pytorch 如何使用float64训练
pytorch默认使用单精度float32训练模型,
原因在于:
使用float16训练模型,模型效果会有损失,而使用double(float64)会有2倍的内存压力,且不会带来太多的精度提升。
本人,最近遇到需要使用double数据类型训练模型的情况,具体实现需要把模型的权重参数数据类型和输入数据类型全部设置为torch.float64即可。
可使用torch的一个函数,轻松地把模型参数转化为float64
torch.set_default_dtype(torch.float64)
输入类型可使用
tensor.type(torch.float64)
补充:float32和float64的本质区别
首先我们需要知道何为bits和bytes?
bits:名为位数bytes:为字节简单的数就是MB和G的关系!
那么8bits=1bytes,下面是各个单位的相互转化!
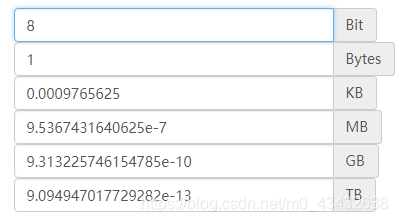
那么float32和float64有什么区别呢?
数位的区别一个在内存中占分别32和64个bits,也就是4bytes或8bytes数位越高浮点数的精度越高它会影响深度学习计算效率?
float64占用的内存是float32的两倍,是float16的4倍;
比如对于CIFAR10数据集,如果采用float64来表示,需要60000*32*32*3*8/1024**3=1.4G,光把数据集调入内存就需要1.4G;
如果采用float32,只需要0.7G,如果采用float16,只需要0.35G左右;
占用内存的多少,会对系统运行效率有严重影响;(因此数据集文件都是采用uint8来存在数据,保持文件最小)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch加载预训练模型与自己模型不匹配的解决方案
pytorch中如果自己搭建网络并且加载别人的与训练模型的话,如果模型和参数不严格匹配,就可能会出问题,接下来记录一下我的解决方法. 两个有序字典找不同 模型的参数和pth文件的参数都是有序字典(OrderedDict),把字典中的键转为列表就可以在for循环里迭代找不同了. model = ResNet18(1) model_dict1 = torch.load('resnet18.pth') model_dict2 = model.state_dict() model_list1 = lis
-

pytorch训练神经网络爆内存的解决方案
训练的时候内存一直在增加,最后内存爆满,被迫中断. 后来换了一个电脑发现还是这样,考虑是代码的问题. 检查才发现我的代码两次存了loss,只有一个地方写的是loss.item().问题就在loss,因为loss是variable类型. 要写成loss_train = loss_train + loss.item(),不能直接写loss_train = loss_train + loss.否则就会发现随着epoch的增加,占的内存也在一点一点增加. 算是一个小坑吧,希望大家还是要仔细. 补充:py
-
解决Pytorch半精度浮点型网络训练的问题
用Pytorch1.0进行半精度浮点型网络训练需要注意下问题: 1.网络要在GPU上跑,模型和输入样本数据都要cuda().half() 2.模型参数转换为half型,不必索引到每层,直接model.cuda().half()即可 3.对于半精度模型,优化算法,Adam我在使用过程中,在某些参数的梯度为0的时候,更新权重后,梯度为零的权重变成了NAN,这非常奇怪,但是Adam算法对于全精度数据类型却没有这个问题. 另外,SGD算法对于半精度和全精度计算均没有问题. 还有一个问题是不知道是不是网络
-
Pytorch训练网络过程中loss突然变为0的解决方案
问题 // loss 突然变成0 python train.py -b=8 INFO: Using device cpu INFO: Network: 1 input channels 7 output channels (classes) Bilinear upscaling INFO: Creating dataset with 868 examples INFO: Starting training: Epochs: 5 Batch size: 8 Learning rate: 0.001
-
Pytorch训练模型得到输出后计算F1-Score 和AUC的操作
1.计算F1-Score 对于二分类来说,假设batch size 大小为64的话,那么模型一个batch的输出应该是torch.size([64,2]),所以首先做的是得到这个二维矩阵的每一行的最大索引值,然后添加到一个列表中,同时把标签也添加到一个列表中,最后使用sklearn中计算F1的工具包进行计算,代码如下 import numpy as np import sklearn.metrics import f1_score prob_all = [] lable_all = [] for
-
PyTorch梯度裁剪避免训练loss nan的操作
近来在训练检测网络的时候会出现loss为nan的情况,需要中断重新训练,会很麻烦.因而选择使用PyTorch提供的梯度裁剪库来对模型训练过程中的梯度范围进行限制,修改之后,不再出现loss为nan的情况. PyTorch中采用torch.nn.utils.clip_grad_norm_来实现梯度裁剪,链接如下: https://pytorch.org/docs/stable/_modules/torch/nn/utils/clip_grad.html 训练代码使用示例如下: from torch
-
pytorch 如何使用float64训练
pytorch默认使用单精度float32训练模型, 原因在于: 使用float16训练模型,模型效果会有损失,而使用double(float64)会有2倍的内存压力,且不会带来太多的精度提升. 本人,最近遇到需要使用double数据类型训练模型的情况,具体实现需要把模型的权重参数数据类型和输入数据类型全部设置为torch.float64即可. 可使用torch的一个函数,轻松地把模型参数转化为float64 torch.set_default_dtype(torch.float64) 输入类型
-
在pytorch中查看可训练参数的例子
pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的. pytorch中model.parameters()函数定义如下: def parameters(self): r"""Returns an iterator over module parameters. This is typically passed to an optimizer. Yields: Parameter: module paramete
-
pytorch使用指定GPU训练的实例
本文适合多GPU的机器,并且每个用户需要单独使用GPU训练. 虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存.这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一直报out of memory错误. 解决方案如下: 指定环境变量,屏蔽第0块gpu CUDA_VISIBLE_DEVICES = 1 main.py 这句话表示只有第1块
-
pytorch 使用加载训练好的模型做inference
前提: 模型参数和结构是分别保存的 1. 构建模型(# load model graph) model = MODEL() 2.加载模型参数(# load model state_dict) model.load_state_dict ( { k.replace('module.',''):v for k,v in torch.load(config.model_path, map_location=config.device).items() } ) model = self.model.to
-
详解pytorch的多GPU训练的两种方式
目录 方法一:torch.nn.DataParallel 1. 原理 2. 常用的配套代码如下 3. 优缺点 方法二:torch.distributed 1. 代码说明 方法一:torch.nn.DataParallel 1. 原理 如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min. 这里的作业就是pytorch中要处理的data. 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完.最后他再花3min把作业收起来,一共需要66min. 这个
-
Pytorch 使用Google Colab训练神经网络深度学习
目录 学习前言 什么是Google Colab 相关链接 利用Colab进行训练 一.数据集与预训练权重的上传 1.数据集的上传 2.预训练权重的上传 二.打开Colab并配置环境 1.笔记本的创建 2.环境的简单配置 3.深度学习库的下载 4.数据集的复制与解压 5.保存路径设置 三.开始训练 1.标注文件的处理 2.训练文件的处理 3.开始训练 断线怎么办? 1.防掉线措施 2.完了还是掉线呀? 总结 学习前言 Colab是谷歌提供的一个云学习平台,Very Nice,最近卡不够用了决定去白
-
详解如何使用Pytorch进行多卡训练
目录 1.DP 2.DDP 2.1Pytorch分布式基础 2.2Pytorch分布式训练DEMO 当一块GPU不够用时,我们就需要使用多卡进行并行训练.其中多卡并行可分为数据并行和模型并行.具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录.对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(DistributedDataParallel, DDP). 在多卡训练的实现上,DP与DDP的思路是相似的: 1.每张卡都复制
-
pytorch锁死在dataloader(训练时卡死)
1.问题描述 2.解决方案 (1)Dataloader里面不用cv2.imread进行读取图片,用cv2.imread还会带来一系列的不方便,比如不能结合torchvision进行数据增强,所以最好用PIL 里面的Image.open来读图片.(并不适用本例) (2)将DataLoader 里面的参变量num_workers设置为0,但会导致数据的读取很慢,拖慢整个模型的训练.(并不适用本例) (3)如果用了cv2.imread,不想改代码的,那就加两条语句,来关闭Opencv的多线程:cv2.
-
pytorch 6 batch_train 批训练操作
看代码吧~ import torch import torch.utils.data as Data torch.manual_seed(1) # reproducible # BATCH_SIZE = 5 BATCH_SIZE = 8 # 每次使用8个数据同时传入网路 x = torch.linspace(1, 10, 10) # this is x data (torch tensor) y = torch.linspace(10, 1, 10) # this is y data (torc