python根据用户需求输入想爬取的内容及页数爬取图片方法详解
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。
主要步骤:
1.提示用户输入爬取的内容及页码。
2.根据用户输入,获取网址列表。
3.模拟浏览器向服务器发送请求,获取响应。
4.利用xpath方法找到图片的标签。
5.保存数据。
代码用面向过程的形式编写的。
关键字:requests库,xpath,面向过程
现在就来讲解代码书写的过程:
1.导入模块
import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配 import requests # 爬虫主要的包 from urllib.request import urlretrieve # 本文用来下载图片 import os # 标准库,本文用来新建文件夹
每个模块的作用都已经备注了。
2.提示用户输入内容和页数
if not os.path.exists("王一博图片"):
os.mkdir("王一博图片") # 判断有没有该文件夹,如果没有就创建改文件夹
k = input("请输入你想搜索的关键字:")
num = int(input("请输入你想搜索的页数:"))
3.准备好url和header
header = {"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Mobile Safari/537.36"
}
base_url = "https://www.duitang.com/search/?kw=" + k + "&type=feed#!s-p"
title_url = []
n = 0
user-agent是服务器识别浏览器的重要参数,我们就用这个来蒙骗服务器,user-agent在浏览器里可以找到
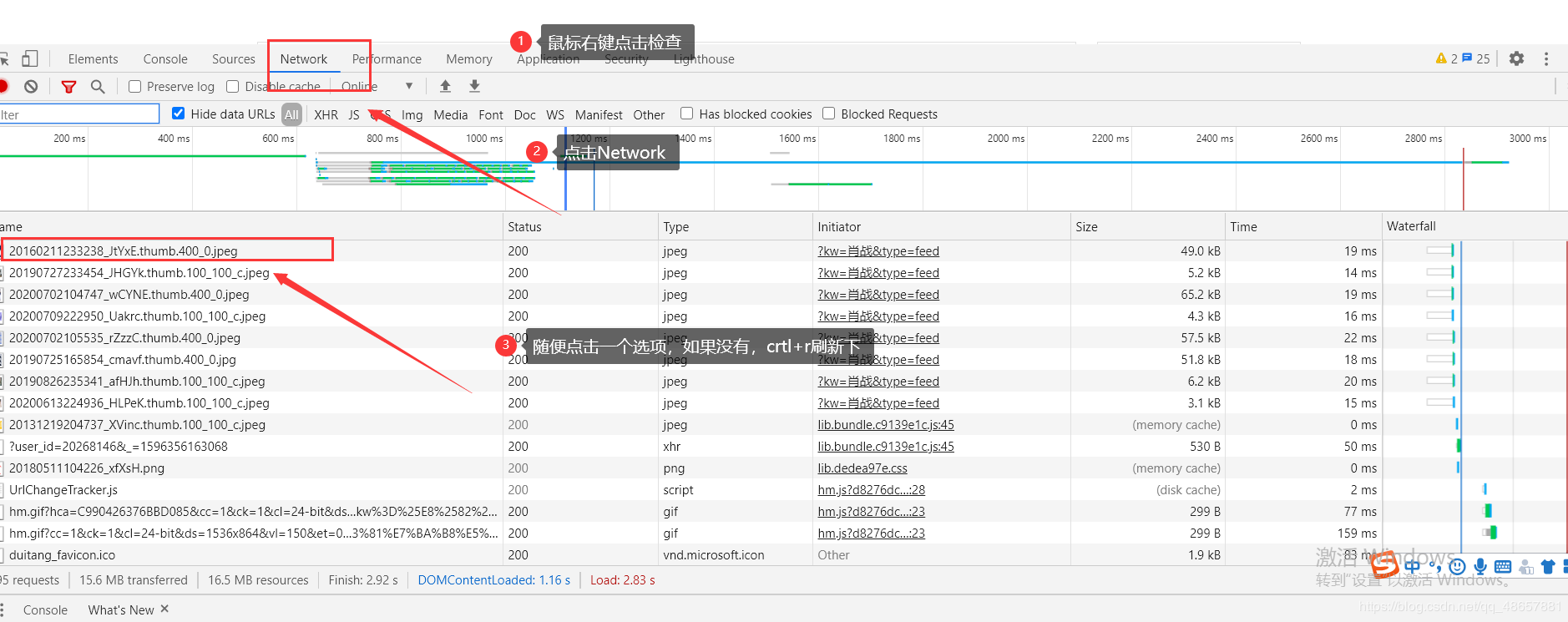
那么现在我们就关注右边
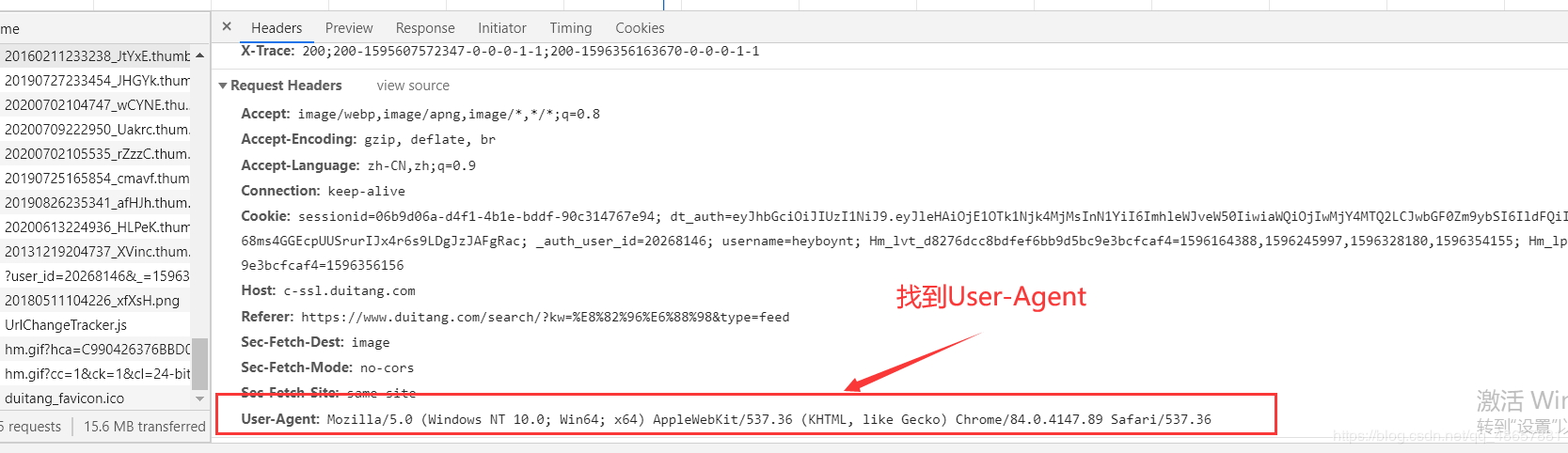
这样header就找到了,注意要以字典的形式
4.发送请求、
for i in range(num):
title_url = base_url + str(i)
respons = requests.get(title_url, headers=header).text
html = parsel.Selector(respons) # 解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
pic_url = html.xpath('//div[@class="mbpho"]/a/img/@src').extract()
一切准备就绪后,就可以发送请求了。request.get.text返回的是网页的源代码,然后将源代码转换为Selector对象,再通过xpath的方法找到图片的网址。
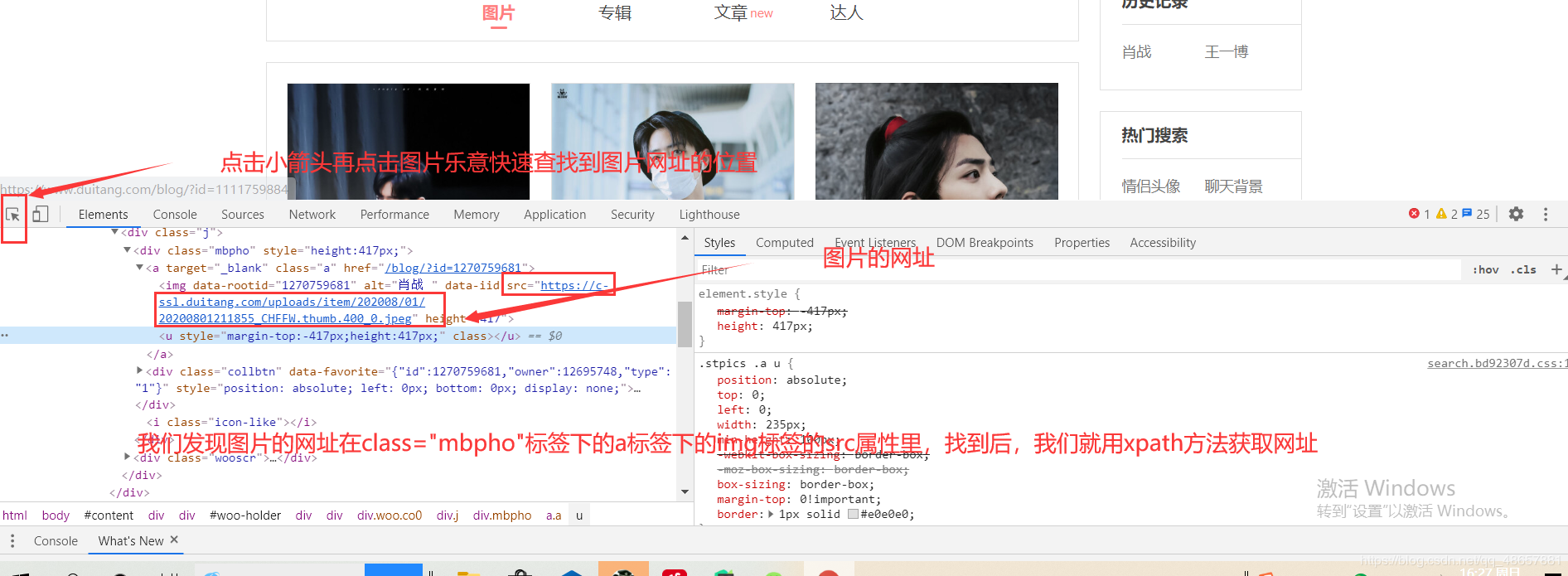
xpath的方法可以参考:https://zhuanlan.zhihu.com/p/29436838
5.保存数据
获取图片的图片的链接后,我们就可以保存了。
for url in pic_url:
n = n + 1
file_path = "王一博图片" + '/' + str(n)+".jpg"
urlretrieve(url, file_path) # 下载图片,具体的用法可以去搜索下,很简单的
print("第%d张图片下载成功" % n)
注意:这里的for循环是在上面的循环里嵌套的。
最后来看看全部的代码吧!
import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配
import requests
from urllib.request import urlretrieve # 本文用来下载图片
import os # 标准库,本文用来新建文件夹
if not os.path.exists("王一博图片"):
os.mkdir("王一博图片") # 判断有没有该文件夹,如果没有就创建改文件夹
k = input("请输入你想搜索的关键字:")
num = int(input("请输入你想搜索的页数:"))
header = {"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Mobile Safari/537.36"
}
base_url = "https://www.duitang.com/search/?kw=" + k + "&type=feed#!s-p"
title_url = []
n = 0
for i in range(num):
title_url = base_url + str(i)
respons = requests.get(title_url, headers=header).text
html = parsel.Selector(respons)
pic_url = html.xpath('//div[@class="mbpho"]/a/img/@src').extract()
# print(pic_url)
for url in pic_url:
n = n + 1
file_path = "王一博图片" + '/' + str(n)+".jpg"
urlretrieve(url, file_path) # 下载图片,具体的用法可以去搜索下,很简单的
print("第%d张图片下载成功" % n)
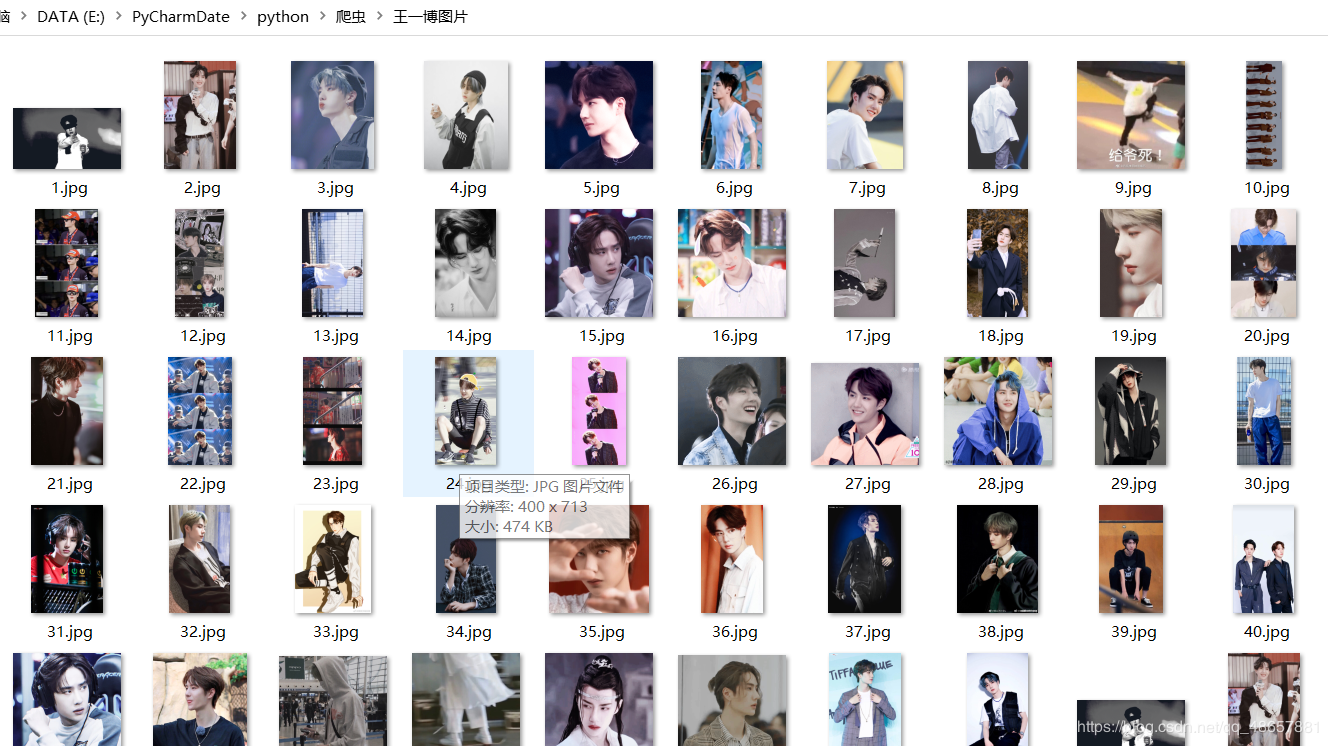
来看看运行的结果,以搜索王一博,搜索5页为例。
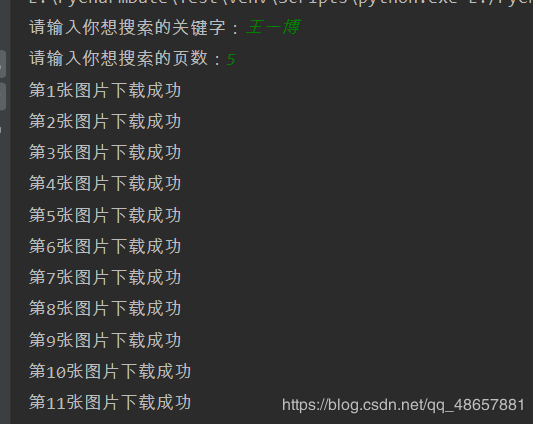
然后你就发信多了一个王一博的文件夹了,点开就可以看见王一博的帅照了。
到此这篇关于python根据用户需求输入想爬取的内容及页数爬取图片方法详解的文章就介绍到这了,更多相关python爬取图片方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取知乎图片代码实现解析
首先,需要获取任意知乎的问题,只需要你输入问题的ID,就可以获取相关的页面信息,比如最重要的合计有多少人回答问题. 问题ID为如下标红数字 编写代码,下面的代码用来检测用户输入的是否是正确的ID,并且通过拼接URL去获取该问题下面合计有多少答案. import requests import re import pymongo import time DATABASE_IP = '127.0.0.1' DATABASE_PORT = 27017 DATABASE_NAME = 'sun' cli
-
python协程gevent案例 爬取斗鱼图片过程解析
分析 分析网站寻找需要的网址 用谷歌浏览器摁F12打开开发者工具,然后打开斗鱼颜值分类的页面,如图: 在里面的请求中,最后发现它是以ajax加载的数据,数据格式为json,如图: 圈住的部分是我们需要的数据,然后复制它的网址为https://www.douyu.com/gapi/rknc/directory/yzRec/1,出于学习目的只爬取第一页(减少服务器压力).然后把网址放到浏览器中测试是否可以访问.如图: 结果正常. 分析json数据,提取图片链接 最后分析发现json中的data里面的
-
python2爬取百度贴吧指定关键字和图片代码实例
目的:在百度贴吧输入关键字和要查找的起始结束页,获取帖子里面楼主所发的图片 思路: 获取分页里面的帖子链接列表 获取帖子里面楼主所发的图片链接列表 保存图片到本地 注意事项: 问题:在谷歌浏览器使用xpath helper插件时有匹配结果,但在程序里面使用python内带的xpath匹配却为空的原因. 原因:不同服务器会对不同的浏览器返回不同的数据,导致在谷歌浏览器看到的和服务器返回的有区别 解决方法:使用IE浏览器的User-agenet,而且越老的版本,报错几率相对越小 #!/usr/bin
-
python3 requests库实现多图片爬取教程
最近对爬虫比较感兴趣,所以就学了一下,看人家都在网上爬取那么多美女图片养眼,我也迫不及待的试了一下,不多说,切入正题. 其实爬取图片和你下载图片是一个样子的,都是操作链接,也就是url,所以当我们确定要爬取的东西后就要开始寻找url了,所以先打开百度图片搜一下 然后使用浏览器F12进入开发者模式,或者右键检查元素 注意看xhr,点开观察有什么不一样的(如果没有xhr就在网页下滑) 第一个是这样的 第二个是这样的 注意看,pn是不是是30的倍数,而此时网页图片的数量也在增多,发现了这个,进url看
-
Python爬虫爬取煎蛋网图片代码实例
这篇文章主要介绍了Python爬虫爬取煎蛋网图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天,试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代码: import urllib.request import os def url_open(url): req = urllib.reques
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
python实现爬取百度图片的方法示例
本文实例讲述了python实现爬取百度图片的方法.分享给大家供大家参考,具体如下: import json import itertools import urllib import requests import os import re import sys word=input("请输入关键字:") path="./ok" if not os.path.exists(path): os.mkdir(path) word=urllib.parse.quote(w
-
Python实现的爬取百度贴吧图片功能完整示例
本文实例讲述了Python实现的爬取百度贴吧图片功能.分享给大家供大家参考,具体如下: #coding:utf-8 import requests import urllib2 import urllib ``` from lxml import etree class Tieba: def __init__(self): self.tiebaName = raw_input("请输入需要爬取的贴吧:") self.beginPage = int(raw_input("请输入
-
Python Scrapy图片爬取原理及代码实例
1.在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 在管道文件对图片进行下载和持久化存储 class ImgSpider(scrapy.Spider): name = 'img' # allowed_domains = ['www.xxx.com'] start_urls = ['http://www.521609.com/daxuemeinv/'] url = 'http://www.521609.com/daxuemeinv/list8%d.html' pageNum = 1 d
-
python实现知乎高颜值图片爬取
导入相关包 import time import pydash import base64 import requests from lxml import etree from aip import AipFace from pathlib import Path 百度云 人脸检测 申请信息 #唯一必须填的信息就这三行 APP_ID = "xxxxxxxx" API_KEY = "xxxxxxxxxxxxxxxx" SECRET_KEY = "xxxxx