Pandas数据清洗函数总结
目录
- 一、drop():删除指定行列
- 1. 删除指定行
- 2. 删除指定列
- 二、del():删除指定列
- 三、isnull():判断是否为缺失
- 1. 判断是否为缺失
- 2. 判断哪些列存在缺失
- 3. 统计缺失个数
- 四、notnull():判断是否不为缺失
- 五、dropna():删除缺失值
- 1. 导入数据
- 2. 删除含有NaN值的所有行
- 3. 删除含有NaN值的所有列
- 4. 删除元素都是NaN值的行
- 5. 删除元素都是NaN值的列
- 6. 删除指定列中含有缺失的行
- 六. fillna():缺失值填充
- 1. 导入数据
- 2. 默认全部填充
- 3. 用前一行的值填补空值
- 4. 用后一列的值填补空值
- 5. 设置填充个数
- 七、ffill():用前一个元素填充
- 八、bfill():用后一个元素填充
- 九、duplicated():判断序列元素是否重复
- 十、drop_duplicates():删除重复行
- 1. 判断所有列
- 2. 按照指定列进行判断
- 十一、replace():替换元素
- 1. 单个值替换
- 2. 多个值替换一个值
- 3. 多个值替换多个值
- 4. 使用正则表达式:
- 十二、str.replace():替换元素
- 十三、str.split.str():分割元素
一、drop():删除指定行列
drop()函数用于删除指定行,指定列,同时可以删除多行多列
语法格式:
DataFrame.drop(
self,
labels=None,
axis: Axis = 0,
index=None,
columns=None,
level: Level | None = None,
inplace: bool = False,
errors: str = "raise",
)
参数说明:
- labels:要删除的行列的名字,接收列表参数,列表内有多个参数时表示删除多行或者多列
- axis:要删除的轴,与labels参数配合使用。默认为0,指删除行;axis=1,删除列
- index:直接指定要删除的行
- columns:直接指定要删除的列
- inplace:是否直接在原数据上进行删除操作,默认为False(删除操作不改变原数据),而是返回一个执行删除操作后的新dataframe;inplace=True,直接在原数据上修改。
1. 删除指定行
当 axis=0 时,删除指定行
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]},index=list('abcdefgh'))
print(df_obj)
# 删除第一行
df_obj.drop(labels='a', axis=0, inplace=True)
print(df_obj)
运行结果:

2. 删除指定列
当 axis=1 时,删除指定列
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]}, index=list('abcdefgh'))
print(df_obj)
# 删除data2
df_obj.drop(labels='data2', axis=1, inplace=True)
print(df_obj)
运行结果:
二、del():删除指定列
del()函数与drop()函数相比就没有那么灵活了,此操作会对原数据df进行删除,且一次只能删除一列。
语法格式:
del df[‘列名']
案例:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]}, index=list('abcdefgh'))
print(df_obj)
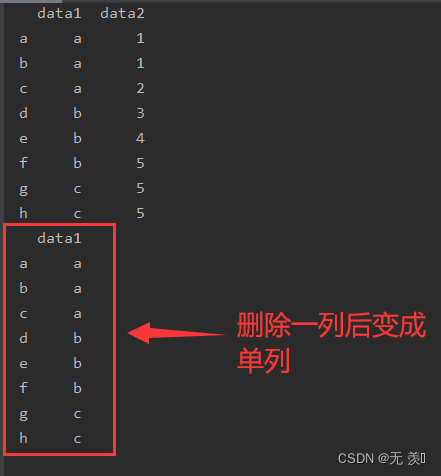
# 删除data1
del df_obj['data1']
print(df_obj)
运行结果:

三、isnull():判断是否为缺失
判断序列元素是否为缺失(返回与序列长度一样的bool值)
1. 判断是否为缺失
示例代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'b', 'b', 'c'],
'data2': [1, 2, 3, 4, 5],
'data3': np.NaN})
print(df_obj)
print(df_obj.isnull())
运行结果:

2. 判断哪些列存在缺失
isnull().any()会判断哪些”列”存在缺失值,数据清洗中经常用的小技巧
print(df_obj.isnull().any())
运行结果:

3. 统计缺失个数
isnull().sum()统计每一列的缺失个数
print(df_obj.isnull().sum())
运行结果:

四、notnull():判断是否不为缺失
判断序列元素是否不为缺失(返回与序列长度一样的bool值),用法与isnull()相似
print(df_obj.notnull())
运行结果:

五、dropna():删除缺失值
dropna()函数可以删除缺失值
语法格式:
DataFrame.dropna(
self,
axis: Axis = 0,
how: str = "any",
thresh=None,
subset=None,
inplace: bool = False,
)
参数说明:
- axis:移除行或列,默认为0,即行含有空值移除行
- how:‘all’所有值为空移除,'any’默认值,包含空值移除
- thresh:包含thresh个空值时移除
- subset:axis轴上,指定需要处理的标签名称列表
- inplace:是否替换原始数据,默认False
1. 导入数据
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', np.NaN, 'b', 'c'],
'data2': [1, 2, np.NaN, 4, 5],
'data3': np.NaN,
'data4': [1, 2, 3, 4, 5]})
print(df_obj)
运行结果:

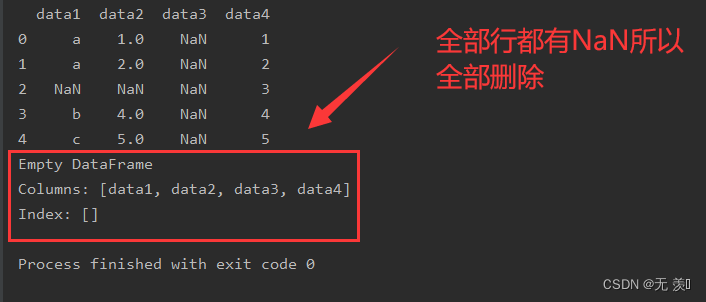
2. 删除含有NaN值的所有行
默认 axis=0
print(df_obj.dropna())
运行结果:
3. 删除含有NaN值的所有列
设置
axis=1删除列
print(df_obj.dropna(axis=1))运行结果:

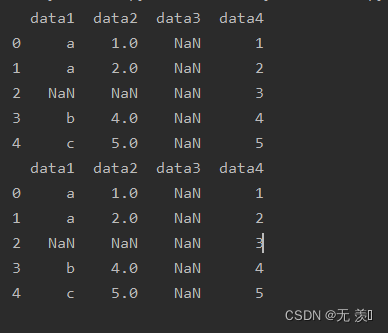
4. 删除元素都是NaN值的行
设置参数
how="all",只有行一整行数据都是NaN的时候才会删除
print(df_obj.dropna(axis=0,how="all"))
运行结果:由于所有行都有至少有一个有效值,所有都没删除
5. 删除元素都是NaN值的列
print(df_obj.dropna(axis=1,how="all"))
运行结果:

6. 删除指定列中含有缺失的行
subset参数设置指定列
# 删除data1列有含有缺失的行 print(df_obj.dropna(subset=["data1"], axis=0))
运行结果:

六. fillna():缺失值填充
缺失值填充
语法格式:
fillna(
self,
value: object | ArrayLike | None = None,
method: FillnaOptions | None = None,
axis: Axis | None = None,
inplace: bool = False,
limit=None,
downcast=None,
) -> DataFrame | None
参数说明:
- value:用于填充的空值的值。
- method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
- axis:选择轴,默认0(行),axis=1:列
- inplace:是否替换原始数据
- limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
- downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
1. 导入数据
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', np.NaN, 'b', 'c'],
'data2': [1, 2, np.NaN, 4, 5],
'data3': np.NaN,
'data4': [1, 2, 3, 4, 5]})
print(df_obj)
运行结果:
2. 默认全部填充
# 用0填补空值 print(df_obj.fillna(value=0))
运行结果:

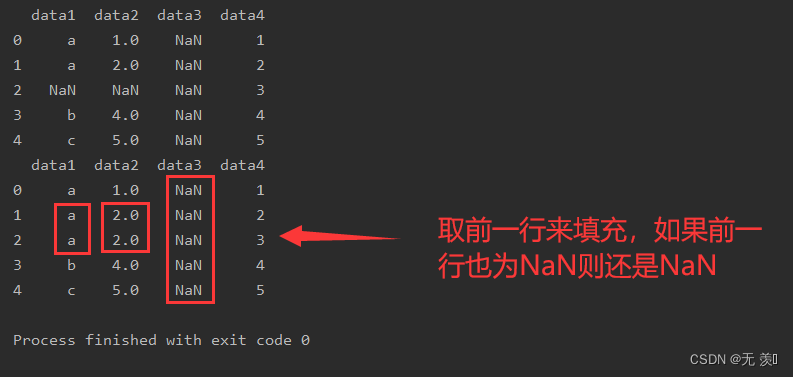
3. 用前一行的值填补空值
设置参数
method='pad'用前一行的值填补空值
# 用前一行填充 print(df_obj.fillna(method='pad',axis=0))
运行结果:
4. 用后一列的值填补空值
设置参数
method='backfill'
# 用后一列的值填补空值 print(df_obj.fillna(method='backfill', axis=1))
运行结果:

5. 设置填充个数
limit=数字,设置填充个数
# 用后一列的值填补空值,只填充两个 print(df_obj.fillna(method='backfill', axis=1, limit=2))
运行结果:

七、ffill():用前一个元素填充
前向后填充缺失值,用缺失值的前一个元素填充,与fillna()相比没有那么多可选性
语法格式:
ffill(
self: DataFrame,
axis: None | Axis = None,
inplace: bool = False,
limit: None | int = None,
downcast=None,
) -> DataFrame | None
案例说明:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.ffill())
运行结果:

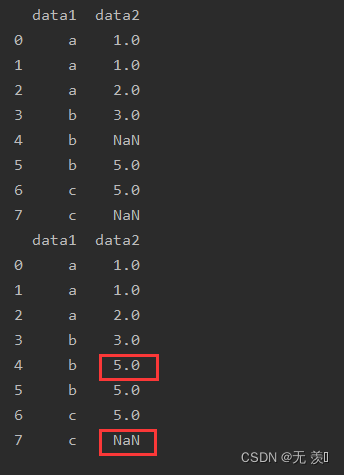
八、bfill():用后一个元素填充
后向填充缺失值,用缺失值的后一个元素填充
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.bfill())
九、duplicated():判断序列元素是否重复
判断序列元素是否重复
语法格式:
DataFrame.duplicated(subset=None,keep='first')
参数说明:
- subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
- keep:{‘first’,‘last’,False},默认’first’
- first:删除第一次出现的重复项。
- last:删除重复项,除了最后一次出现。
- false:删除所有重复项
返回布尔型Series表示每行是否为重复行
示例代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]})
print(df_obj)
print(df_obj.duplicated())
运行结果:

十、drop_duplicates():删除重复行
删除重复行,默认判断全部列,可指定按某些列判断
语法格式:
DataFrame.drop_duplicates(
self,
subset: Hashable | Sequence[Hashable] | None = None,
keep: Literal["first"] | Literal["last"] | Literal[False] = "first",
inplace: bool = False,
ignore_index: bool = False,
) -> DataFrame | None
参数说明:
- subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
- keep:{‘first’,‘last’,False},默认’first’
- first:删除第一次出现的重复项。
- last:删除重复项,除了最后一次出现。
- false:删除所有重复项
- inplace:是否替换原数据,默认是False,生成新的对象,可以复制到新的DataFrame
- ignore_index:bool,默认为False,如果为True,则生成的轴将标记为0,1,…,n-1。
1. 判断所有列
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]})
print(df_obj)
print(df_obj.drop_duplicates())
运行结果:

2. 按照指定列进行判断
print(df_obj.drop_duplicates('data2'))
运行结果:

十一、replace():替换元素
替换元素,可以使用正则表达式
语法格式:
replace(
self,
to_replace=None,
value=None,
inplace: bool = False,
limit=None,
regex: bool = False,
method: str = "pad",
)
参数说明:
- to_replace: 需要替换的值
- value:替换后的值
- inplace: 是否在原数据表上更改,默认 inplace=False
- limit:向前或向后填充的最大尺寸间隙,用于填充缺失值
- regex: 是否模糊查询,用于正则表达式查找,默认 regex=False
- method: 填充方式,用于填充缺失值
- pad: 向前填充
- ffill: 向前填充
- bfill: 向后填充
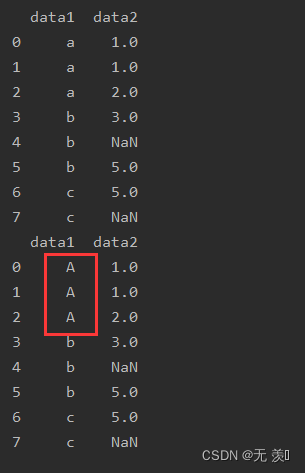
1. 单个值替换
to_replace接收字符串
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.replace('a',"A"))
运行结果:
2. 多个值替换一个值
to_replace接收列表
print(df_obj.replace([1, 2], -100))
运行结果:

3. 多个值替换多个值
to_replace接收列表,value接收列表
print(df_obj.replace([1, 2], [-100, -200]))
运行结果:

4. 使用正则表达式:
to_replace接收正则语法,设置 regex=True
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['ab', 'abc', 'aaa', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
# 替换a开头的
print(df_obj.replace('a.?',"A",regex=True))
运行结果:

十二、str.replace():替换元素
替换元素,可使用正则表达式
import numpy as np
import pandas as pd
s = pd.Series(['foo', 'fuz', np.nan])
print(s)
print(s.str.replace('f.', 'ba', regex=True))
运行结果:
十三、str.split.str():分割元素
以指定字符切割列
import numpy as np
import pandas as pd
data = {'洗漱用品':['毛巾|牙刷|牙膏']}
df = pd.DataFrame(data)
print(df)
print(df['洗漱用品'].str.split('|',expand=True))
运行结果:

到此这篇关于Pandas数据清洗函数总结的文章就介绍到这了,更多相关pandas数据清洗 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas数据清洗实现删除的项目实践
目录 准备工作(导入库.导入数据) 检测数据情况 DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 方式一:删除指定行或列 方式二:利用boolean删除满足条件元素所在的行 准备工作(导入库.导入数据) import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns sn
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-

利用pandas进行数据清洗的方法
目录 1.完整性 1.1 缺失值 1.2 空行 2.全面性 列数据的单位不统一 3.合理性 非ASCII字符 4.唯一性 4.1 一列有多个参数 4.2 重复数据 我们有下面的一个数据,利用其做简单的数据分析. 这是一家服装店统计的会员数据.最上面的一行是列坐标,最左侧一列是行坐标.列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸. 数据清洗规则总结为以下 4 个关键点
-
详解Python如何利用Pandas与NumPy进行数据清洗
目录 准备工作 DataFrame 列的删除 DataFrame 索引更改 DataFrame 数据字段整理 str 方法与 NumPy 结合清理列 apply 函数清理整个数据集 DataFrame 跳过行 DataFrame 重命名列 许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式. 因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值.不一致的格式.格式错误的记录还是无意义的异常
-
pandas数据清洗(缺失值和重复值的处理)
目录 前言 缺失值处理 缺失值的判断 缺失值统计 缺失值筛选 缺失值类型 插入缺失值 缺失值填充 插值填充 interpolate() 的具体参数 缺失值删除 缺失值删除 dropna 重复值处理 重复值查找 删除重复值 drop删除数据 数据替换replace 字符替换 缺失值替换 数字替换 数据裁剪df.clip() 前言 pandas对大数据有很多便捷的清洗用法,尤其针对缺失值和重复值.缺失值就不用说了,会影响计算,重复值有时候可能并未带来新的信息反而增加了计算量,所以有时候要进行处理.针
-
Pandas数据清洗函数总结
目录 一.drop():删除指定行列 1. 删除指定行 2. 删除指定列 二.del():删除指定列 三.isnull():判断是否为缺失 1. 判断是否为缺失 2. 判断哪些列存在缺失 3. 统计缺失个数 四.notnull():判断是否不为缺失 五.dropna():删除缺失值 1. 导入数据 2. 删除含有NaN值的所有行 3. 删除含有NaN值的所有列 4. 删除元素都是NaN值的行 5. 删除元素都是NaN值的列 6. 删除指定列中含有缺失的行 六. fillna():缺失值填充 1.
-
pandas apply 函数 实现多进程的示例讲解
前言: 在进行数据处理的时候,我们经常会用到 pandas .但是 pandas 本身好像并没有提供多进程的机制.本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行.其中,我们主要借助 joblib库,这个库为python 提供了一个非常简洁方便的多进程实现方法. 所以,本文将按照下面的安排展开,前面可能比较啰嗦,若只是想知道怎么用可直接看第三部分: - 首先简单介绍 pandas 中的分组聚合操作 groupby. - 然后简单介绍 joblib 的使用方法. - 最后,
-
对pandas replace函数的使用方法小结
语法:replace(self, to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None) 使用方法如下: import numpy as np import pandas as pd df = pd.read_csv('emp.csv') df #Series对象值替换 s = df.iloc[2]#获取行索引为2数据 #单值替换 s.replace('?',np.
-
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下. 1 import语句 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re 2 文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列名 index_col='
-
Python pandas自定义函数的使用方法示例
本文实例讲述了Python pandas自定义函数的使用方法.分享给大家供大家参考,具体如下: 自定义函数的使用 import numpy as np import pandas as pd # todo 将自定义的函数作用到dataframe的行和列 或者Serise的行上 ser1 = pd.Series(np.random.randint(-10,10,5),index=list('abcde')) df1 = pd.DataFrame(np.random.randint(-10,10,(
-
Pandas Shift函数的基础入门学习笔记
Pandas Shift函数基础 在使用Pandas的过程中,有时会遇到shift函数,今天就一起来彻底学习下.先来看看帮助文档是怎么说的: >>> import pandas >>> help(pandas.DataFrame.shift) Help on function shift in module pandas.core.frame: shift(self, periods=1, freq=None, axis=0) Shift index by desire
-
pandas使用函数批量处理数据(map、apply、applymap)
前言 在我们对DataFrame对象进行处理时候,下意识的会想到对DataFrame进行遍历,然后将处理后的值再填入DataFrame中,这样做比较繁琐,且处理大量数据时耗时较长.Pandas内置了一个可以对DataFrame批量进行函数处理的工具:map.apply和applymap. 提示:为方便快捷地解决问题,本文仅介绍函数的主要用法,并非全面介绍 一.pandas.Series.map()是什么? 把Series中的值进行逐一映射,带入进函数.字典或Series中得出的另一个值. Ser