Python对口红进行数据分析来选定情人节礼物
目录
- 前言:
- 准备工作
- 驱动安装
- 模块使用与介绍
- 流程解析
- 完整代码
- 效果展示
- 结尾
前言:
情人节、三八女神节、520、七夕节、圣诞节、元旦、生日、新年、各种纪念日……这些节日,对于每一个有女朋友的男同胞们来说都存在一个困惑的问题:送女朋友什么礼物好?

其实送礼物这件事,说难也不难,但也绝不是一件简单的事儿hhh~
送对了感情升温,送错了让你恢复单身!
但只要在挑选礼物的时候记得以下这几点,想要踩雷都很难了。

1.符合对方的审美,平时多留意一下女朋友喜欢什么东西。
2.颜值即正义,女孩子都是颜值动物,像我自己平时挑个拖鞋选个水杯,都要高颜值的,可爱的,高级感的…
3.礼物要有仪式感,比如包装得很精美的花、自己新手做的礼盒、好看又实用刚好又是对方需要的东西。
4.在能力范围内送合适的礼物,礼物不一定要贵,有意义有心意最重要。
接下来就可以拿着这一份挑口红的功课去给女朋友挑礼物啦,保证不会踩雷,送给女孩子绝对不会错~

准备工作
驱动安装
实现案例之前,我们要先安装一个谷歌驱动,因为我们是使用selenium 操控谷歌驱动,然后操控浏览器实现自动操作的,模拟人的行为去操作浏览器。
以谷歌浏览器为例,打开浏览器看下我们自己的版本,然后下载跟自己浏览器版本一样或者最相近的版本,下载后解压一下,把解压好的插件放到我们的python环境里面,或者和代码放到一起也可以。
模块使用与介绍
seleniumpip install selenium ,直接输入selenium的话是默认安装最新的,selenium后面加上版本号就是安装对应的的版本;csv内置模块,不需要安装,把数据保存到Excel表格用的;time内置模块,不需要安装,时间模块,主要用于延时等待;
流程解析
我们访问一个网站,要输入一个网址,所以代码也是这么写的。
首先导入模块
from selenium import webdriver
文件名或者包名不要命名为selenium,会导致无法导入。 webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器。
实例化浏览器对象 ,我这里用的是谷歌,建议大家用谷歌,方便一点。
driver = webdriver.Chrome()
我们用get访问一个网址,自动打开网址。
driver.get('https://www.jd.com/')
运行一下
打开网址后,以买口红为例。
我们首先要通过你想购买的商品关键字来搜索得到商品信息,用搜索结果去获取信息。
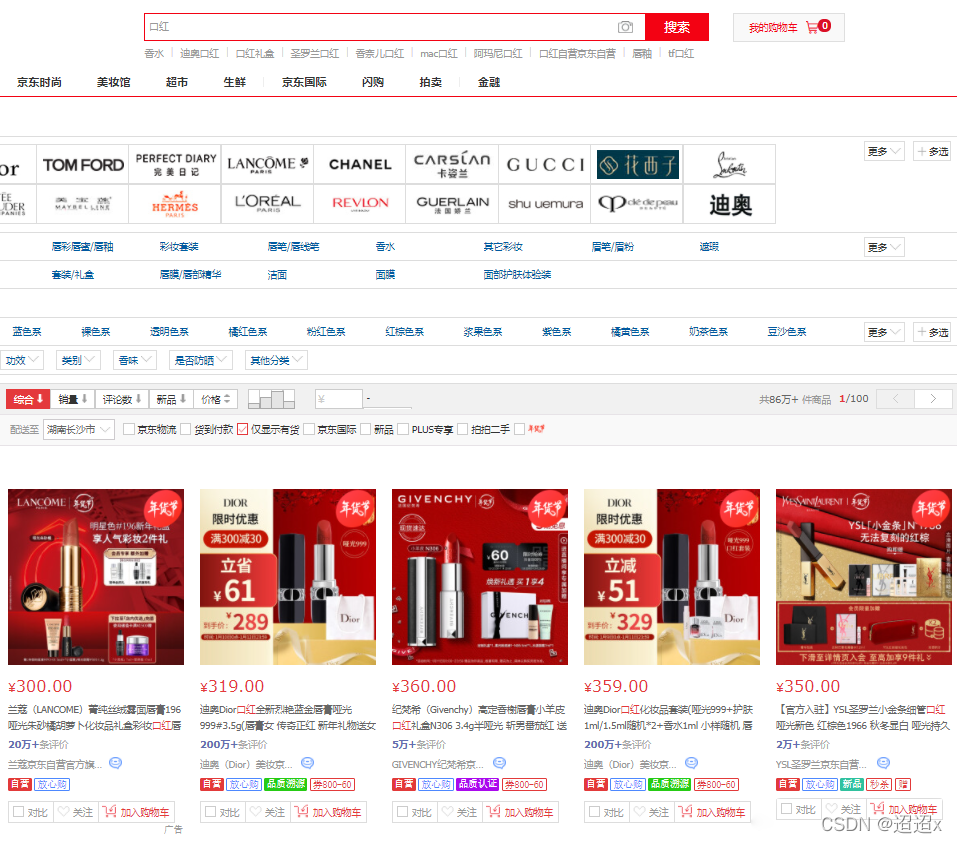
那我们也要写一个输入,空白处点击右键,选择检查。选择element 元素面板

鼠标点击左边的箭头按钮,去点击搜索框,它就会直接定位到搜索标签。在标签上点击右键,选择copy,选择copy selector 。如果你是xpath ,就copy它的xpath 。然后把我们想要搜索的内容写出来
driver.find_element_by_css_selector('#key').send_keys('口红')
再运行的时候,它就会自动打开浏览器进入目标网址搜索口红。
同样的方法,找到搜索按钮进行点击。
driver.find_element_by_css_selector('.button').click()
再运行就会自动点击搜索了,页面搜索出来了,那么咱们正常浏览网页是要下拉网页对吧,咱们让它自动下拉就好了。 先导入time模块
import time
执行页面滚动的操作
def drop_down():
"""执行页面滚动的操作""" # javascript
for x in range(1, 12, 2): # for循环下拉次数,取1 3 5 7 9 11, 在你不断的下拉过程中, 页面高度也会变的;
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 执行我们JS代码
循环写好了,然后调用一下。
drop_down()
我们再给它来个延时
driver.implicitly_wait(10)
这是一个隐式等待,等待网页延时,网不好的话加载很慢。
隐式等待不是必须等十秒,在十秒内你的网络加载好后,它随时会加载,十秒后没加载出来的话才会强行加载。
还有另外一种死等的,你写的几秒就等几秒,相对没有那么人性化。
time.sleep(10)
加载完数据后我们需要去找商品数据来源
价格/标题/评价/封面/店铺等等
还是鼠标右键点击检查,在element ,点击小箭头去点击你想查看的数据。
可以看到都在li标签里面 获取所有的 li 标签内容,还是一样的,直接copy 。 在左下角就有了 这里表示的是取的第一个,但是我们是要获取所有的标签,所以左边框框里 li 后面的可以删掉不要。 不要的话,可以看到这里是60个商品数据,一页是60个。 所以我们把剩下的复制过来, 用lis接收一下 。
lis = driver.find_elements_by_css_selector('#J_goodsList ul li')
因为我们是获取所有的标签数据,所以比之前多了一个s

打印一下
print(lis)
通过lis返回数据 列表 [] 列表里面的元素 <> 对象

遍历一下,把所有的元素拿出来。
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品标题 获取标签文本数据
price = li.find_element_by_css_selector('.p-price strong i').text # 价格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 评论量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店铺名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品详情页
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推导式 ','.join 以逗号把列表中的元素拼接成一个字符串数据
dit = {
'商品标题': title,
'商品价格': price,
'评论量': commit,
'店铺名字': shop_name,
'标签': icon,
'商品详情页': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
搜索功能
key_world = input('请输入你想要获取商品数据: ')
要获取的数据 ,获取到后保存CSV
f = open(f'京东{key_world}商品数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品标题',
'商品价格',
'评论量',
'店铺名字',
'标签',
'商品详情页',
])
csv_writer.writeheader()
然后再写一个自动翻页
for page in range(1, 11):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1)
drop_down()
get_shop_info() # 下载数据
driver.find_element_by_css_selector('.pn-next').click() # 点击下一页
完整代码
from selenium import webdriver
import time
import csv
def drop_down():
"""执行页面滚动的操作"""
for x in range(1, 12, 2):
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 执行JS代码
key_world = input('请输入你想要获取商品数据: ')
f = open(f'京东{key_world}商品数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品标题',
'商品价格',
'评论量',
'店铺名字',
'标签',
'商品详情页',
])
csv_writer.writeheader()
# 实例化一个浏览器对象
driver = webdriver.Chrome()
driver.get('https://www.jd.com/') # 访问一个网址 打开浏览器 打开网址
# 通过css语法在element(元素面板)里面查找 #key 某个标签数据 输入一个关键词 口红
driver.find_element_by_css_selector('#key').send_keys(key_world) # 找到输入框标签
driver.find_element_by_css_selector('.button').click() # 找到搜索按钮 进行点击
# time.sleep(10) # 等待
# driver.implicitly_wait(10) # 隐式等待
def get_shop_info():
# 第一步 获取所有的li标签内容
driver.implicitly_wait(10)
lis = driver.find_elements_by_css_selector('#J_goodsList ul li') # 获取多个标签
# 返回数据 列表 [] 列表里面的元素 <> 对象
# print(len(lis))
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品标题 获取标签文本数据
price = li.find_element_by_css_selector('.p-price strong i').text # 价格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 评论量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店铺名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品详情页
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推导式 ','.join 以逗号把列表中的元素拼接成一个字符串数据
dit = {
'商品标题': title,
'商品价格': price,
'评论量': commit,
'店铺名字': shop_name,
'标签': icon,
'商品详情页': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
# print(href)
for page in range(1, 11):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1)
drop_down()
get_shop_info() # 下载数据
driver.find_element_by_css_selector('.pn-next').click() # 点击下一页
driver.quit() # 关闭浏览器
效果展示


结尾
以上就是本文的全部内容了,大家喜欢的记得点点赞!

到此这篇关于Python对口红进行数据分析来选定情人节礼物的文章就介绍到这了,更多相关Python数据分析口红内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据分析近年比特币价格涨幅趋势分布
目录 使用技术点: 使用工具: 导入第三方库 大家好,我是辣条. 曾经有一个真挚的机会,摆在我面前,但是我没有珍惜,等到失去的时候才后悔莫及,尘世间最痛苦的事莫过于此,如果老天可以再给我一个再来一次机会的话,我会买下那个比特币,哪怕付出所有零花钱,如果非要在这个机会加上一个期限的话,我希望是十年前. 看着这份台词是不是很眼熟,我稍稍改了一下,曾经差一点点点就购买比特币了,肠子都悔青了现在,今天对比特币做一个简单的数据分析. # 安装对应的第三方库 !pip install pandas !pip
-
深入浅析Python数据分析的过程记录
目录 一.需求介绍 二.以第1.个为例进行数据分析 1.获取一天的数据 2.开始一天的数据的分析 3.循环日期进行多天的数据分析: 4.将数据写入Excel表格中 三.完整的代码展示: 总结 一.需求介绍 该需求主要是分析某一种数据的历史数据. 客户的需求是根据该数据的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票,对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5:对于2.,如果相等的数字是:1-5,那就买1-5,如果
-
基于Python实现股票数据分析的可视化
目录 一.简介 二.代码 1.主文件 2.数据库使用文件 3.ui设计模块 4.数据处理模块 三.数据样例的展示 四.效果展示 一.简介 我们知道在购买股票的时候,可以使用历史数据来对当前的股票的走势进行预测,这就需要对股票的数据进行获取并且进行一定的分析,当然了,人们是比较喜欢图形化的界面的,因此,我们在这里采用一种可视化的方法来实现股票数据的分析. 二.代码 1.主文件 from work1 import get_data from work1 import read_data from w
-
python数据分析Numpy库的常用操作
numpy库的引入: import numpy as np 1.numpy对象基础属性的查询 lst = [[1, 2, 3], [4, 5, 6]] def numpy_type(): print(type(lst)) data = np.array(lst, dtype=np.float64) # array将数组转为numpy的数组 # bool,int,int8,int16,int32,int64,int128,uint8,uint32, # uint64,uint128,float16
-
Python数据分析之Matplotlib的常用操作总结
目录 使用准备 1.简单的绘制图像 2.视图面板的常用操作 3.样式及各类常用修饰属性 4.legend图例的使用 5.添加文字等描述 6.不同类型图像的绘制 总结 使用准备 使用matplotlib需引入: import matplotlib.pyplot as plt 通常2会配合着numpy使用,numpy引入: import numpy as np 1.简单的绘制图像 def matplotlib_draw(): # 从-1到1生成100个点,包括最后一个点,默认为不包括最后一个点 x
-
详解Python对某地区二手房房价数据分析
目录 房价数据分析 数据简单清洗 各区均价分析 全市二手房装修程度分析 各区二手房数量所占比比例 热门户型均价分析 总结 房价数据分析 数据简单清洗 data.csv 数据显示 # 导入模块 import pandas as pd # 导入数据统计模块 import matplotlib # 导入图表模块 import matplotlib.pyplot as plt # 导入绘图模块 # 避免中文乱码 matplotlib.rcParams['font.sans-serif'] = ['Sim
-
python数据分析之文件读取详解
目录 前言: 一·Numpy库中操作文件 二·Pandas库中操作文件 三·补充 总结 前言: 如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作csv文件 import numpy as np a=np.random.randint(0,10,size=(3,4)) np.savetext("score.csv",a,deliminte
-
python数据分析实战指南之异常值处理
目录 异常值 1.异常值定义 2.异常值处理方式 2.1 均方差 2.2 箱形图 3.实战 3.1 加载数据 3.2 检测异常值数据 3.3 显示异常值的索引位置 总结 异常值 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 常用的异常值分析方法为3σ原则.箱型图分析.机器学习算法检测,一般情况下对异常值的处理都是删除和修正填补,即默认为异常值对整个项目的作用不大,只有当我们的目的是要求准确找出离群点,并对离群点进行分析时有必要用到机器学
-
Python数据分析基础之文件的读取
目录 一·Numpy库中操作文件 1.操作csv文件 2.在pycharm中操作csv文件 3.其他情况(.npy类型文件) 二·Pandas库中操作文件 1.操作csv文件 2.从剪贴板上复制数据 3.读取excel或xlsx文件 三·补充 1.常用 2.pandas中读取文件的函数 总结 前言:如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作
-
Python对口红进行数据分析来选定情人节礼物
目录 前言: 准备工作 驱动安装 模块使用与介绍 流程解析 完整代码 效果展示 结尾 前言: 情人节.三八女神节.520.七夕节.圣诞节.元旦.生日.新年.各种纪念日……这些节日,对于每一个有女朋友的男同胞们来说都存在一个困惑的问题:送女朋友什么礼物好? 其实送礼物这件事,说难也不难,但也绝不是一件简单的事儿hhh- 送对了感情升温,送错了让你恢复单身! 但只要在挑选礼物的时候记得以下这几点,想要踩雷都很难了. 1.符合对方的审美,平时多留意一下女朋友喜欢什么东西. 2.颜值即正义,女孩子都是颜
-
Python中的探索性数据分析(功能式)
这里有一些技巧来处理日志文件提取.假设我们正在查看一些Enterprise Splunk提取.我们可以用Splunk来探索数据.或者我们可以得到一个简单的提取并在Python中摆弄这些数据. 在Python中运行不同的实验似乎比试图在Splunk中进行这种探索性的操作更有效.主要是因为我们可以无所限制地对数据做任何事.我们可以在一个地方创建非常复杂的统计模型. 理论上,我们可以在Splunk中做很多的探索.它有各种报告和分析功能. 但是... 使用Splunk需要假设我们知道我们正在寻找什么.在
-
Python实现的大数据分析操作系统日志功能示例
本文实例讲述了Python实现的大数据分析操作系统日志功能.分享给大家供大家参考,具体如下: 一 代码 1.大文件切分 import os import os.path import time def FileSplit(sourceFile, targetFolder): if not os.path.isfile(sourceFile): print(sourceFile, ' does not exist.') return if not os.path.isdir(targetFolde
-
基于python实现微信好友数据分析(简单)
一.功能介绍 本文主要介绍利用网页端微信获取数据,实现个人微信好友数据的获取,并进行一些简单的数据分析,功能包括: 1.爬取好友列表,显示好友昵称.性别和地域和签名, 文件保存为 xlsx 格式 2.统计好友的地域分布,并且做成词云和可视化展示在地图上 二.依赖库 1.Pyecharts:一个用于生成echarts图表的类库,echarts是百度开源的一个数据可视化库,用echarts生成的图可视化效果非常棒,使用pyechart库可以在python中生成echarts数据图. 2.Itchat
-
python学习之panda数据分析核心支持库
前言 Python是一门实现数据可视化很好的语言,他们里面的很多库可以很好的画出图形,形象明了. 今天我们就来说说:Pandas数据分析核心支持库 初识Pandas: Pandas 是 Python 语言的一个扩展程序库,用于数据分析. Pandas 是一个开放源码.BSD 许可的库,提供高性能.易于使用的数据结构和数据分析工具. Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分
-
30 个 Python 函数,加速数据分析处理速度
目录 1.删除列 2.选择特定列 3.nrows 4.样品 5.检查缺失值 6.使用 loc 和 iloc 添加缺失值 7.填充缺失值 8.删除缺失值 9.根据条件选择行 10.用查询描述条件 11.用 isin 描述条件 12.Groupby 函数 13.Groupby与聚合函数结合 14.对不同的群体应用不同的聚合函数 15.重置索引 16.重置并删除原索引 17.将特定列设置为索引 18.插入新列 19.where 函数 20.等级函数 21.列中的唯一值数 22.内存使用情况 23.数据
-
Python利用Pandas进行数据分析的方法详解
目录 Series 代码 #1 代码 #2 代码#3 代码 #4 数据框 代码 #1 代码 #2 代码 #3 代码 #4 Pandas是最流行的用于数据分析的 Python 库.它提供高度优化的性能,后端源代码完全用C或Python编写. 我们可以通过以下方式分析 pandas 中的数据: 1.Series 2.数据帧 Series Series 是 pandas 中定义的一维(1-D)数组,可用于存储任何数据类型. 代码 #1 创建 Series # 创建 Series 的程序 # 导入 Pa
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
python 微信好友特征数据分析及可视化
一.背景及研究现状 在我国互联网的发展过程中,PC互联网已日趋饱和,移动互联网却呈现井喷式发展.数据显示,截止2013年底,中国手机网民超过5亿,占比达81%.伴随着移动终端价格的下降及wifi的广泛铺设,移动网民呈现爆发趋势. 微信已经成为连接线上与线下.虚拟与现实.消费与产业的重要工具,它提高了O2O类营销用户的转化率.过去开发软件,程序员常要考虑不同开发环境的语言.设备的适配性和成本.现在,开发者可以在一个"类操作底层"去开发应用,打破了过去受限的开发环境. 二.研究意义及目的
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W