PostgreSQL完成按月累加的操作
背景
统计某个指标,指标按照月进行累加,注意需要按省份和年份进行分组。
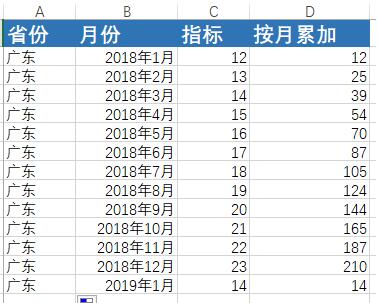
方法一、使用自关联
-- with 按月统计得到中间结果 WITH yms AS (SELECT regionid,SUM(getnum) AS getnum,SUM(dealnum) AS dealnum,to_char(qndate,'yyyy-MM') AS yearmonth FROM t_queuenumber GROUP BY regionid,to_char(qndate,'yyyy-MM') ORDER BY regionid,yearmonth)-- 查用子查询解决。 SELECT s1.regionid,s1.yearmonth, getnum,dealnum, (SELECT SUM(getnum) FROM yms s2 WHERE s2.regionid = s1.regionid AND s2.yearmonth <= s1.yearmonth AND SUBSTRING(s1.yearmonth,0,5) = SUBSTRING(s2.yearmonth,0,5) ) AS getaccumulatednum, (SELECT SUM(dealnum) FROM yms s2 WHERE s2.regionid = s1.regionid AND s2.yearmonth <= s1.yearmonth AND SUBSTRING(s1.yearmonth,0,5) = SUBSTRING(s2.yearmonth,0,5) ) AS accumulatednum FROM yms s1;
查询的结果如下:
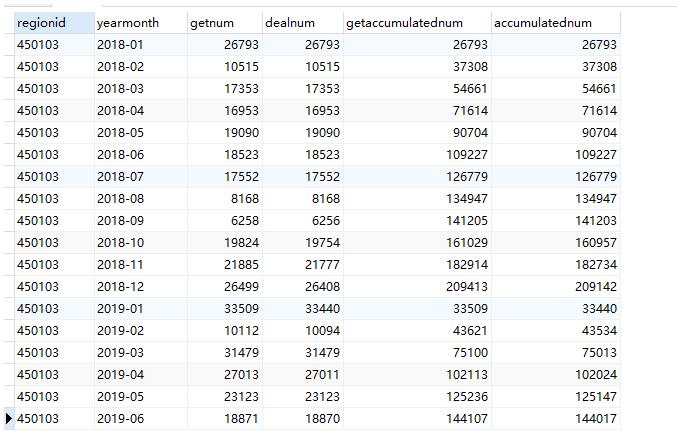
方法二、使用窗口函数
更多关于窗口函数的用法,可以参考以前的文章。窗口函数十分适合这样的场景:
WITH yms AS (SELECT regionid,SUM(getnum) AS getnum,SUM(dealnum) AS dealnum,to_char(qndate,'yyyy-MM') AS yearmonth FROM t_queuenumber GROUP BY regionid,to_char(qndate,'yyyy-MM') ORDER BY regionid,yearmonth) -- 窗口函数的使用 SELECT regionid,yearmonth, SUM(getnum) OVER(PARTITION BY regionid,SUBSTRING(yearmonth,0,5) ORDER BY yearmonth) AS getaccumulatednum, SUM(dealnum) OVER(PARTITION BY regionid ,SUBSTRING(yearmonth,0,5) ORDER BY yearmonth) AS dealaccumulatednum FROM yms;
后记
可以使用子查询、可以使用窗口函数完成上面业务场景。
补充:PostgreSQL实现按秒按分按时按日按周按月按年统计数据
提取时间(年月日时分秒):
import datetime
from dateutil.relativedelta import relativedelta
today = str(datetime.datetime.now())
print(today)
print(today[:4], today[:7], today[:10],today[:13])
print("************分隔符***************")
yesterday = (datetime.datetime.now() + datetime.timedelta(days=-1)).strftime("%Y-%m-%d %H:%M:%S")
yesterday2 = (datetime.datetime.now() + datetime.timedelta(days=-2)).strftime("%Y-%m-%d %H:%M:%S")
nextmonths = str(datetime.date.today() - relativedelta(months=-1))[:7]
lastmonths = str(datetime.date.today() - relativedelta(months=+1))[:7]
lastyears = str(datetime.date.today() - relativedelta(years=+1))[:4]
nextyears = str(datetime.date.today() - relativedelta(years=-1))[:4]
print(yesterday)
print(yesterday2)
print(nextmonths)
print(lastmonths)
print(lastyears)
print(nextyears)
结果:
2020-03-05 13:49:59.982555 2020 2020-03 2020-03-05 2020-03-05 13 ************分隔符*************** 2020-03-04 13:49:59 2020-03-03 13:49:59 2020-04 2020-02 2019 2021
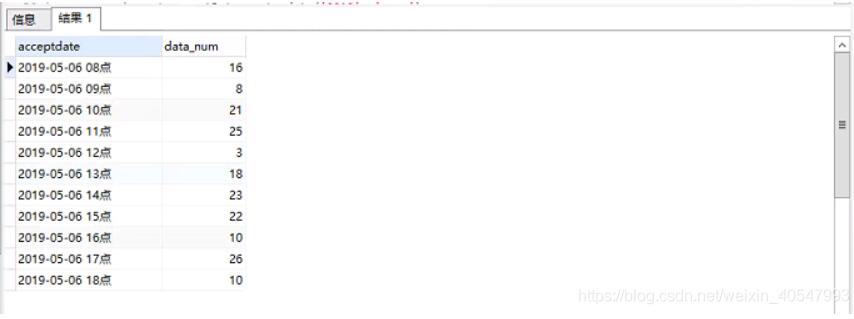
昨日每时:
select s.acceptDate, s.data_num
from (select to_char(acceptDate, 'yyyy-mm-dd hh24') || '点' as acceptDate,
count(1) as data_num
from table_name t
where t.acceptDate >= to_date('20190506', 'yyyymmdd')
and t.acceptDate < to_date('20190507', 'yyyymmdd') and organization_ = 'abcdefghijklmnopqrstuvwxyz'
group by to_char(acceptDate, 'yyyy-mm-dd hh24') || '点') s
本月每天:
select s.acceptDate, s.data_num
from (select to_char(acceptDate, 'yyyy-mm-dd') as acceptDate,
count(1) as data_num
from table_name t
where t.acceptDate >= to_date('201905', 'yyyymm')
and t.acceptDate < to_date('201906', 'yyyymm') and organization_ = 'abcdefghijklmnopqrstuvwxyz'
group by to_char(acceptDate, 'yyyy-mm-dd') ) s
本年每月:
select s.acceptDate, s.data_num
from (select to_char(acceptDate, 'yyyy-mm') as acceptDate,
count(1) as data_num
from table_name t
where t.acceptDate >= to_date('2019', 'yyyy')
and t.acceptDate < to_date('2020', 'yyyy') and organization_ = 'abcdefghijklmnopqrstuvwxyz'
group by to_char(acceptDate, 'yyyy-mm') ) s

2月-7月中每月的人数统计:
sql = """SELECT to_char(rujiaoriqi, 'yyyy-mm') as month,count(1) num
FROM jibenxx where rujiaoriqi is not null and zhongzhiriqi is null
AND to_char(rujiaoriqi,'yyyy-mm-dd')>='2020-02-01'
GROUP BY to_char(rujiaoriqi, 'yyyy-mm') order by to_char(rujiaoriqi, 'yyyy-mm') """
统计每年:
select s.acceptDate, s.data_num
from (select to_char(acceptDate, 'yyyy') as acceptDate,
count(1) as data_num
from table_name t
where t.acceptDate >= to_date('2015', 'yyyy')
and t.acceptDate < to_date('2021', 'yyyy') and organization_ = 'abcdefghijklmnopqrstuvwxyz'
group by to_char(acceptDate, 'yyyy') ) s

里面时间参数进行传参即可。
补充:
统计今天(查询当天或者指定某天数量)
select count(1) FROM "shequjz_jibenxx" where to_char(zhongzhiriqi,'yyyy-mm-dd')='2019-11-11'
最近七天每天的数量:
select s.acceptDate, s.data_num
from (select to_char(jiaozheng_jieshushijian, 'yyyy-mm-dd') as acceptDate,
count(1) as data_num
from shequjz_jibenxx t
where t.jiaozheng_jieshushijian >= to_date('2020-11-06', 'yyyy-mm-dd')
and t.jiaozheng_jieshushijian < to_date('2020-11-13', 'yyyy-mm-dd')
group by to_char(jiaozheng_jieshushijian, 'yyyy-mm-dd') ) s ORDER BY acceptDate ASC
最近七天(1天、3天、7天、一个月、一年、1h、1min、60s)的数量(总量):
# 包括今天向前推6天的总量 select count(1) from shequjz_jibenxx where jiaozheng_jieshushijian between (SELECT current_timestamp - interval '7 day') and current_timestamp # 最近一天(昨天) SELECT current_timestamp - interval '1 day' # 最近三天 SELECT current_timestamp - interval '3 day' # 最近一周 SELECT current_timestamp - interval '7 day' # 最近一个月(当前时间向前推进一个月) SELECT current_timestamp - interval '1 month' # 最近一年(当前时间向前推进一年) SELECT current_timestamp - interval '1 year' # 最近一小时(当前时间向前推一小时) SELECT current_timestamp - interval '1 hour' # 最近一分钟(当前时间向前推一分钟) SELECT current_timestamp - interval '1 min' # 最近60秒(当前时间向前推60秒) SELECT current_timestamp - interval '60 second'
最近七天中每天的累计历史总量:
步骤:
1)先统计出近7天每天的数量
2)后统计出7天前的累计历史总量
3)再对第(1)步中获取的结果进行累计求和,使用cumsum()函数
4)最后在第(3)步结果的基础上,加上7天前的累计历史总量(也就是第2步的结果)
# 趋势
def getWeekTrends(self):
try:
database = DataBase()
sql = """select s.zhongzhi_Date, s.data_num
from (select to_char(jiaozheng_jieshushijian, 'yyyy-mm-dd') as zhongzhi_Date,
count(1) as data_num
from shequjz_jibenxx t
where t.jiaozheng_jieshushijian >= to_date('{}', 'yyyy-mm-dd')
and t.jiaozheng_jieshushijian < to_date('{}', 'yyyy-mm-dd')
group by to_char(jiaozheng_jieshushijian, 'yyyy-mm-dd') ) s""".format(lastweek, today[:10])
res_df = database.queryData(sql, flag=True)
sql_total = """select count(1) FROM "shequjz_jibenxx" where rujiaoriqi is not null
and zhongzhiriqi is null and to_char(rujiaoriqi,'yyyy-mm-dd')<'{}'""".format(lastweek)
res_total = database.queryData(sql_total, count=1, flag=False) #7131
res_df['cumsum'] = res_df['data_num'].cumsum() # 累计求和
res_df['cumsum'] = res_df['cumsum'] + res_total[0]
res_df = res_df[['zhongzhi_date', 'cumsum']].to_dict(orient='records')
res = {'code': 1, 'message': '数据获取成功', 'data': res_df}
print(res)
return res
except Exception as e:
error_info = '数据获取错误:{}'.format(e)
logger.error(error_info)
res = {'code': 0, 'message': error_info}
return res
{'code': 1, 'message': '数据获取成功', 'data': [
{'zhongzhi_date': '2020-11-13', 'cumsum': 7148},
{'zhongzhi_date': '2020-11-10', 'cumsum': 7161},
{'zhongzhi_date': '2020-11-11', 'cumsum': 7195},
{'zhongzhi_date': '2020-11-12', 'cumsum': 7210},
{'zhongzhi_date': '2020-11-09', 'cumsum': 7222},
{'zhongzhi_date': '2020-11-14', 'cumsum': 7229},
{'zhongzhi_date': '2020-11-15', 'cumsum': 7238}]}
postgresql按周统计数据
(实际统计的是 上周日到周六 7天的数据):
因为外国人的习惯是一周从周日开始,二我们中国人的习惯一周的开始是星期一,这里 -1 即将显示日期从周日变成了周一,但是内部统计的数量还是从 上周日到周六进行 统计的,改变的仅仅是显示星期一的时间。
提取当前星期几: 1
SELECT EXTRACT(DOW FROM CURRENT_DATE)
提取当前日期: 2020-11-16 00:00:00
SELECT CURRENT_DATE-(EXTRACT(DOW FROM CURRENT_DATE)-1||'day')::interval diffday;
按周统计数据一:
select to_char(jiaozheng_jieshushijian::DATE-(extract(dow from "jiaozheng_jieshushijian"::TIMESTAMP)-1||'day')::interval, 'YYYY-mm-dd') date_, count(1) from shequjz_jibenxx where jiaozheng_jieshushijian BETWEEN '2020-01-01' and '2020-11-16' GROUP BY date_ order by date_
其中date_为一周中的第一天即星期一
按周统计数据二:
SELECT to_char ( cda.jiaozheng_jieshushijian, 'yyyy ' ) || EXTRACT ( WEEK FROM cda.jiaozheng_jieshushijian ) :: INTEGER AS date_, count( cda.id ) AS count, cda.jiaozheng_jieshushijian AS times FROM shequjz_jibenxx AS cda WHERE 1 = 1 AND to_char ( cda.jiaozheng_jieshushijian, 'YYYY-MM-DD HH24:MI:SS' ) BETWEEN '2020-10-01 00:00:00' AND '2020-11-12 00:00:00' GROUP BY date_, times ORDER BY date_, times DESC

postgresql中比较日期的四种方法
select * from user_info where create_date >= '2020-11-01' and create_date <= '2020-11-16'
select * from user_info where create_date between '2020-11-01' and '2020-11-16'
select * from user_info where create_date >= '2020-11-01'::timestamp and create_date < '2020-11-16'::timestamp
select * from user_info where create_date between to_date('2020-11-01','YYYY-MM-DD') and to_date('2020-11-16','YYYY-MM-DD')
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

浅谈PostgreSQL和SQLServer的一些差异
条件查询-模糊匹配 PostgreSQL和SQL Server的模糊匹配like是不一样的,PostgreSQL的like是区分大小写的,SQL Server不区分. 测试如下: //构造数据SQL create table t_user ( id integer PRIMARY KEY, name varchar(50) not null, code varchar(10) ); insert into t_user values(1,'Zhangsan','77771'); insert i
-
Postgresql 存储过程(plpgsql)两层for循环的操作
项目中遇到测试,需要造4500数据,而且需要分部门和日期,一个部门一天30条数据,剩下的铺垫数据可以一个部门一天100w左右数据,这里,每次变换部门,日期,需要操作至少300次,想到用存储过程写一个函数进行 首先,了解存储过程的语法: CREATE [ OR REPLACE ] FUNCTION name( [ [argmode] [argname]argtype[ { DEFAULT | = }default_expr] [, ...] ] ) [ RETURNSrettype | RETUR
-
解决PostgreSQL 执行超时的情况
使用背景 最近在使用PostgreSQL的时候,在执行一些数据库事务的时候,先后出现了statement timetout 和idle-in-transaction timeout的问题,导致数据库操作失败. 经研究查找,PostgreSQL有关于SQL语句执行超时和事务执行超时的相关配置,而默认超时时间是10000毫秒,即10秒钟的时间,这样会导致执行时间稍长的任务执行失败.可以通过修改PostgreSQL服务器配置文件的方式修改默认配置. 参数说明 statement_timeout sta
-
postgresql 中的几个 timeout参数 用法说明
今天整理了下 postgresql 几个 timeout 参数 select version(); version --------------------------------------------------------------------------------------------------------- PostgreSQL 10.3 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.4.7 20120313 (Red Hat
-
postgreSql分组统计数据的实现代码
1. 背景 比如气象台的气温监控,每半小时上报一条数据,有很多个地方的气温监控,这样数据表里就会有很多地方的不同时间的气温数据 2. 需求: 每次查询只查最新的气温数据按照不同的温度区间来分组查出,比如:高温有多少地方,正常有多少地方,低温有多少地方 3. 构建数据 3.1 创建表结构: -- DROP TABLE public.t_temperature CREATE TABLE public.t_temperature ( id int4 NOT NULL GENERATED ALWAYS
-
postgresql 循环函数的简单实现操作
我就废话不多说了,大家还是直接看代码吧~ create or replace function aa1(a1 integer[],a2 bigint) returns void AS $$ declare ii integer; declare num integer; begin II:=1; num = 1; FOR ii IN 1..a2 LOOP UPDATE student SET id=a1[num] WHERE cd_id = ii; num = num +1; if (num>6
-
PostgreSQL完成按月累加的操作
背景 统计某个指标,指标按照月进行累加,注意需要按省份和年份进行分组. 方法一.使用自关联 -- with 按月统计得到中间结果 WITH yms AS (SELECT regionid,SUM(getnum) AS getnum,SUM(dealnum) AS dealnum,to_char(qndate,'yyyy-MM') AS yearmonth FROM t_queuenumber GROUP BY regionid,to_char(qndate,'yyyy-MM') ORDER BY
-
postgresql插入后返回id的操作
如下所示: 补充:PostgreSQL中执行insert同时返回插入的那行数据 通过使用语句: INSERT INTO tab1 ... RETURNING *; 以上这篇postgresql插入后返回id的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Postgresql 通过出生日期获取年龄的操作
三个基础的时间表示函数 CURRENT_DATE/CURRENT_TIME/NOW() SELECT CURRENT_DATE ; 返回当前日期以 年-月-日(yyyy-MM-dd)的形式: 2019-01-10 SELECT CURRENT_TIME; 返回当日时间以 时:分:秒+时区(HH:mm:ss )的形式: 17:49:11.585308+08 SELECT NOW(); 返回当前时间 以 年-月-日 时:分:秒(yyyy-MM-dd HH:mm:ss)的形式: 2019-01-10
-
postgresql通过索引优化查询速度操作
当数据量比较大的时候,提升查询效率就是需要去考虑的事情了.一个百万级别的表格,如果不做任何优化的话,即使是最简单的查询语句执行起来也是慢的让人难以接受:当然"优化"本身是一个比较复杂的工程,从设计表.字段到查询语句的写法都有很多讲究,这里只考虑索引的方式,且是最普通的索引: 下面的操作中对应数据库表w008_execrise_info(8000数据量), w008_wf02_info(4000数据量) 1 任务表数据 SELECT w.* FROM w008_wf02_info w W
-
postgresql减少wal日志生成量的操作
1.在繁忙的系统中,如果需要降低checkpoint发生的频率,减少WAL日志的生成量,减轻对系统IO的压力,可以通过以下两种方法. 1) 调整WAL segment大小,最高可以调整到64MB,不过只能通过编译来调整.对于已有系统不太方便: 2) 增大checkpoint_segments设置,使得checkpoint不会过于频繁地被触发: 2.在9.5中,checkpoint_segments被废弃,可以通过新增参数max_wal_size来调整,该参数缺省为1GB,已经是9.4的2倍.但如
-
查询PostgreSQL占多大内存的操作
我就废话不多说了,大家还是直接看代码吧~ select pg_size_pretty(pg_relation_size('cuiyonghua.top_iqiyi_info')); select pg_size_pretty(pg_relation_size('cuiyonghua.top_mgtv_info')); select pg_size_pretty(pg_relation_size('cuiyonghua.top_tencent_info')); select pg_size_pre
-
PostgreSQL 定义返回表函数的操作
本文我们学习如何在PostgreSQL 开发返回表函数. 示例数据表 我们使用的示例数据库表为film,如下图所示: 示例1 第一个函数发挥所有满足条件film表记录,这里使用ilike操作,和like类似,但不区分大小写: CREATE OR REPLACE FUNCTION get_film (p_pattern VARCHAR) RETURNS TABLE ( film_title VARCHAR, film_release_year INT ) AS $$ BEGIN RETURN QU
-
postgresql varchar字段regexp_replace正则替换操作
1.替换目标 1).contact字段类型 varchar. 2).去掉字段中连续的两个,每个等号后面数字不同, effective_caller_id_name=051066824513,effective_caller_id_number=051066824513 2.查询原字段内容 select contact from pbx_agents where contact ~ 'effective_caller_id_name=' limit 2 "{sip_append_audio_sdp
-
PostgreSQL pg_archivecleanup与清理archivelog的操作
pg_archivecleanup 和 pg_rewind 是PG 中两个重要的功能,一个是为了清理过期的 archive log 使用的命令,另一个是你可以理解为物理级别的 wal log的搬运工. 我们先说第一个 pg_archivecleanup 命令,这个命令主要是用于使用了archive log 功能的 postgresql 但在 archive log 堆积如山的情况下,你怎么来根据某些规则,清理这些日志呢? 这里面就要使用 pg_archivecleanup 这个命令了,可以定时的
-
postgresql 利用xlog进行热备操作
一.验证postgresql增量合并的方案 结果:没有有效可行的增量合并方案,暂时放弃 二.梳理postgresql基于wal的增量备份 物理备份与还原适用于跨小版本的恢复但是不能跨平台 逻辑备份与还原备份数据适用于跨版本和跨平台的恢复 postgersql增量备份步骤 1.首先创建归档目录 例如:归档目录为/archive_pg_xlog/xlog 1>mkdir -p /archive_pg_xlog/xlog 2>chown -R postgres:postgres /archive_p