关于pandas.date_range()的用法及说明
目录
- pandas.date_range()用法
- pandas.date_range()详解
- 参数
- 案例
pandas.date_range()用法
date_range()是pandas中常用的函数,用于生成一个固定频率的DatetimeIndex时间索引。
原型:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
常用参数为start、end、periods、freq。
start:指定生成时间序列的开始时间end:指定生成时间序列的结束时间periods:指定生成时间序列的数量freq:生成频率,默认‘D’,可以是’H’、‘D’、‘M’、‘5H’、‘10D’、…
还可以根据closed参数选择是否包含开始和结束时间,left包含开始时间,不包含结束时间,right与之相反。
默认同时包含开始时间和结束时间。
函数调用时至少要指定参数start、end、periods中的两个。
(1)指定起止时间
pd.date_range('20200101','20200110')

(2)指定开始时间和时间序列数量
pd.date_range('20200101',periods=10)

(3)指定结束时间和时间序列数量
pd.date_range(end='20200110',periods=10)

(4)指定开始时间、时间序列数量和频率
pd.date_range(start='20200101',periods=5,freq='2D')

(5)指定结束时间、时间序列数量和频率
pd.date_range(end='20200110',periods=5,freq='2D')

(6)指定起止时间和closed参数
pd.date_range('20200101','20200110',closed='left')

(7)时间序列做为索引,生成Series一维数组
dates = pd.date_range(start='20200101',periods=5,freq='2D') pd.Series(range(10,20,2),index=dates)
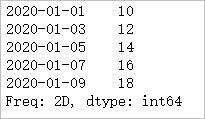
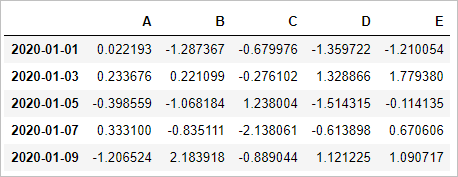
(8)时间序列做行索引,生成DateFrame二维数组
dates = pd.date_range(start='20200101',periods=5,freq='2D')
pd.DataFrame(np.random.randn(5,5), index=dates, columns=list('ABCDE'))
pandas.date_range()详解
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
返回一个固定频率的DatetimeIndex
参数
| 参数 | 数据类型 | 意义 |
|---|---|---|
| start | str or datetime-like, optional | 生成日期的左侧边界 |
| end | str or datetime-like, optional | 生成日期的右侧边界 |
| periods | integer, optional | 生成周期 |
| freq | str or DateOffset, default ‘D’ | 可以有多种比如‘5H’,频率别名参见链接 |
| tz | str or tzinfo, optional | 返回本地化的DatetimeIndex的时区名,例如’Asia/Hong_Kong’ |
| normalize | bool, default False | 生成日期之前,将开始/结束时间初始化为午夜 |
| name | str, default None | 产生的DatetimeIndex的名字 |
| closed | {None, ‘left’, ‘right’}, optional | 使区间相对于给定频率左闭合、右闭合、双向闭合(默认的None) |
| **kwargs | 为了兼容性,对结果没有影响 |
案例
>>> pd.date_range(start='1/1/2018', end='1/08/2018') DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'], dtype='datetime64[ns]', freq='D') >>> pd.date_range(start='1/1/2018', periods=8) DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'], dtype='datetime64[ns]', freq='D')
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python+pandas生成指定日期和重采样的方法
python 日期的范围.频率.重采样以及频率转换 pandas有一整套的标准时间序列频率以及用于重采样.频率推断.生成固定频率日期范围的工具. 生成指定日期范围的范围 pandas.date_range()用于生成指定长度的DatatimeIndex: 1)默认情况下,date_range会按着时间间隔为天的方式生成从给定开始到结束时间的时间戳数组: 2)如果只指定开始或结束时间,还需要periods标定时间长度. import pandas as pd pd.date_range('2017
-
Python的Pandas时序数据详解
目录 Pandas时序数据 一.python中的时间表示-datetime模块 1.换取当前时间 2.指定时间 3.运算 二. Pandas处理时序序列 1.pd.Timestamp() 2.pd.Timedelta() 3.运算 4.时间索引 总结 Pandas时序数据 前言 在数据分析中,时序数据是一类非常重要的数据.事物的发展总是伴随着时间的推移,数据也会在各个时间点上产生. 一.python中的时间表示-datetime模块 Python的标准库datetime支持创建和处理时间,P
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的
-

关于pandas.date_range()的用法及说明
目录 pandas.date_range()用法 pandas.date_range()详解 参数 案例 pandas.date_range()用法 date_range()是pandas中常用的函数,用于生成一个固定频率的DatetimeIndex时间索引. 原型: date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwarg
-
pandas.DataFrame.drop_duplicates 用法介绍
如下所示: DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据 keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除:last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有
-
解析pandas apply() 函数用法(推荐)
目录 Series.apply() apply 函数接收带有参数的函数 DataFrame.apply() apply() 计算日期相减示例 参考 理解 pandas 的函数,要对函数式编程有一定的概念和理解.函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它函数,也能作为函数的返回值. 函数作为对象能带来代码风格的巨大改变.举一个例子,有一个类型为 list 的变量,包含 从 1 到 10 的数据,需
-
Pandas之groupby( )用法笔记小结
groupby官方解释 DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs) Group series using mapper (dict or key function, apply given function to group, return result as series) or by a series of
-
Python3 pandas.concat的用法说明
前面给大家分享了pandas.merge用法详解,这节分享pandas数据合并处理的姊妹篇,pandas.concat用法详解,参考利用Python进行数据分析与pandas官网进行整理. pandas.merge参数列表如下图,其中只有objs是必须得参数,另外常用参数包括objs.axis.join.keys.ignore_index. 1.pd.concat([df1,df2,df3]), 默认axis=0,在0轴上合并. 2.pd.concat([df1,df4],axis=1)–在1轴
-
Python pandas.replace的用法详解
目录 1. pandas.replace()介绍 2. 单值替换 2.1 全局替换 2.2 选定条件替换 3. 多值替换 3.1 多个值替换同一个值 3.2 多个值替换不同值 4. 模糊查询替换 5. 缺失值替换 5.1 method的用法 (向前/后填充) 5.2 limit的用法 (限制最大填充间隔) 补充:使用实例代码 总结 1. pandas.replace()介绍 pandas.Series.replace 官方文档 Series.replace(to_replace=None, va
-
Python Pandas数据分析工具用法实例
1.介绍 Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器.它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列 2.创建DataFrame # -*- encoding=utf-8 -*- import pandas if __name__ == '__main__': pass test_stu = pandas.DataF
-
python之pandas用法大全
一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1)) df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001
-
详解pandas df.iloc[]的典型用法
与df.loc[] 根据行标或者列标获取数据不同的是df.iloc[]则根据数据的坐标(position)获取,如下图红色数字所标识: iloc[] 同样接受两个参数,分别代表行坐标,列坐标.可以接受的参数 类型为数字,数字类型的列表以及切片 下面举例说明: name score grade id a bog 45 A c jiken 67 B d bob 23 A b j
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd