python请求域名requests.(url = 地址)报错
报错:
raise MissingSchema(
requests.exceptions.MissingSchema: Invalid URL 'titles': No scheme supplied. Perhaps you meant http://titles?
报错分析:
response = requests.get(url='url',headers=headers) # print(response) response.encoding="utf-8" rr = response.text
在爬虫教学中,这样写发起请求,看起来没啥问题吧。
但是当你执行的时候,它会报错:

报错提示:
引发缺少架构(
requests.exceptions.MissingSchema:URL“response”无效:未提供方案。也许你的意思是http://titles?
它提示啥? response 无效,架构不对,我们回去看看repsonse
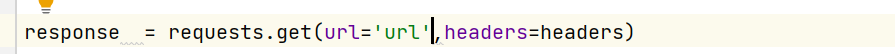
发现了没有,url = 'url' ,看起来没啥问题,其实是不对的,我在这里研究了好久,不知道哪里出错,还以为,请求的地址太多,因为我提取的是一批。
我想是用 for循环遍历是一个一个往出拿,应该没啥问题,所以问题在这里?

这个请求地址: url = url 不需要加上单引号
所以正确的写法是:
response = requests.get(url=url,headers=headers) # print(response) response.encoding="utf-8" rr = response.text
到此这篇关于python请求域名requests.(url = 地址)报错的文章就介绍到这了,更多相关python请求域名报错内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python 实现域名解析为ip的方法
今天得了一批域名,需要把域名解析成ip 因为量比较大所以采用了多进程和队列的方式 from multiprocessing import Process,Queue,Pool import socket import multiprocessing import os #写入文件 def write(q,lock,filename): while not q.empty(): url = q.get() print (url) try: ip = socket.gethostbyname(url
-
python使用urlparse分析网址中域名的方法
本文实例讲述了python使用urlparse分析网址中域名的方法.分享给大家供大家参考.具体如下: 这里给定网址,通过下面这段python代码可以很容易获取域名信息 import urlparse url = "http://www.jb51.net" domain = urlparse.urlsplit(url)[1].split(':')[0] print "The domain name of the url is: ", domain 输出结果如下: Th
-

Python批量查询域名是否被注册过
step1. 找一个单词数据库 这里有一个13万个单词的 http://download.csdn.net/detail/u011004567/9675906 新建个mysql数据库words,导入words里面就行 step2.找个查询接口 这里我用的是http://apistore.baidu.com/astore/serviceinfo/27586.html step3. 执行Python脚本 # -*- coding: utf-8 -*- ''' 域名注册查询 ''' __author_
-
Python实现获取域名所用服务器的真实IP
本来是要写个程序用的,没写完不写了,这一部分就贴出来吧 验证域名和IP class JianKong(): '''查询IDC信息,封ip和过白名单''' def __init__(self): pass @classmethod def ip_verify(cls,str): '验证IP地址规范' pattern=re.compile('(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\.(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|
-
Python实现通过解析域名获取ip地址的方法分析
本文实例讲述了Python实现通过解析域名获取ip地址的方法.分享给大家供大家参考,具体如下: 从网上查找的一些资料,特此做个笔记 案例1: def getIP(domain): myaddr = socket.getaddrinfo(domain, 'http') print(myaddr[0][4][0]) 执行函数 getIP("www.google.com") 案例2: def get_ip_list(domain): # 获取域名解析出的IP列表 ip_list = [] t
-
Python实现从url中提取域名的几种方法
从url中找到域名,首先想到的是用正则,然后寻找相应的类库.用正则解析有很多不完备的地方,url中有域名,域名后缀一直在不断增加等.通过google查到几种方法,一种是用Python中自带的模块和正则相结合来解析域名,另一种是使第三方用写好的解析模块直接解析出域名. 要解析的url 复制代码 代码如下: urls = ["http://meiwen.me/src/index.html", "http://1000chi.com/game/index.htm
-
python批量处理多DNS多域名的nslookup解析实现
利用EXCLE生成CSV文档,批量处理nslookup解析.并保存为CSV文档,方便进行查看: 输入文档格式: data\domain.csv 最终输出文档情况: data\nlookup.csv 代码: # coding=gbk import subprocess import csv def get_nslookup(domain, dns): res = subprocess.Popen("nslookup {0} {1}".format(domain, dns), stdin=
-
Vue3发送post请求出现400 Bad Request报错的解决办法
查了一下网上资料,报400一般无非就是两种: 1. Bad Request:“错误的请求" 2. Invalid Hostname:"不存在的域名” 在这里我的报错是因为前端请求头的content-type和后端不一致. 一般后端默认的内容类型是 application/x-www-form-urlencoded,而axios默认的是 applecation/json. 但是也有例外,要根据后端的注解来区分我们要转换的类型. 根据上一篇笔记上说的: @RequestBody 用 con
-
解决Python中字符串和数字拼接报错的方法
前言 众所周知Python不像JS或者PHP这种弱类型语言里在字符串连接时会自动转换类型,如果直接将字符串和数字拼接会直接报错. 如以下的代码: # coding=utf8 str = '你的分数是:' num = 82 text = str+num+'分 | 琼台博客' print text 执行结果 直接报错:TypeError: cannot concatenate 'str' and 'int' objects 解决这个方法只有提前把num转换为字符串类型,可以使用bytes函数把int
-
Python升级导致yum、pip报错的解决方法
前言 本文主要给大家介绍了因Python升级导致yum.pip报错的解放方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 原因: yum是Python写的.服务器上Python版本过低,升级为2.7,而yum/pip未升级,导致在执行yum/pip时报这个错误. yum报错: There was a problem importing one of the Python modules required to run yum. The error leading to th
-
python异常处理之try finally不报错的原因
因为有把python程序打包成exe的需求,所以,有了如下的代码 import time class LoopOver(Exception): def __init__(self, *args, **kwargs): pass class Spider: def __init__(self): super().__init__() def run(self): raise LoopOver @property def time(self): return '总共用时:{}秒'.format(se
-
Python获取apk文件URL地址实例
工作中经常需要提取apk文件的特定URL地址,如是想到用Python脚本进行自动处理.需要用到的Python基础知识如下:os.walk()函数声明:os.walk(top,topdown=True,onerror=None)(1)参数top表示需要遍历的顶级目录的路径.(2)参数topdown的默认值是"True"表示首先返回顶级目录下的文件,然后再遍历子目录中的文件.当topdown的值为"False"时,表示先遍历子目录中的文件,然后再返回顶级目录下的文件.(
-
Python使用Opencv打开笔记本电脑摄像头报错解问题及解决
目录 使用Opencv打开笔记本电脑摄像头报错 Opencv打开摄像头报错问题 使用Opencv打开笔记本电脑摄像头报错 近期要做一个下位机上发图像数据给上位机的任务,调试时自己写了一个客户端获取笔记本电脑的摄像头视频数据传输给服务器,然后服务器端显示摄像头视频数据.结果运行时发现客户端报错,视频窗口闪退. 一般获取摄像头图像数据的代码如下: capture = cv.VideoCapture(0) 但是运行会报错如下: [ WARN:0] global C:\Users\appveyor\Ap
-
Python处理JSON时的值报错及编码报错的两则解决实录
1.ValueError: Invalid control character at: line 1 column 8363 (char 8362) 使用json.loads(json_data)时,出现: ValueError: Invalid control character at: line 1 column 8363 (char 8362) 出现错误的原因是字符串中包含了回车符(\r)或者换行符(\n) 解决方法: (1)对这些字符转义: json_data = json_data.r
-
python保存大型 .mat 数据文件报错超出 IO 限制的操作
python 保存 .mat 文件的大小是有限制的,似乎是 5G 以内,如果需要保存几十个 G 的数据的话,可以选用其他方式, 比如 h5 文件 import h5py def h5_data_write(train_data, train_label, test_data, test_label, shuffled_flag): print("h5py文件正在写入磁盘...") save_path = "../save_test/" + "train_t
-
新手常见6种的python报错及解决方法
此篇文章整理新手编写代码常见的一些错误,有些错误是粗心的错误,但对于新手而已,会折腾很长时间才搞定,所以在此总结下我遇到的一些问题.希望帮助到刚入门的朋友们. 1.NameError变量名错误 报错: >>> print a Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'a' is not defined 解决方案:
-
Python使用pip安装报错:is not a supported wheel on this platform的解决方法
本文讲述了Python使用pip安装报错:is not a supported wheel on this platform的解决方法.分享给大家供大家参考,具体如下: 可能的原因1:安装的不是对应python版本的库,下载的库名中cp27代表python2.7,其它同理. 可能的原因2:这个是我遇到的情况(下载的是对应版本的库,然后仍然提示不支持当前平台) 在https://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy中,我下载到的numpy库文件名: n