Apache Linkis 中间件架构及快速安装步骤
目录
- 1、ApacheLinkis介绍
- 2.1计算中间件概念
- 2.2整体架构
- 2.3核心特点
- 2.4支持的引擎类型
- 2、ApacheLinkis快速部署
- 2.1注意事项
- 2.2确定环境
- 2.2.1依赖
- 2.2.2环境变量
- 2.3安装包下载
- 2.4不依赖HDFS的基础配置修改
- 2.5修改数据库配置
- 2.6安装
- 2.7检查是否安装成功
- 2.8快速启动Linkis
- 2.9问题集
1、Apache Linkis 介绍
Linkis 在上层应用和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问Spark, Presto, Flink 等底层引擎,同时实现跨引擎上下文共享、统一的计算任务和引擎治理与编排能力。
MySQL/Spark/Hive/Presto/Flink 等底层引擎,同时实现变量、脚本、函数和资源文件等用户资源的跨上层应用互通。作为计算中间件,Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。通过计算中间件将应用层和引擎层解耦,简化了复杂的网络调用关系,降低了整体复杂度,同时节约了整体开发和维护成本。
2.1 计算中间件概念
没有Linkis之前
上层应用以紧耦合方式直连底层引擎,使得数据平台变成复杂的网状结构

有Linkis之后
通过计算中间件将应用层和引擎层解耦,以标准化可复用方式简化复杂的网状调用关系,降低数据平台复杂度
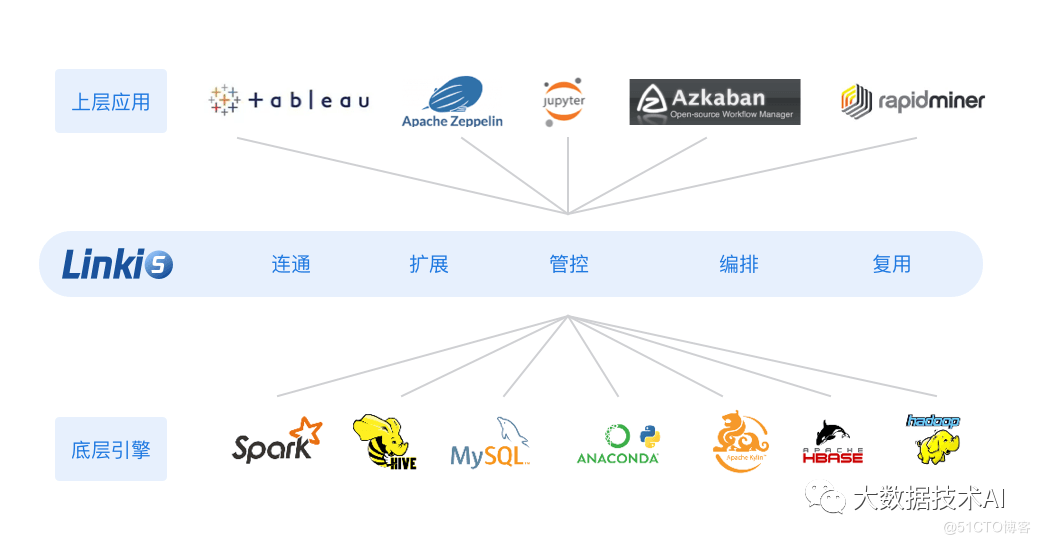
2.2 整体架构
Linkis 在上层应用和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问Spark, Presto, Flink 等底层引擎。
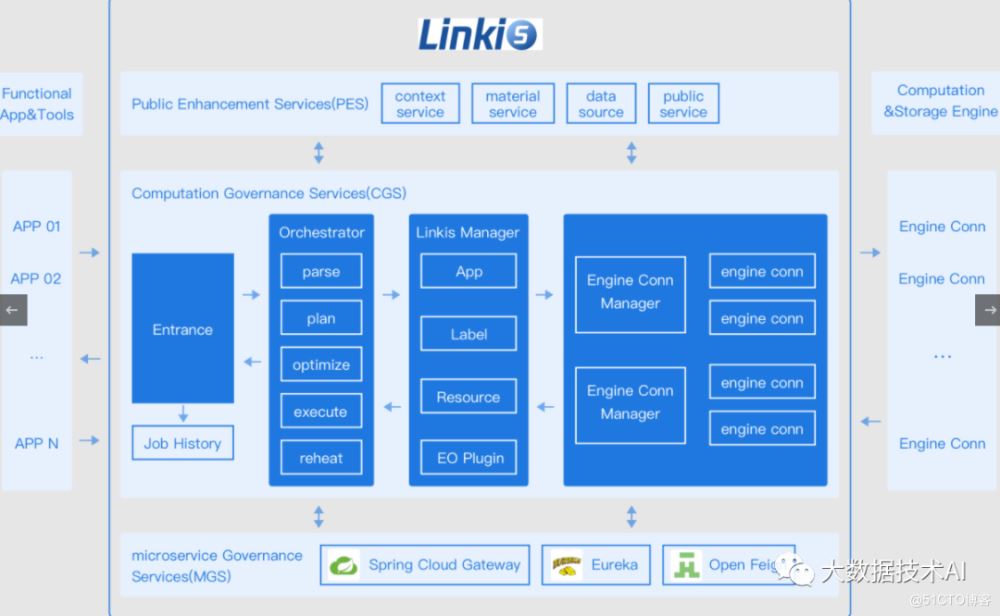
2.3 核心特点
- 丰富的底层计算存储引擎支持。目前支持的计算存储引擎:Spark、Hive、Python、Presto、ElasticSearch、MLSQL、TiSpark、JDBC和Shell等。正在支持中的计算存储引擎:Flink(>=1.0.2版本已支持)、Impala等。支持的脚本语言:SparkSQL, HiveQL, Python, Shell, Pyspark, R, Scala 和JDBC 等。
- 强大的计算治理能力。基于Orchestrator、Label Manager和定制的Spring Cloud Gateway等服务,Linkis能够提供基于多级标签的跨集群/跨IDC 细粒度路由、负载均衡、多租户、流量控制、资源控制和编排策略(如双活、主备等)支持能力。
- 全栈计算存储引擎架构支持。能够接收、执行和管理针对各种计算存储引擎的任务和请求,包括离线批量任务、交互式查询任务、实时流式任务和存储型任务;
- 资源管理能力。ResourceManager 不仅具备 Linkis0.X 对 Yarn 和 Linkis EngineManager 的资源管理能力,还将提供基于标签的多级资源分配和回收能力,让 ResourceManager 具备跨集群、跨计算资源类型的强大资源管理能力。
- 统一上下文服务。为每个计算任务生成context id,跨用户、系统、计算引擎的关联管理用户和系统资源文件(JAR、ZIP、Properties等),结果集,参数变量,函数等,一处设置,处处自动引用;
- 统一物料。系统和用户级物料管理,可分享和流转,跨用户、系统共享物料。
2.4 支持的引擎类型
|
引擎 |
引擎版本 |
Linkis 0.X 版本要求 |
Linkis 1.X 版本要求 |
说明 |
|
Flink |
1.12.2 |
>=dev-0.12.0, PR #703 尚未合并 |
>=1.0.2 |
Flink EngineConn。支持FlinkSQL 代码,也支持以Flink Jar 形式启动一个新的Yarn 应用程序。 |
|
Impala |
>=3.2.0, CDH >=6.3.0" |
>=dev-0.12.0, PR #703 尚未合并 |
ongoing |
Impala EngineConn. 支持Impala SQL 代码. |
|
Presto |
>= 0.180 |
>=0.11.0 |
ongoing |
Presto EngineConn. 支持Presto SQL 代码. |
|
ElasticSearch |
>=6.0 |
>=0.11.0 |
ongoing |
ElasticSearch EngineConn. 支持SQL 和DSL 代码. |
|
Shell |
Bash >=2.0 |
>=0.9.3 |
>=1.0.0_rc1 |
Shell EngineConn. 支持Bash shell 代码. |
|
MLSQL |
>=1.1.0 |
>=0.9.1 |
ongoing |
MLSQL EngineConn. 支持MLSQL 代码. |
|
JDBC |
MySQL >=5.0, Hive >=1.2.1 |
>=0.9.0 |
>=1.0.0_rc1 |
JDBC EngineConn. 已支持MySQL 和HiveQL,可快速扩展支持其他有JDBC Driver 包的引擎, 如Oracle. |
|
Spark |
Apache 2.0.0~2.4.7, CDH >=5.4.0 |
>=0.5.0 |
>=1.0.0_rc1 |
Spark EngineConn. 支持SQL, Scala, Pyspark 和R 代码. |
|
Hive |
Apache >=1.0.0, CDH >=5.4.0 |
>=0.5.0 |
>=1.0.0_rc1 |
Hive EngineConn. 支持HiveQL 代码. |
|
Hadoop |
Apache >=2.6.0, CDH >=5.4.0 |
>=0.5.0 |
ongoing |
Hadoop EngineConn. 支持Hadoop MR/YARN application. |
|
Python |
>=2.6 |
>=0.5.0 |
>=1.0.0_rc1 |
Python EngineConn. 支持python 代码. |
|
TiSpark |
1.1 |
>=0.5.0 |
ongoing |
TiSpark EngineConn. 支持用SparkSQL 查询TiDB. |
2、Apache Linkis 快速部署
2.1 注意事项
因为mysql-connector-java驱动是GPL2.0协议,不满足Apache开源协议关于license的政策,因此从1.0.3版本开始,提供的Apache版本官方部署包,默认是没有mysql-connector-java-x.x.x.jar的依赖包,安装部署时需要添加依赖到对应的lib包中。
Linkis1.0.3 默认已适配的引擎列表如下:
|
引擎类型 |
适配情况 |
官方安装包是否包含 |
|
Python |
1.0已适配 |
包含 |
|
Shell |
1.0已适配 |
包含 |
|
Hive |
1.0已适配 |
包含 |
|
Spark |
1.0已适配 |
包含 |
2.2 确定环境
2.2.1 依赖
|
引擎类型 |
依赖环境 |
特殊说明 |
|
Python |
Python环境 |
日志和结果集如果配置hdfs://则依赖HDFS环境 |
|
JDBC |
可以无依赖 |
日志和结果集路径如果配置hdfs://则依赖HDFS环境 |
|
Shell |
可以无依赖 |
日志和结果集路径如果配置hdfs://则依赖HDFS环境 |
|
Hive |
依赖Hadoop和Hive环境 |
|
|
Spark |
依赖Hadoop/Hive/Spark |
要求:安装Linkis需要至少3G内存。
默认每个微服务JVM堆内存为512M,可以通过修改SERVER_HEAP_SIZE来统一调整每个微服务的堆内存,如果您的服务器资源较少,我们建议修改该参数为128M。如下:
vim ${LINKIS_HOME}/deploy-config/linkis-env.sh
# java application default jvm memory.
export SERVER_HEAP_SIZE="128M"
2.2.2 环境变量
官网示例:
#JDK export JAVA_HOME=/nemo/jdk1.8.0_141 ##如果不使用Hive、Spark等引擎且不依赖Hadoop,则不需要修改以下环境变量 #HADOOP export HADOOP_HOME=/appcom/Install/hadoop export HADOOP_CONF_DIR=/appcom/config/hadoop-config #Hive export HIVE_HOME=/appcom/Install/hive export HIVE_CONF_DIR=/appcom/config/hive-config #Spark export SPARK_HOME=/appcom/Install/spark export SPARK_CONF_DIR=/appcom/config/spark-config/ export PYSPARK_ALLOW_INSECURE_GATEWAY=1 # Pyspark必须加的参数
示例:

2.3 安装包下载
https://linkis.apache.org/zh-CN/download/main

2.4 不依赖HDFS的基础配置修改
vi deploy-config/linkis-env.sh #SSH_PORT=22 #指定SSH端口,如果单机版本安装可以不配置 deployUser=hadoop #指定部署用户 LINKIS_INSTALL_HOME=/appcom/Install/Linkis # 指定安装目录 WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # 指定用户根目录,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间。 RESULT_SET_ROOT_PATH=file:///tmp/linkis # 结果集文件路径,用于存储Job的结果集文件 ENGINECONN_ROOT_PATH=/appcom/tmp #存放ECP的安装路径,需要部署用户有写权限的本地目录 ENTRANCE_CONFIG_LOG_PATH=file:///tmp/linkis/ #ENTRANCE的日志路径 ## LDAP配置,默认Linkis只支持部署用户登录,如果需要支持多用户登录可以使用LDAP,需要配置以下参数: #LDAP_URL=ldap://localhost:1389/ #LDAP_BASEDN=dc=webank,dc=com
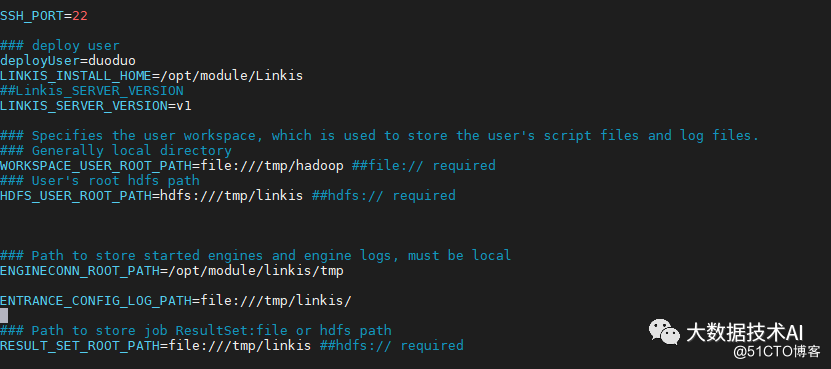
2.5 修改数据库配置
vi deploy-config/db.sh

2.6 安装
执行安装脚本:sh bin/install.sh
install.sh脚本会询问您是否需要初始化数据库并导入元数据。
因为担心用户重复执行install.sh脚本,把数据库中的用户数据清空,所以在install.sh执行时,会询问用户是否需要初始化数据库并导入元数据。

2.7 检查是否安装成功
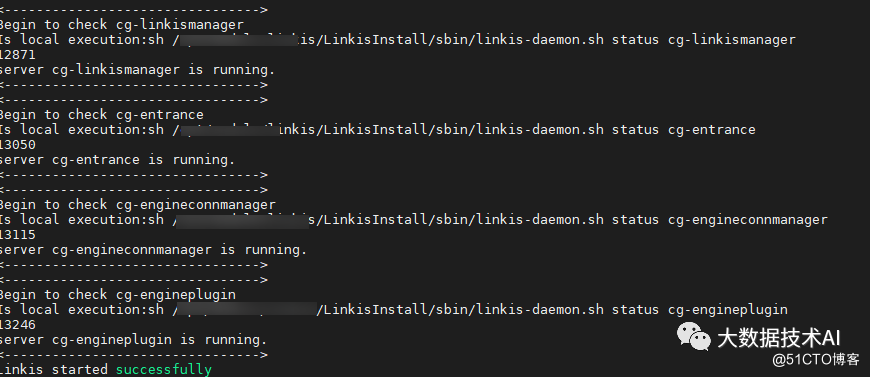
2.8 快速启动Linkis
启动服务
sh sbin/linkis-start-all.sh
查看是否启动成功
可以在Eureka界面查看服务启动成功情况,查看方法:
使用http://${EUREKA_INSTALL_IP}:${EUREKA_PORT}, 在浏览器中打开,查看服务是否注册成功。
如果您没有在config.sh指定EUREKA_INSTALL_IP和EUREKA_INSTALL_IP,则HTTP地址为:http://127.0.0.1:20303
默认会启动8个Linkis微服务,其中图下linkis-cg-engineconn服务为运行任务才会启动


2.9 问题集
1、telnet
<-----start to check used cmd----> check command fail need 'telnet' (your linux command not found) Failed to + check env
解决:sudo yum -y install telnet
2、connection exception
mkdir: Call From hadoop01/192.168.88.111 to hadoop01:9820 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused Failed to + create hdfs:///tmp/linkis directory
解决:启动HDFS
到此这篇关于Apache Linkis 中间件架构及快速安装的文章就介绍到这了,更多相关Apache Linkis 中间件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Apache Shiro 使用手册(一) Shiro架构介绍
一.什么是ShiroApache Shiro是一个强大易用的Java安全框架,提供了认证.授权.加密和会话管理等功能:认证 - 用户身份识别,常被称为用户"登录":授权 - 访问控制:密码加密 - 保护或隐藏数据防止被偷窥:会话管理 - 每用户相关的时间敏感的状态.对于任何一个应用程序,Shiro都可以提供全面的安全管理服务.并且相对于其他安全框架,Shiro要简单的多. 二.Shiro的架构介绍首先,来了解一下Shiro的三个核心组件:Subject, SecurityManager
-
使用 Apache Dubbo 实现远程通信(微服务架构)
目录 前言 1. Dubbo 基础知识 1.1 Dubbo 是什么 1.2 Dubbo 的架构图 1.3 Spring Cloud 与 Dubbo 的区别 1.4 Dubbo 的特点 1.5 Dubbo 的 6 种容错模式容错模式 1.7 主机绑定规则 2. 构建 Dubbo 服务提供方 2.1 构建服务接口模块 2.2 添加 pom.xml 依赖文件 2.3 修改 application.yml 配置文件 2.4 在主程序类上添加注解 2.5 实现 2.1 定义的接口 3. 构建 Dubbo
-
JVM上高性能数据格式库包Apache Arrow入门和架构详解(Gkatziouras)
Apache Arrow是是各种大数据工具(包括BigQuery)使用的一种流行格式,它是平面和分层数据的存储格式.它是一种加快应用程序内存密集型. 数据处理和数据科学领域中的常用库: Apache Arrow.诸如Apache Parquet,Apache Spark,pandas之类的开放源代码项目以及许多商业或封闭源代码服务都使用Arrow.它提供以下功能: 内存计算 标准化的柱状存储格式 一个IPC和RPC框架,分别用于进程和节点之间的数据交换 让我们看一看在Arrow出现之前事物是如何
-
LNAMP架构中后端Apache获取用户真实IP地址的2种方法
一.Nginx反向代理配置: 1.虚拟主机配置 复制代码 代码如下: location / { try_files $uri @apache;} location @apache {internal; proxy_pass http://127.0.0.1:8080; include proxy.conf;} location ~ .*\.(php|php5)?$ { proxy_pass http://127.0.0.1:8080; include proxy.
-
Apache Linkis 中间件架构及快速安装步骤
目录 1.ApacheLinkis介绍 2.1计算中间件概念 2.2整体架构 2.3核心特点 2.4支持的引擎类型 2.ApacheLinkis快速部署 2.1注意事项 2.2确定环境 2.2.1依赖 2.2.2环境变量 2.3安装包下载 2.4不依赖HDFS的基础配置修改 2.5修改数据库配置 2.6安装 2.7检查是否安装成功 2.8快速启动Linkis 2.9问题集 1.Apache Linkis 介绍 Linkis 在上层应用和底层引擎之间构建了一层计算中间件.通过使用Linkis 提供
-
快速安装Docker详细步骤教程
目录 一.Docker的基本组成 1.Docker服务端和客户端 客户端-服务端(C/S) : 浏览器 - 服务端(B/S) : 2.Docker的基本组成 二.Docker的在线安装 三.Docker内网环境的离线安装 四.运行第一个容器 了解Docker是如何的与众不同,如此的蒂花之秀后,我们紧接着从Docker的基础循序渐进的讲解. 一.Docker的基本组成 1.Docker服务端和客户端 在对Docker的基本组成讲解之前,我们需要明白的是Docker是一个客户端-服务端(C/S)架构
-
Apache服务器的安装步骤(图文教程)
我这次环境配置安装的是Apache-2.4.23版本! 1.首先将下载的压缩包解压到你的专门的WAMP环境文件夹,这样以后查找起来比较方便: 2.启动cmd: 如果你和我一样用的Win10,需要右键以管理员身份运行,如图,切换到Apache所在目录. httpd.exe -h 可以查看可以使用的命令. 3.使用httpd.exe -k install安装Apache.这时候会报服务器路径错误: 4.在httpd.conf文件中修改服务器路径. 5.启动Apache:httpd.exe -k st
-
docker快速安装rabbitmq的方法步骤
一.获取镜像 #指定版本,该版本包含了web控制页面 docker pull rabbitmq:management 二.运行镜像 #方式一:默认guest 用户,密码也是 guest docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 -p 5672:5672 rabbitmq:management #方式二:设置用户名和密码 docker run -d --hostname my-rabbit --name rabb
-
python快速安装OpenCV的步骤记录
前言 opencv是一款开源的跨平台的计算机视觉库,轻量级而且高效,由一系列C函数和少量C++类构成,同时提供了python.ruby.matlab等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法. 最近课设需要用到OpenCV,但是在网上查看了很多教程之后,发现安装OpenCV的速度太慢了,执行命令动不动就六个小时, 因此我开始查找资料找到一个快速安装的步骤,希望可以帮到大家,如下所示: 步骤如下 第一步:win+R,然后cmd以管理员身份进入 第二步:输入pip install o
-
Pycharm快速安装OpenCV的详细操作步骤
目录 前言 以下是几个比较全面的国内pip镜像源: 第一步 第二步 第三步 第四步 第五步 第六步 总结 前言 由于pycharm自带的pip源网站是国外网址,这就导致了许多国内用户在pycharm中下载其他软件包速度极慢,有时还会跳出下载失败的界面. 因此我们可以将pycharm中的pip源网站更换成我们国内的pip镜像源,这样下载速度就会有质的飞跃. 以下是几个比较全面的国内pip镜像源: 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:htt
-
Docker 中快速安装tensorflow环境的方法步骤
Docker 中快速安装tensorflow环境,并使用TensorFlow. 一.下载TensorFlow镜像 docker pull tensorflow/tensorflow 二. 创建TensorFlow容器 docker run --name corwien-tensortflow -it -p 8888:8888 -v /Users/kaiyiwang/Code/ai/notebooks:/notebooks/data tensorflow/tensorflow 命令说明 docke
-
Fuel快速安装OpenStack图文教程
1 介绍 1.1关于 Mirantis Mirantis,一家很牛逼的openstack服务集成商,他是社区贡献排名前5名中唯一一个靠软件和服务吃饭的公司(其他分别是Red Hat, HP, IBM, Rackspace).相对于其他几个社区发行版,Fuel的版本节奏很快,平均每两个月就能提供一个相对稳定的社区版. 1.2Fuel 是什么? Fuel 是一个为openstack 端到端"一键部署"设计的工具,其功能含盖自动的PXE方式的操作系统安装,DHCP服务,Orchestrati
-
Apache 服务器最新版下载、安装及配置教程图解(Windows版)
Apache是世界使用排名第一的Web服务器软件.它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一.它快速.可靠并且可通过简单的API扩充,将Perl/Python等解释器编译到服务器中.同时Apache音译为阿帕奇,是北美印第安人的一个部落,叫阿帕奇族,在美国的西南部.也是一个基金会的名称.一种武装直升机等等. 一.Apache的下载 1.点击链接http://httpd.apache.org/download.cgi,找到所需版本,
-
快速安装Ruby on Rails的简明指南
对于新入门的开发者,如何安装 Ruby, Ruby Gems 和 Rails 的运行环境可能会是个问题,本页主要介绍如何用一条靠谱的路子快速安装 Ruby 开发环境. 次安装方法同样适用于产品环境! 系统需求 首先确定操作系统环境,不建议在 Windows 上面搞,所以你需要用: Mac OS X 任意 Linux 发行版本(Ubuntu,CentOS, Redhat, ArchLinux ...) 强烈新手使用 Ubuntu 省掉不必要的麻烦! 以下代码区域,带有 $ 打头的表示需要在控制台(