基于Python实现文章信息统计的小工具
目录
- 前言
- 程序
- 主程序 main.py
- 爬虫模块 spider.py
- 持久化模块 store.py
- 执行结果
前言
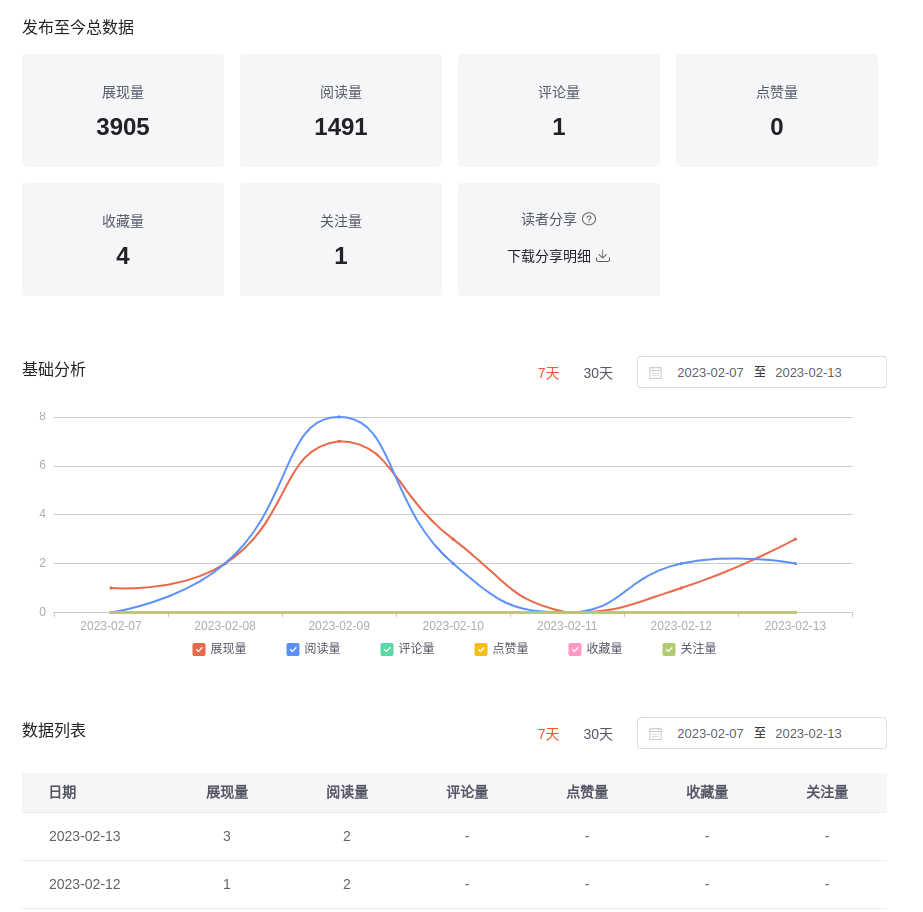
博客园在个人首页有一个简单的博客数据统计,以博客园官方的首页为例:

但是这些数据不足以分析更为细节的东西
起初我是想把博客园作为个人学习的云笔记,但在一点点的记录中,我逐渐把博客园视为知识创作和知识分享的平台
所以从年后开始,就想着做一个类似 CSDN 里统计文章数据的工具
这样的统计功能可以更好的去分析读者对于内容的需求,了解文章内容的价值,以及从侧面认识自己在知识创作方面的能力
说了不少无关的话,下面直接进入正题!
程序
这个程序是我昨天晚上一时兴起,看到了一位博主的文章 Python爬虫实战-统计博客园阅读量问题 ,对他的代码做了一些补充和修改。因为想着要更为直观的展示文章数据,所以分了几个模块去写,以方便后续增加和修改功能
程序目前只有三个 .py 文件,爬取数据后解析并写入到 txt 中(后续会使用更规范的方法做持久化处理)
主程序 main.py
from spider import spider
from store import write_data
# 设置博客名,例如我的博客地址为:https://www.cnblogs.com/KoiC,此处则填入KoiC
blog_name = 'KoiC'
if __name__ == '__main__':
post_info = spider(blog_name)
# print(post_info)
write_data(post_info, blog_name)
print('执行完毕!')
爬虫模块 spider.py
import time
import requests
import re
from lxml import etree
def spider(blog_name):
"""
爬取相关数据
"""
# 设置UA和目标博客url
headers = {
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.41"
}
url = "https://www.cnblogs.com/" + blog_name + "/default.html?page=%d"
# 测试访问
req = requests.get(url, headers)
print('测试访问状态:%d'%req.status_code)
print('开始爬取数据...')
post_info = [] # 全部博文信息
#分页爬取数据
for page_num in range(1, 999):
# 指向目标url
new_url = format(url%page_num)
# 获取页面
req = requests.get(url=new_url, headers=headers)
# print(req.status_code)
tree = etree.HTML(req.text)
# 获取目标数据(各博文名称和阅读量)
count_list = tree.xpath('//div[@class="forFlow"]/div/div[@class="postDesc"]/span[1]/text()')
title_list = tree.xpath('//div[@class="postTitle"]/a/span/text()')
# 获取该页博文数量
post_count = len(count_list)
# 如果该页没有博文,跳出循环
if post_count == 0:
break
# 解析目标数据
for i in range(post_count):
# 对数据进行处理
post_title = title_list[i].strip() # 处理前后多余的空格、换行等
post_view_count = re.findall('\d+', count_list[i]) # 正则表达式获取阅读量数据
single_post_info = [post_title, post_view_count[0]] # 单篇博文数据
post_info.append(single_post_info)
time.sleep(0.8)
return post_info
持久化模块 store.py
import os
import time
def write_data(post_info, blog_name):
"""
对数据进行持久化
"""
print('开始写入数据...')
# 获取时间
now_time = time.localtime(time.time())
select_date = time.strftime('%Y-%m-%d', now_time)
select_time = time.strftime('%Y-%m-%d %H:%M:%S ', now_time)
# 按日期创建文件路径
file_path = './{:s}/{:s}'.format(str(now_time.tm_year), str(now_time.tm_mon))
try:
os.makedirs(file_path) # 该方法创建路径时,若路径存在会报异常,使用 try catch 跳过异常
except OSError:
pass
# 写入数据
try:
fp = open('{:s}/{:s}.txt'.format(file_path, select_date), 'a+', encoding = 'utf-8')
fp.write('阅读量\t\t 博文题目\n')
view_count = 0 # 总阅读量
for single_post_info in post_info:
view_count += int(single_post_info[1])
fp.write('{:<12s}{:s}\n'.format(single_post_info[1], single_post_info[0]))
fp.write('------博客名:{:s} 博文数量:{:d} 总阅读量:{:d} 统计时间:{:s}\n\n'.format(blog_name, len(post_info), view_count, select_time))
# 关闭资源
fp.close()
except FileNotFoundError:
print('无法打开指定的文件')
except LookupError:
print('指定编码错误')
except UnicodeDecodeError:
print('读取文件时解码错误')
执行结果
程序会在目录下按日期创建文件夹
进入后可找到以日期命名的 txt 文件,以我自己的博客为例,得到以下统计信息:
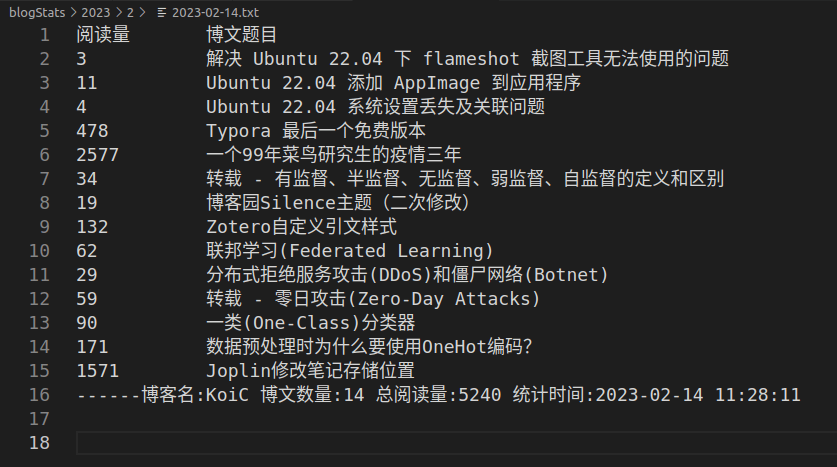
可以将程序挂在服务器上,定时统计数据,观察阅读量的涨幅。
到此这篇关于基于Python实现文章信息统计的小工具 的文章就介绍到这了,更多相关Python文章信息统计内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python读取raw binary图片并提取统计信息的实例
用python语言读取二进制图片文件,并提取非零数据统计信息(例如:max,min,skewness and kurtosis) python新手,注释较少,欢迎指教 import struct import math import numpy import scipy.stats filename = input('enter file name') f = open(filename, 'rb') f.seek(0, 0) c = 0 numOfZero = 0 s = 0 num = []
-

Python获取统计自己的qq群成员信息的方法
首先说明一下需要使用的工具以及技术:python3 + selenium selenium安装方法:pip install selenium 前提:获取自己的qq群成员信息,自己必须是群主或者管理员,然后通过管理页面进入到成员高级管理网页端,就可以对数据进行爬取了! 步骤: ①:首先安装环境 selenium库,selenium是一个自动化库,但是使用它必须用到浏览器驱动,不同的浏览器有不同的驱动,所以需自行下载,我这里是chrome浏览器. ②:运行 程序,然后会需要点击一键登录按钮,点击即
-
Python实现获取nginx服务器ip及流量统计信息功能示例
本文实例讲述了Python实现获取nginx服务器ip及流量统计信息功能.分享给大家供大家参考,具体如下: #!/usr/bin/python #coding=utf8 log_file = "/usr/local/nginx/logs/access.log" with open(log_file) as f: contexts = f.readlines() # define ip dict### ip = {} # key为ip信息,value为ip数量(若重复则只增加数量) fl
-
Python实现统计文章阅读量的方法详解
目录 前言 实现代码 效果图 前言 写这次博客其实事出有因,前几天呢,一个非常优秀的学姐在QQ空间里晒了自己的CSDN博客的总阅读量,达到了7万+,很厉害了,而且确实她的博文都是精髓,我就也想来看看我的博客总阅读量了,看看什么时候能达到人家的高度,但是博客园偏偏就没有这个功能(CSDN是可以直接在首页看的).于是乎,想尽一切办法,要来统计阅读量了,看看别人写的使用其他的统计工具,把代码放在博客园的公告栏,我也就放了个站长联盟的统计代码(具体操作可以百度,免费申请账号的),虽然,它统计的数据更多,
-
Python如何基于selenium实现自动登录博客园
这篇文章主要介绍了Python如何基于selenium实现自动登录博客园,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 需要做的准备: 本文章是使用Chrome,所以需要Chormedriver.exe,具体的下载过程可以百度查到 Selenium是一种自动化测试工具,能模拟浏览器的行为,所以今天我就模拟一下浏览器登陆博客园的行为. 首先,分析问题,登陆博客园需要做些什么: 1.打开浏览器 2.输入博客园主页的网址 3.点击登陆按钮,等待页面跳
-
使用python分析统计自己微信朋友的信息
首先,你得安装itchat,命令为pip install itchat,其余的较为简单,我不再说明,直接看注释吧. 以下的代码我在Win7+Python3.7里面调试通过 __author__ = 'Yue Qingxuan' # -*- coding: utf-8 -*- import itchat # hotReload=True可不用每次都去扫描二维码,只需要手机上确认下 itchat.auto_login(hotReload=True) # 获取好友列表 friends = itchat
-
Python实现博客快速备份的脚本分享
目录 转存文章到MD 转存图片到本地 鉴于有些小伙伴在寻找博客园迁移到个人博客的方案,本人针对博客园实现了一个自动备份脚本,可以快速将博客园中自己的文章备份成Markdown格式的独立文件,备份后的md文件可以直接放入到hexo博客中,快速生成自己的站点,而不需要自己逐篇文章迁移,提高了备份文章的效率. 首先第一步将博客园主题替换为codinglife默认主题,第二步登录到自己的博客园后台,然后选择博客备份,备份所有的随笔文章,如下所示: 备份出来以后将其命名为backup.xml,然后新建一个
-
Python爬取阿拉丁统计信息过程图解
背景 目前项目在移动端上,首推使用微信小程序.各项目的小程序访问数据有必要进行采集入库,方便后续做统计分析.虽然阿拉丁后台也提供了趋势分析等功能,但一个个的获取数据做数据分析是很痛苦的事情.通过将数据转换成sql持久化到数据库上,为后面的数据分析和展示提供了基础. 实现思路 阿拉丁产品分开放平台和统计平台两个产品线,目前开放平台有api及配套的文档.统计平台api需要收费,而且贼贵.既然没有现成的api可以获取数据,那么我们尝试一下用python抓取页面上的数据,毕竟python擅长干这种事情.
-
如何基于Python制作有道翻译小工具
这篇文章主要介绍了如何基于Python制作有道翻译小工具,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 该工具主要是利用了爬虫,爬取web有道翻译的内容. 然后利用简易GUI来可视化结果. 首先我们进入有道词典的首页,并点击翻译结果的审查元素 之后request响应网页,并分析网页,定位到翻译结果. 使用tkinter来制作一个建议的GUI 期间遇到的一个问题则是如何刷新翻译的结果,否则的话会在text里一直累加翻译结果. 于是,在mainlo
-
基于Python制作一个文件去重小工具
目录 前言 实现步骤 补充 前言 常常在下载网络素材时有很多的重复文件乱七八糟的,于是想实现一个去重的操作. 主要实现思路就是遍历出某个文件夹包括其子文件夹下面的所有文件,最后,将所有文件通过MD5函数的对比筛选出来,最后将重复的文件移除. 实现步骤 用到的第三方库都比较的常见,其中只有hashlib是用来对比文件的不是很常见.其他的都是一些比较常见的第三方库用来做辅助操作. import os # 应用文件操作 import hashlib # 文件对比操作 import logging #
-
基于Python写一个番茄钟小工具
目录 一.功能简述 二.使用到的主要模块 三.核心模块代码分析 1.番茄钟模块 2.音乐控制函数 3.main中的按钮部分 四.整体代码 一.功能简述 番茄钟即番茄工作法,番茄工作法是简单易行的时间管理工具,使用番茄工作法即一个番茄时间共30分钟,25分钟工作,5分钟休息: 特点一:番茄时长有三档 因为这个工具本人也是考虑到每个人情况不一样,不一定25分钟就适合自己,所以将番茄钟时长设为30min/45min/60min三档,自由选择 特点二:番茄统计功能 特点三:休息期间会自动播放放松音乐,当
-
Python基于tkinter模块实现的改名小工具示例
本文实例讲述了Python基于tkinter模块实现的改名小工具.分享给大家供大家参考,具体如下: #!/usr/bin/env python #coding=utf-8 # # 版权所有 2014 yao_yu # 本代码以MIT许可协议发布 # 文件名批量加.xls后缀 # 2014-04-21 创建 # import os import tkinter as tk from tkinter import ttk version = '2014-04-21' app_title = '文件名
-
Python制作一个随机抽奖小工具的实现
目录 1. 核心功能设计 2. GUI设计与实现 3. 功能实现 3.1 读取人员名单 3.2. 随机抽奖 3.3. 保存中奖名单 3.4. GUI交互逻辑 最近在工作中面向社群玩家组织了一场活动,需要进行随机抽奖,参考之前小明大佬的案例,再结合自己的需求,做了一个简单的随机抽奖小工具. 今天我就来顺便介绍一下这个小工具的制作过程吧! 先看效果: 1. 核心功能设计 针对随机抽奖的小工具,需要可以导入参与抽奖的人员名单,然后选择不同的奖励类型进行随机抽取获奖名单并导出. 那么,简单进行需求拆解,
-
基于Python实现傻瓜式GIF制作工具
目录 导语 一.简单的GIF制作 1)准备中 2)小简介 3)代码演示 二.升级imageio的GIF制作 1)准备中 2)小简介 3)代码演示 三.总效果展示 导语 嘿!大家好,我是木木子!今天给大家带来一个好玩儿的Python小程序,希望大家喜欢,记得点点关注啦~ 有没有什么内容形式,比小视频更小,比普通图片更丰富???? 有! GIF动态图就是其中一种形式,而且,必不可少. GIF动态图应该是早已充斥了互联网,被大家玩得不亦乐乎,大伙早就不能接受文章中的纯文字或 静态图片,这些早已
-
基于Python编写一个微博抽奖小程序
目录 导语 开发工具 环境搭建 先睹为快 原理简介 导语 带大家写个微博自动抽奖小程序吧,motivation和之前的B站自动抽奖小程序一样: 不想内卷了,整个B站全自动抽奖的小程序吧,万一不小心暴富了呢~ 废话不多说,让我们愉快地开始吧~ 开发工具 Python版本:3.7.8 相关模块: DecryptLogin模块: DecryptLoginExamples模块: 以及一些python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 先睹为快 首先,
-
使用Python制作一个数据预处理小工具(多种操作一键完成)
在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值.重复值等异常情况,并进行处理. 本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下 本文将分为三部分讲解: 制作GUI界面 数据处理讲解 打包与测试 主要涉及将涉及以下模块: PySimpleGUI pandas matplotlib 一.GUI界面制作 思路 老规矩,先讲思路再上代码,首先还是说一
-
基于Python实现图像文字识别OCR工具
目录 引言 功能列表 OCR部分 界面部分 软件代码 参考链接 引言 最近在技术交流群里聊到一个关于图像文字识别的需求,在工作.生活中常常会用到,比如票据.漫画.扫描件.照片的文本提取. 博主基于 PyQt + PaddleOCR 写了一个桌面端的OCR工具,用于快速实现图片中文本区域自动检测+文本自动识别. 识别效果如下图所示: 所有框选区域为OCR算法自动检测,右侧列表有每个框对应的文字内容: 点击右侧"识别结果"中的文本记录,然后点击"复制到剪贴板"即可复制该
-
基于Python实现PDF区域文本提取工具
目录 功能简介 开发代码 功能简介 打开软件后界面如下: 点击打开文件按钮打开之前的PDF文件后效果如下: 框选区域后,标题栏会自动显示当前框选的区域提取到的文字,还可以左右按钮切换: 实际我们需要提取文字的区域可能不止这一个,所以程序支持多区域框选: 完成区域框选后就可以点击保存文件,将PDF每页提取到的文本保存到一个csv文件中,当前选区的保存结果如下: 可以看到已经按框选顺序依次保存了每一个区域的字符串. 如果选择区域时发现提取结果不准确,可以撤销后重新选择: 保存图片则会将PDF的每页的