于其他博客文章以及mysql5.1的参考手册mysql测试版本:mysql5.5.28mysql物理存储文件(有mysql配置的datadir决定存储路径)格式简介数据库engine为MYISAM frm表结构文件,myd表数据文件,myi表索引文件.INNODB engine对应的表物理存储文件innodb的数据库的物理
-
mysql使用教程之分区表的使用方法(删除分区表)
MySQL使用分区表的好处: 1,可以把一些归类的数据放在一个分区中,可以减少服务器检查数据的数量加快查询.2,方便维护,通过删除分区来删除老的数据.3,分区数据可以被分布到不同的物理位置,可以做分布式有效利用多个硬盘驱动器. MySQL可以建立四种分区类型的分区: RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区. LIST 分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择. www.jb51.net HASH分区:基于用户
-
mysql的分区技术详细介绍
一.概述 当 MySQL的总记录数超过了100万后,会出现性能的大幅度下降吗?答案是肯定的,但是,性能下降>的比率不一而同,要看系统的架构.应用程序.还有>包括索引.服务器硬件等多种因素而定.当有网友问我这个问题的时候,我最常见的回答>就是:分表,可以根据id区间或者时间先后顺序等多种规则来分表.分表很容易,然而由此所带来的应用程序甚至是架构方面的改动工作却不>容小觑,还包括将来的扩展性等. 在以前,一种解决方案就是使用 MERGE 类型,这是一个非常方便的做饭.架构和程序基本上不
-
MySQL分区表的正确使用方法
MySQL分区表概述 我们经常遇到一张表里面保存了上亿甚至过十亿的记录,这些表里面保存了大量的历史记录. 对于这些历史数据的清理是一个非常头疼事情,由于所有的数据都一个普通的表里.所以只能是启用一个或多个带where条件的delete语句去删除(一般where条件是时间). 这对数据库的造成了很大压力.即使我们把这些删除了,但底层的数据文件并没有变小.面对这类问题,最有效的方法就是在使用分区表.最常见的分区方法就是按照时间进行分区. 分区一个最大的优点就是可以非常高效的进行历史数据的清理. 1.
-
MySql数据分区操作之新增分区操作
如果想在已经建好的表上进行分区,如果使用alter添加分区的话,mysql会提示错误: 复制代码 代码如下: ERROR 1505 <HY000> Partition management on a not partitioned table is not possible 正确的方法是新建一个具有分区的表,结构一致,然后用insert into 分区表 select * from 原始表; 测试创建分区表文件 复制代码 代码如下: CREATE TABLE tr (id INT, name
-
MySQL的表分区详解
一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了.如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区.当然也可根据其他的条件分区. 二.为什么要对表进行分区为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率.分区的一些优点包括: 1).与单个磁盘或文件系统分区相比,可以存储更多的数据. 2).对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的
-

MySQL分区之子分区详解
目录 介绍 一.创建子分区 1.不定义每个子分区 2.定义每个子分区 3.测试数据 二.分区管理 1.合并分区 2.拆分分区 3.删除分区 三.错误的子分区创建 四.移除表的分区 总结 介绍 子分区其实是对每个分区表的每个分区进行再次分隔,目前只有RANGE和LIST分区的表可以再进行子分区,子分区只能是HASH或者KEY分区.子分区可以将原本的数据进行再次的分区划分. 一.创建子分区 子分区由两种创建方法,一种是不定义每个子分区子分区的名字和路径由分区决定,二是定义每个子分区的分区名和各自的路
-
MySQL数据库之union,limit和子查询详解
目录 1.where中的子查询 2.from子句后的子查询 3.union 4.limit查询 5.分页 1.where中的子查询 示例数据参见此文章 案例:查询比最低工资高的员工姓名和薪资 子查询,先查询子查询括号里的,再向上级进行查询 mysql> select ename,sal from emp where sal -> > -> (select min(sal) from emp); +--------+---------+ | ename | sal | +------
-
MySQL 去除重复数据实例详解
MySQL 去除重复数据实例详解 有两个意义上的重复记录,一是完全重复的记录,也即所有字段均都重复,二是部分字段重复的记录.对于第一种重复,比较容易解决,只需在查询语句中使用distinct关键字去重,几乎所有数据库系统都支持distinct操作.发生这种重复的原因主要是表设计不周,通过给表增加主键或唯一索引列即可避免. select distinct * from t; 对于第二类重复问题,通常要求查询出重复记录中的任一条记录.假设表t有id,name,address三个字段,id是主键,有重
-
CentOS 7 安装并配置 MySQL 5.6的步骤详解
Linux使用MySQL Yum存储库上安装MySQL 5.6,适用于Oracle Linux,Red Hat Enterprise Linux和CentOS系统. 一.全新安装MySQL 1.添加MySQL Yum存储库 将MySQL Yum存储库添加到系统的存储库列表中.这是一次性操作,可以通过安装MySQL提供的RPM来执行.跟着这些步骤: 1.1.到MySQL官网下载MySQL Yum存储库(https://dev.mysql.com/downloads/repo/yum/). 1.2.
-
Mysql调优Explain工具详解及实战演练(推荐)
Mysql调优Explain工具详解以及实战演练 Explain工具介绍Explain分析示例explain 两个变种explain中的列 索引最佳实战索引使用总结: Mysql安装文档参考 Explain工具介绍 使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈 在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是 执行这条SQL 注意:如果 from 中包含子查询,仍会执行该子
-
MySQL的Query Cache图文详解
目录 一.原理概述 二.Query Cache系统变量 1. have_query_cache 2. query_cache_limit 3. query_cache_min_res_unit 4. query_cache_size 5. query_cache_type 6. query_cache_wlock_invalidate 三.Query Cache状态变量 1. Qcache_free_blocks 2. Qcache_free_memory 3. Qcache_hits 4. Q
-
mysql语法之DQL操作详解
目录 简单查询 运算符查询 排序查询 聚合查询 分组查询 分页查询 一张表查询结果插入到另一张表 SQL语句分析 DQL小练习1 DQL小练习2 正则表达式 总结 DQL(Data Query Language),数据查询语言,主要是用来查询数据的,这也是SQL中最重要的部分! 简单查询 #DQL操作之基本查询 #创建数据库 CREATE DATABASE IF NOT EXISTS mydb2; #使用数据库 USE mydb2; #创建表 CREATE TABLE IF NOT EXISTS
-
MySQL六种约束的示例详解(全网最全)
目录 一.概述 二.约束演示 三.外键约束 1. 什么是外键约束 2. 不使用外键有什么影响 3. 添加外键的语法 4. 删除/更新行为 5. 演示删除/更新行为 四.主键id到底用自增好还是uuid好 五.实际开发尽量少用外键 一.概述 概念: 约束是作用于表中字段上的规则,用于限制存储在表中的数据. 目的: 保证数据库中数据的正确.有效性和完整性. 分类: 注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束. 二.约束演示 上面我们介绍了数据库中常见的约束,以及约束涉及到的关
-
MySql常用数据类型与操作详解
目录 常用数据类型 数据库基本操作 约束类型 常用数据类型 1.int:整形 2.double(m,d) decimal(m,d):浮点数类型 (m指定长度,d表示小数点位数) 3.varchar(size):字符串类型 4.timestamp:日期类型 数据库基本操作 不管执行什么语句,都要在语句的最后加上:(分号). 1.创建数据库 create database 数据库名: 2.显示当前数据库 show databases; 3.删除数据库 drop database 数据库名; 4.使用
-
MySQL中数据视图操作详解
目录 1.视图概述 1.1创建视图 1.2视图的查询 2.操作视图 2.1通过视图操作数据 2.2修改视图定义 2.3删除视图 1.视图概述 视图是从一个或多个表(或视图)导出的表.视图与表(有时为与视图区别,也称表为基本表)不同,视图是一个虚表,即视图所对应的数据不进行实际存储,数据库中只存储视图的定义,对视图的数据进行操作时,系统根据视图的定义去操作与视图相关联的基本表. 视图一经定义,就可以像表一样被查询.修改.删除和更新.使用视图有下列优点: 1.为用户集中数据,简化用户的数据查询和处理