Python PyWebIO提升团队效率使用介绍
目录
- 引言
- 简介
- Step one:本地文件上传
- Step two:风险值卡控
- Step Three: 标签卡控
- 总结
引言
Q&A快速了解PyWebIO
Q:首先,什么是PyWebIO?
A:PyWebIO提供了一系列命令式的交互函数,能够让咱们用只用Python就可以编写 Web 应用, 不需要编写前端页面和后端接口, 让简易的UI开发效率大大提高(本人非研发,用词可能不妥,大家轻点喷)
Q:其次,我们能用来干嘛?? 这对一个团队的效率提升有什么作用??
A:Pywebio的作用在于让咱们可以快速的开发一个带有UI界面的,支持用户输入的,以既定的逻辑输出结果的应用。 那么,我们是不是可以将团队内一些机械性的数据处理,数据异动分析等的工作以既定逻辑的方式通过Pywebio输出一个可复用的应用给大家使用呢? 当然,日常的数据运营过程中,咱们肯定不是面对着一成不变的case。 那么,我们是不是可以用不同参数输入的方式来达到一定的泛用性拓展呢? 只要,case和case之间的底层逻辑是一致的,我们就可以用同一套逻辑,不同的入参来达到不同结果输出的获取。
Exampl 倘若,我们每天都有一项工作,每天对着一份又一份业务反馈的订单,然后部门需要对着这些订单本身进行一个初步的风险分层,我们是不是可以把风险分层的底层规则写在后端,然后通过PywebIO来支持不同情况下的不同规则阈值输入, 快速获取咱们所需要的风险分层结果。 (当然,如果数据允许,直接写SQL也可以,可是,SQL需要一定的门槛,而PywebIO则可以通过UI的方式分享给那些没有技术背景的运营人员进行0代码使用。)
以下正式开始用一个例子来逐步介绍PywebIO拓展包
简介
虚拟背景: 每天需要一份又一份地对业务反馈的样本来进行风险分层,为了提高处理效率。
计划方案: 通过现有风险标签的波尔标签,非波尔标签体系来搭建一个支持 灵活配置阈值来快速获取分层结果的UI应用。
方案简介:基本逻辑如下,(以下均为举例所示,并不代表该方案就可以进行风险分层哈,大家请注意)
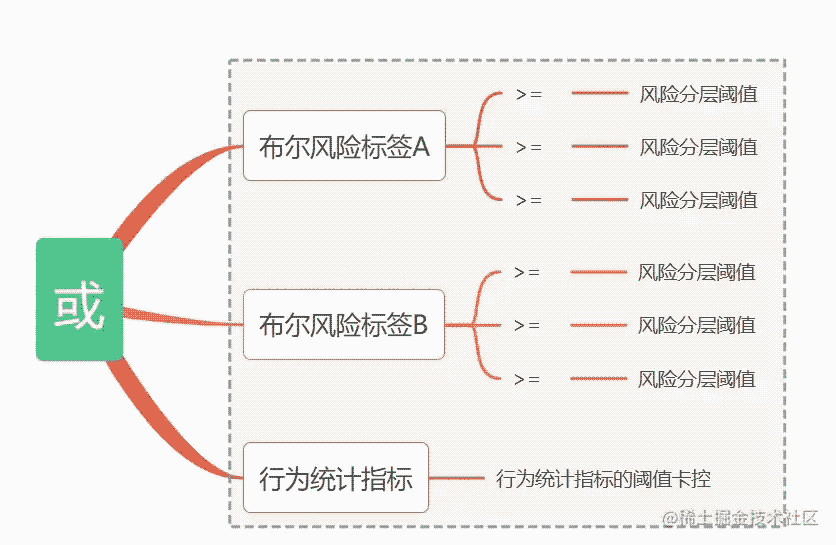
开始实现:这里的例子采取的是非数据库模式,支持的是上传本地csv,然后进行阈值配置。
Step one:本地文件上传
首先,肯定是得先文件上传的代码。
##例子如下:
import pandas as pd
from pywebio.input import *
from pywebio import start_server
from pywebio.output import *
import nest_asyncio
import numpy as np
import os
import time
nest_asyncio.apply()
import pandas as pd
from pywebio.input import *
from pywebio import start_server
from pywebio.output import *
import nest_asyncio
import numpy as np
import os
import time
nest_asyncio.apply()
def read_csv():
put_markdown('# 只支持pin')
put_markdown('功能如下:')
put_markdown("""
- 选择与程序再**同一文件夹**的文件
- 输入你希望卡的风险值阈值 **不输入则默认-10**
- 自动加载解析输出极黑标签占比以及明细数据
- 请勾选你所需要的标签**(不勾选=全选)**,然后点击提交即可
""")
file = file_upload('只支持上传该程序所在文件夹的csv文件哦', '.csv')
## 本地文件
raw_data = pd.read_csv(os.getcwd() + "\" + file['filename'], encoding='gbk')
put_html(raw_data.to_html())
if __name__ == '__main__':
start_server(read_csv, port=8081, debug=True, cdn=False, auto_open_webbrowser=True)
允许代码后,因为” auto_open_webbrowser=True“,所以自动弹出一个WebUI,如下左图,选择上传的文件,即可看到下右图的文件数据
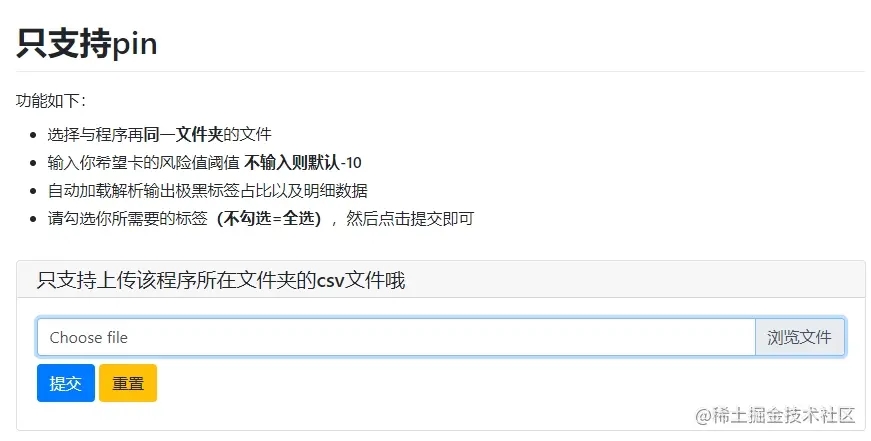
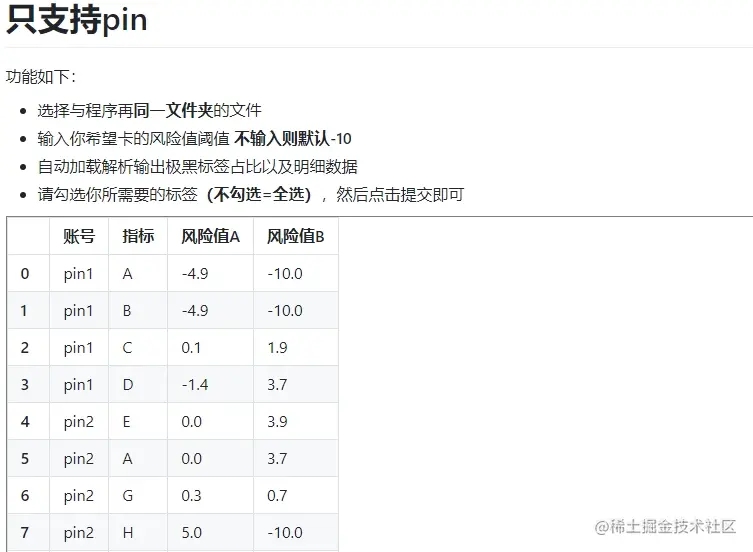
Step two:风险值卡控
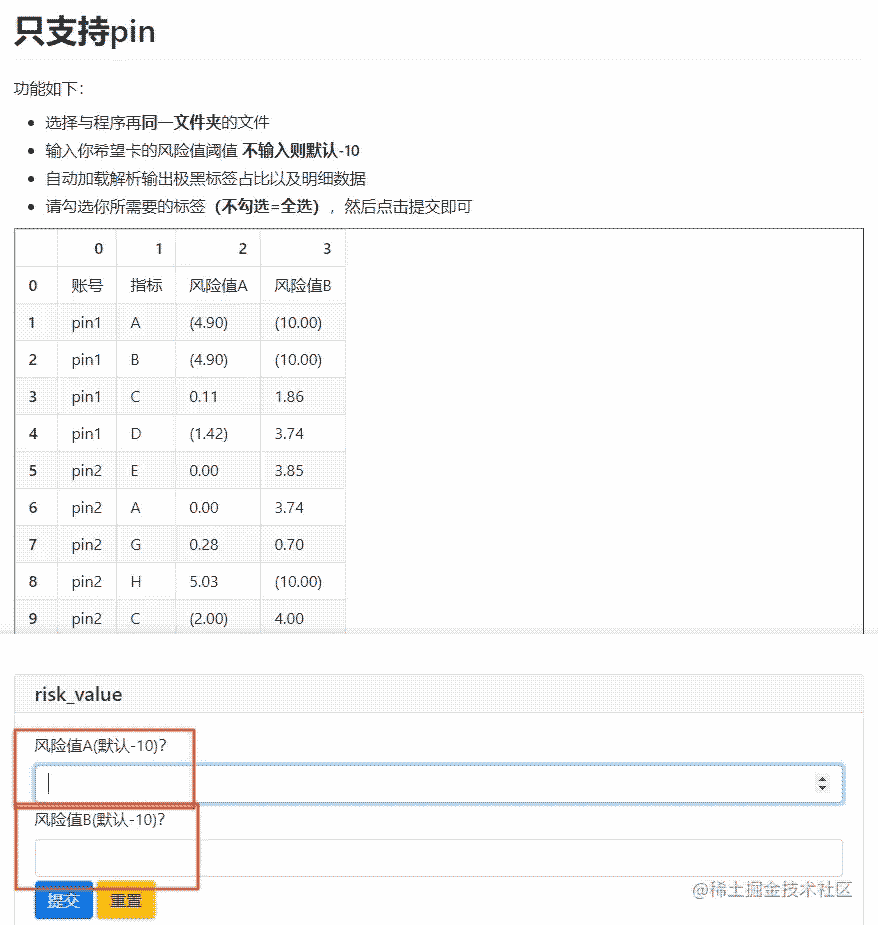
第一步也只是上传文件,展示文件,还没达到咱们的目的。 所以,第二步则是需要对上传的csv本身进行数据处理,逻辑判断。 这里其实很好理解,在step one 中已经获取了上传的文件且转成dataframe了对吧,那么实际,咱们只需要沿用咱们熟悉的pandans对dataframe进行处理即可。
import pandas as pd
from pywebio.input import *
from pywebio import start_server
from pywebio.output import *
import nest_asyncio
import numpy as np
import os
import time
nest_asyncio.apply()
def 配置规则_风险值阈值(df, user_risk, pp_risk=None):
df_updated = df[(df['风险值A'] >=user_risk)|((df['风险值B'] >=pp_risk))]
return df_updated
def read_csv():
put_markdown('# 只支持pin')
put_markdown('功能如下:')
put_markdown("""
- 选择与程序再**同一文件夹**的文件
- 输入你希望卡的风险值阈值 **不输入则默认-10**
- 自动加载解析输出极黑标签占比以及明细数据
- 请勾选你所需要的标签**(不勾选=全选)**,然后点击提交即可
""")
file = file_upload('只支持上传该程序所在文件夹的csv文件哦', '.csv')
## 本地文件
data = []
raw_data = pd.read_csv(os.getcwd() + "\" + file['filename'], encoding='gbk')
put_html(raw_data.to_html())
## -------------------------- 下面是 step two 新增的代码 --------------------------
risk_value = input_group(
"risk_value",
[
input("风险值A(默认-10)?", name="user_risk", type=NUMBER),
input("风险值B(默认-10)?", name="pp_risk", type=NUMBER)
],
)
raw_data_upated = 配置规则_风险值阈值(raw_data,risk_value['user_risk'], risk_value['pp_risk'])
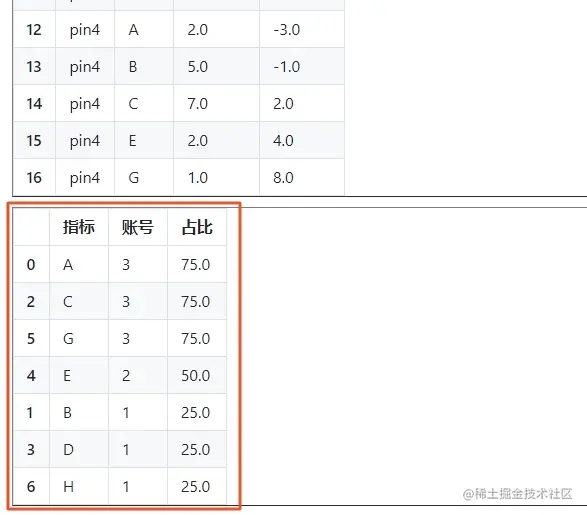
table1 = raw_data_upated.groupby('指标').账号.count().reset_index()
table1['占比'] = table1.账号 / len(raw_data_upated.账号.unique()) * 100
table1.sort_values('占比', ascending=False, inplace=True)
put_html(table1.to_html())
## -------------------------- 上面是 step two 新增的代码 --------------------------
if __name__ == '__main__':
start_server(read_csv, port=8081, debug=True, cdn=False, auto_open_webbrowser=True)
Step Three: 标签卡控
从第二步,我们已经完成了风险值阈值的卡控,然后第三步就是标签的选取了。从对标签的理解和应用经验以及第二步得到的标签在样本中的占比,咱们就可以快速的知道,这个样本里面的标签分布分别是什么。进一步可以通过标签的选取达到最终符合我们风险分层结果中有风险的那一部分的输出了
import pandas as pd
from pywebio.input import *
from pywebio import start_server
from pywebio.output import *
import nest_asyncio
import numpy as np
import os
import time
nest_asyncio.apply()
def 配置规则_风险值阈值(df, user_risk, pp_risk=None):
df_updated = df[(df['风险值A'] >=user_risk)|((df['风险值B'] >=pp_risk))]
return df_updated
def read_csv():
put_markdown('# 只支持pin')
put_markdown('功能如下:')
put_markdown("""
- 选择与程序再**同一文件夹**的文件
- 输入你希望卡的风险值阈值 **不输入则默认-10**
- 自动加载解析输出极黑标签占比以及明细数据
- 请勾选你所需要的标签**(不勾选=全选)**,然后点击提交即可
""")
file = file_upload('只支持上传该程序所在文件夹的csv文件哦', '.csv')
## 本地文件
data = []
raw_data = pd.read_csv(os.getcwd() + "\" + file['filename'], encoding='gbk')
put_html(raw_data.to_html())
risk_value = input_group(
"risk_value",
[
input("风险值A(默认-10)?", name="user_risk", type=NUMBER),
input("风险值B(默认-10)?", name="pp_risk", type=NUMBER)
],
)
raw_data_upated = 配置规则_风险值阈值(raw_data,risk_value['user_risk'], risk_value['pp_risk'])
table1 = raw_data_upated.groupby('指标').账号.count().reset_index()
table1['占比'] = table1.账号 / len(raw_data_upated.账号.unique()) * 100
table1.sort_values('占比', ascending=False, inplace=True)
put_html(table1.to_html())
## -------------------------- 下面是 step three 新增的代码 --------------------------
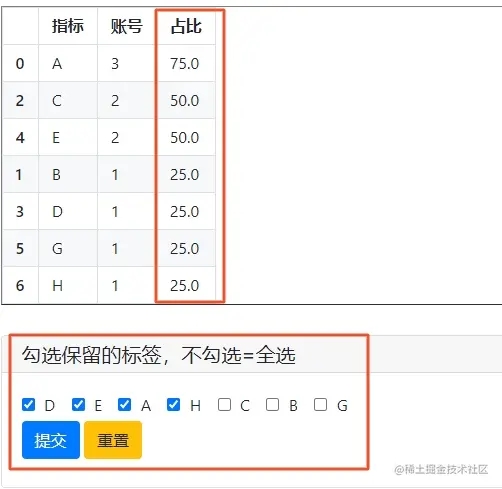
set_list = raw_data_upated.指标.unique()
list_save = checkbox(label='勾选保留的标签,不勾选=全选', options=set_list, inline=True)
if list_save == []:
list_save = set_list
else:
list_save = list_save
raw_data_upated = raw_data_upated[raw_data_upated.指标.isin(list_save)]
put_html(raw_data_upated.to_html())
def Save0():
put_markdown("You click Save button, Done").show()
raw_data_upated.to_excel(os.getcwd() + "\" + '输出的风险明细.xlsx', index=False)
put_markdown("find your file on 程序同级文件夹下的 文件 : 输出的风险明细.xlsx").show()
put_buttons(['下载文件"对内不对外输出明细.xlsx"'], onclick=[Save0]).show()
## -------------------------- 上面是 step three 新增的代码 --------------------------
if __name__ == '__main__':
start_server(read_csv, port=8081, debug=True, cdn=False, auto_open_webbrowser=True)

总结
这里只是举了个简单的例子,一个支持阈值+标签卡控,快速获取符合要求的目标群体的例子。 实际上,这个框架的拓展还有很多。例如:
1.直连数据库,可以帮住那些不会sql的同事可以自定义快速获取业务数据。
2.Pyinstaller封装成本地程序,脱离代码环境,可以在任意电脑,任意环境,任意人士进行使用,有兴趣的同学可以看《Python-Pyinstaller介绍》
以上就是Python PyWebIO提升团队效率使用介绍的详细内容,更多关于Python PyWebIO效率提升的资料请关注我们其它相关文章!
相关推荐
-

Python PyWebIO实现网页版数据查询器
界面的制作一直是 Python 的痛!使用 Python 制作桌面端界面是非常痛苦的过程(又难学又难看).不过,Python 已经出现了几个基于web前端的库,他们的基本机制大同小异,如果对 界面操作性没有太大要求,那么这些库就比较适合你 . 这个系列基于 pywebio 的一系列实战应用,让我们从实战中学习这个库的使用! 本节最终效果动图: 选择 excel 文件 输出文件第一个工作表的数据(DataFrame) 安装库: pip install -U pywebio 输出文本 先输出一段内容
-
Python如何处理大数据?3个技巧效率提升攻略(推荐)
如果你有个5.6 G 大小的文件,想把文件内容读出来做一些处理然后存到另外的文件去,你会使用什么进行处理呢?不用在线等,给几个错误示范:有人用multiprocessing 处理,但是效率非常低.于是,有人用python处理大文件还是会存在效率上的问题.因为效率只是和预期的时间有关,不会报错,报错代表程序本身出现问题了~ 所以,为什么用python处理大文件总有效率问题? 如果工作需要,立刻处理一个大文件,你需要注意两点: 01.大型文件的读取效率 面对100w行的大型数据,经过测试各种文件读取
-
python人工智能深度学习算法优化
目录 1.SGD 2.SGDM 3.Adam 4.Adagrad 5.RMSProp 6.NAG 1.SGD 随机梯度下降 随机梯度下降和其他的梯度下降主要区别,在于SGD每次只使用一个数据样本,去计算损失函数,求梯度,更新参数.这种方法的计算速度快,但是下降的速度慢,可能会在最低处两边震荡,停留在局部最优. 2.SGDM SGM with Momentum:动量梯度下降 动量梯度下降,在进行参数更新之前,会对之前的梯度信息,进行指数加权平均,然后使用加权平均之后的梯度,来代替原梯度,进行参数的
-
python编程学习使用管道Pipe编写优化代码
目录 什么是管道? Where:可迭代对象中的过滤元素 Select: 将函数应用于可迭代对象 展开可迭代对象 1.chain方法 2.traverse:递归展开可迭代对象 将列表中的元素分组 结论 我们知道 map 和 filter 是两种有效的 Python 方法来处理可迭代对象. 但是,如果你同时使用 map 和 filter,代码可能看起来很混乱. 如果你可以使用管道那不是更好了?像下面这样的方式来处理. Pipe 库可以做到这一点. 什么是管道? Pipe 是一个 Python 库,可
-
python人工智能tensorflowtf优化器Optimizer算法汇总
目录 前言 tensorflow常见的Optimizer 1 梯度下降法 2 Adagrad下降法 3 动量优化法 4 RMSProp算法 5 Adam算法 例子 1 梯度下降法 2 Adagrad下降法 3 动量优化法 4 RMSProp算法 5 Adam算法 总结 前言 优化器的选择关乎参数更新的方法,合理的方法可以帮助机器学习更好的寻找到全局最佳值.那我们快点开始学习吧 tensorflow常见的Optimizer 1 梯度下降法 tf.train.GradientDescentOptim
-
python优化数据预处理方法Pandas pipe详解
我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用.Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法. import numpy as np import pandas as pd df = pd.DataFrame({ "id": [100, 100, 101, 102, 103, 104, 105, 106], "A": [1, 2, 3, 4, 5, 2, np.nan, 5], "B":
-
Python数学建模学习模拟退火算法多变量函数优化示例解析
目录 1.模拟退火算法 2.多变量函数优化问题 3.模拟退火算法 Python 程序 4.程序运行结果 1.模拟退火算法 退火是金属从熔融状态缓慢冷却.最终达到能量最低的平衡态的过程.模拟退火算法基于优化问题求解过程与金属退火过程的相似性,以优化目标为能量函数,以解空间为状态空间,以随机扰动模拟粒子的热运动来求解优化问题([1] KIRKPATRICK,1988). 模拟退火算法结构简单,由温度更新函数.状态产生函数.状态接受函数和内循环.外循环终止准则构成. 温度更新函数是指退火温度缓慢降低的
-
python中的PywebIO模块制作一个数据大屏
目录 一.PywebIO介绍 二.PywebIO和Pyecharts的组合 三.PywebIO和Bokeh的组合 四.基于浏览器的GUI应用 一.PywebIO介绍 Python当中的PywebIO模块可以帮助开发者在不具备HTML和JavaScript的情况下也能够迅速构建Web应用或者是基于浏览器的GUI应用,PywebIO还可以和一些常用的可视化模块联用,制作成一个可视化大屏, 我们先来安装好需要用到的模块 pip install pywebio pip install cutechart
-
python如何提升爬虫效率
单线程+多任务异步协程 协程 在函数(特殊函数)定义的时候,使用async修饰,函数调用后,内部语句不会立即执行,而是会返回一个协程对象 任务对象 任务对象=高级的协程对象(进一步封装)=特殊的函数 任务对象必须要注册到时间循环对象中 给任务对象绑定回调:爬虫的数据解析中 事件循环 当做是一个装载任务对象的容器 当启动事件循环对象的时候,存储在内的任务对象会异步执行 特殊函数内部不能写不支持异步请求的模块,如time,requests...否则虽然不报错但实现不了异步 time.sleep --
-
Go语言提升开发效率的语法糖技巧分享
目录 前言 可变长参数 声明不定长数组 init函数 忽略导包 忽略字段 json序列化忽略某个字段 json序列化忽略空值字段 短变量声明 类型断言 切片循环 判断map的key是否存在 select控制结构 前言 哈喽,大家好,我是asong. 每门语言都有自己的语法糖,像java的语法糖就有方法变长参数.拆箱与装箱.枚举.for-each等等,Go语言也不例外,其也有自己的语法糖,掌握这些语法糖可以助我们提高开发的效率,所以本文就来介绍一些Go语言的语法糖,总结的可能不能全,欢迎评论
-
python 性能提升的几种方法
关于python 性能提升的一些方案. 一.函数调用优化(空间跨度,避免访问内存) 程序的优化核心点在于尽量减少操作跨度,包括代码执行时间上的跨度以及内存中空间跨度. 1.大数据求和,使用sum a = range(100000) %timeit -n 10 sum(a) 10 loops, best of 3: 3.15 ms per loop %%timeit ...: s = 0 ...: for i in a: ...: s += i ...: 100 loops, best of 3:
-
chrome开发者助手插件v2.10发布提升开发效率不再只是口号
chrome开发者助手插件v2.10发布了,这个版本重点提升了常用工具的使用效率: 插件下载地址 1. 新标签页支持一键打开常用小工具 开发同学使用比较频繁的IP查询.二维码转换.时间戳转换.文档查询.翻译等小工具,可以在桌面一键打开使用 2. 新标签页支持文件夹,内置开发者工具箱 桌面可以建文件夹了,大家可以通过文件夹来分类管理常用网址.小工具了.而且已经为大家梳理了开发者工具箱方便大家使用.非新用户可以到系统分类里面添加到桌面上 3. 浏览器工具栏有快捷入口了 通过浏览器设置可以打开快捷入口
-
分享几个快速提升工作效率的小工具(Listary等)
给方法名命名的工具 不知道你是否有在给方法或者类起一个合适的方法名而苦苦思索,或者用翻译软件来进行翻译.现在有一个很好用的插件来了.四不四很期待.现在就让它隆重登场吧.Translation 直接在 Settings--->Plugins 中搜索Translation 进行安装就可以了. 安装后插件之后,接下来就是使用插件了,最简单的使用方法就是,描述好你想定义的方法的主要作用,如下:我有个任务处理的方法.在描述上右键 有两个选项栏,一个是Translate,一个是Translate and R
-
强烈推荐这些提升代码效率的IDEA使用技巧
一.SVN的集成 IDEA默认集成了对Svn的支持 . File ->Setting 直接设置执行程序即可. 注意:如果设置之后依然无法使用svn,是因为安装SVN的时候没有选择命令行工具. 解决方法:重装SVN,配置项重新选择command line client tools 即可. 二.开启热更新 有发现不少同学不知道热更新,还在为了调一行代码重启服务器,然后调试,效率太低,开启热更新,实时修改代码,实时看效果. 具体步骤: File ->Settings -Build -> Com
-
JS 4个超级实用的小技巧 提升开发效率
目录 1.短路判断 2.可选链操作符 ( ? ) 3.空值合并操作符 ( ?? ) 4.return终止函数 1.短路判断 当只需要简单的if条件时,可使用此方法 let x = 0; let foo = () => console.log('执行了'); if(x === 0){ foo() } 通过使用&&运算符来实现同样的if功能,如果&&之前的条件为false,则&&之后的代码将不会执行. let x = 0; let foo = () =&g
-
56个实用的JavaScript 工具函数助你提升开发效率
目录 1. 数字操作 (1)生成指定范围随机数 2. 数组操作 (1)数组乱序 (2)数组扁平化 (3)数组中获取随机数 3. 字符串操作 (1)生成随机字符串 (2)字符串首字母大写 (3)手机号中间四位变成* (4)驼峰命名转换成短横线命名 (5)短横线命名转换成驼峰命名 (6)全角转换为半角 (7)半角转换为全角 4. 格式转化 (1)数字转化为大写金额 (2)数字转化为中文数字 5. 操作存储 (1)存储loalStorage (2)获取localStorage (3)删除localSt
-
python 多线程与多进程效率测试
目录 1.概述 2.代码练习 3.运行结果 1.概述 在Python中,计算密集型任务适用于多进程,IO密集型任务适用于多线程 正常来讲,多线程要比多进程效率更高,因为进程间的切换需要的资源和开销更大,而线程相对更小,但是我们使用的Python大多数的解释器是Cpython,众所周知Cpython有个GIL锁,导致执行计算密集型任务时多线程实际只能是单线程,而且由于线程之间切换的开销导致多线程往往比实际的单线程还要慢,所以在 python 中计算密集型任务通常使用多进程,因为各个进程有各自独立的