R语言非线性模型的实现
什么是非线性回归
在非线性回归中,分析师通常采用一个确定的函数形式和相应的参数来拟合数据。最常用的参数估计方法是利用非线性最小二乘法(R中的nls函数)。该方法使用线性函数来逼近非线性函数,并且通过不断迭代这个过程来得到参数的最优解(本段来自维基百科)。非线性回归的良好性质之一是估计出的参数都有清晰的解释(如Michaelis-Menten模型的Vmax是指最大速率),而变换数据后得到的线性模型其参数往往难以解释。
实例一
首先,绘制出原数据的散点图。代码试下如下:
data9.3<-read.csv("C:/Users/Administrator/Desktop/data9.3.csv",head=TRUE)
attach(data9.3)
plot(x,y)
输出结果为:

可以看出,这时 y 与 x之间呈现出非线性,因此需要对数据进行非线性回归分析。
代码实现如下:
nls9.3<-nls(y~a-a/(1+(x/c)^b),start=list(a=100,b=5,c=4.8)) summary(nls9.3) e<-resid(nls9.3) ebar<-mean(e) SE<-deviance(nls9.3) # 残差平方和,由于e的均值不等于0,所以SE不等于残差的离差平方和 SSE<-sum((e-ebar)^2) # 残差的离差平方和 prey<-fitted(nls9.3) # y的预测值 pybar<-mean(prey) # y的预测值的均值 ybar<-mean(y) # y的均值 SST<-sum((y-ybar)^2) # 总离差平方和 Rsquare<-1-SE/SST # 相关指数
输出结果为:
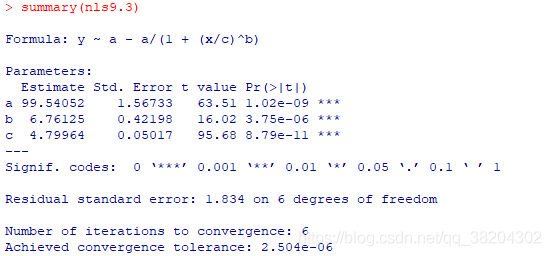

由以上输出结果可知,对参数的估计经过6步迭代计算后收敛,而且相关指数 R 2 = 0.9986,说明非线性回归拟合效果很好。同时,上述结果中对参数的显著性检验显示参数均通过显著性检验。
但是,在小样本的情况下,不可线性化的非线性回归的残差通畅不满足正态性,进而使用 t分布进行检验也是无效的,因此显著性检验的结果并不具有重要意义。
另外,听过对中间量的查看,回归的利差平方和 S S R = 15156.55 ,而总离差平方和 S S T = 14917.89<S S R ,可见非线性回归不再满足平方和分解式。
该实例中残差均值为 0.2856 ≠ 0,当然,如果回归拟合的效果好,残差均值会接近0.
通过上述分析可以认为, y与 x符合下面的非线性回归:

实例二——Gompertz模型
回归实现的代码如下:
data9.4<-read.csv("C:/Users/Administrator/Desktop/data9.4.csv",head=TRUE)
y<-data9.4[,2]
t<-data9.4[,1]
model<-nls(y~k*(a^(b^t)),start=list(a=0.5,b=0.5,k=120),lower=c(0,0,116),upper=c(1,1,10000),algorithm="port")
summary(model)
c<-coef(model) # 将模型的回归系数赋值给c
tt<-c(1:30)
yp<-c[3]*(c[1]^(c[2]^tt)) # 计算时间取值为tt时对应的y的预测值
t1=t+1979 # 计算对应的年份
t2<-tt+1979
plot(t1,y,type="o",ann=FALSE,ylim=c(0,160),xlim=c(1975,2015))
lines(t2,yp)
输出结果为:

拟合结果为:
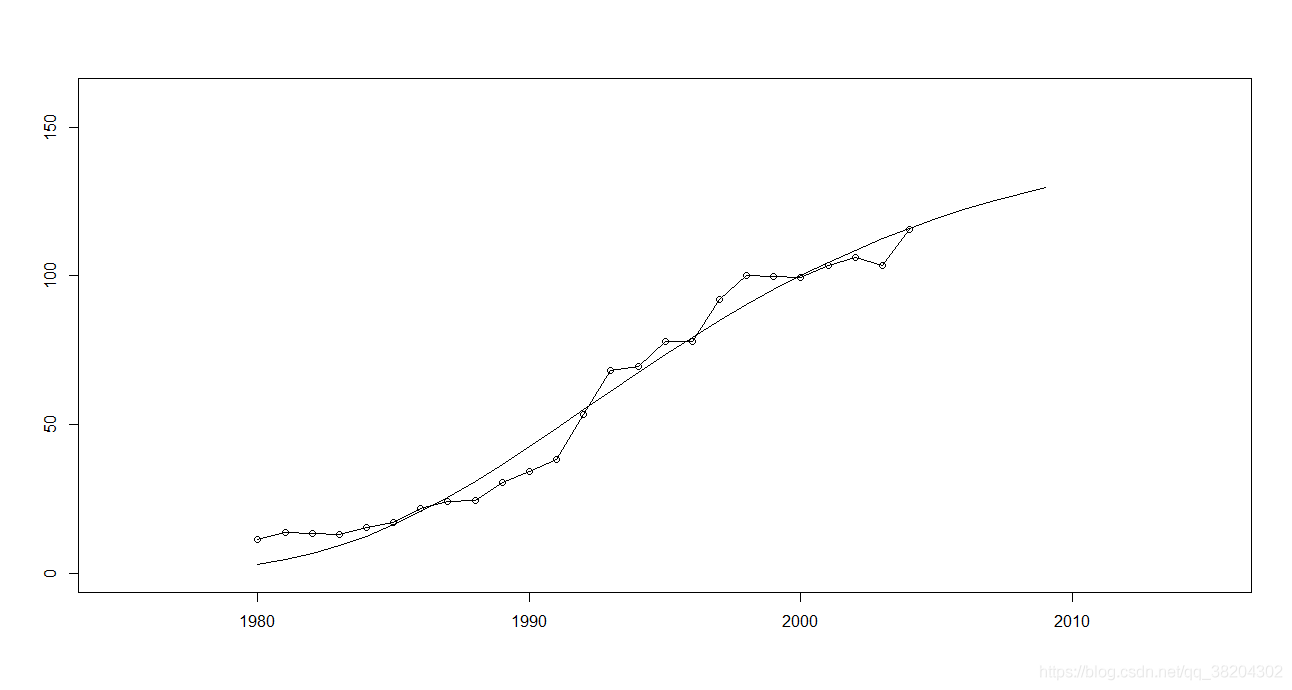
这里可以不用纠结这个模型是怎么得到的,这是一个计量经济学上的模型,已经给出了确切的表达式为 。
。
举这个例子的目的是了解由于回归迭代中的参数超过范围而导致代码运算产生无限不收敛的情况时,如何对参数取值做出限定,并使用高斯-牛顿迭代算法(设定参数algorithm=“port”)。
到此这篇关于R语言非线性模型的实现的文章就介绍到这了,更多相关R语言非线性模型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言关于非线性最小二乘的知识点实例
当模拟真实世界数据用于回归分析时,我们观察到,很少情况下,模型的方程是给出线性图的线性方程.大多数时候,真实世界数据模型的方程涉及更高程度的数学函数,如3的指数或sin函数.在这种情况下,模型的图给出了曲线而不是线.线性和非线性回归的目的是调整模型参数的值,以找到最接近您的数据的线或曲线.在找到这些值时,我们将能够以良好的精确度估计响应变量. 在最小二乘回归中,我们建立了一个回归模型,其中来自回归曲线的不同点的垂直距离的平方和被最小化.我们通常从定义的模型开始,并假设系数的一些值.然后我们应用R
-
R语言非线性模型的实现
什么是非线性回归 在非线性回归中,分析师通常采用一个确定的函数形式和相应的参数来拟合数据.最常用的参数估计方法是利用非线性最小二乘法(R中的nls函数).该方法使用线性函数来逼近非线性函数,并且通过不断迭代这个过程来得到参数的最优解(本段来自维基百科).非线性回归的良好性质之一是估计出的参数都有清晰的解释(如Michaelis-Menten模型的Vmax是指最大速率),而变换数据后得到的线性模型其参数往往难以解释. 实例一 首先,绘制出原数据的散点图.代码试下如下: data9.3<-read.
-
简述:我为什么选择Python而不是Matlab和R语言
做数据分析.科学计算等离不开工具.语言的使用,目前最流行的数据语言,无非是MATLAB,R语言,Python这三种语言,但今天小编简单总结了python语言的一些特点及平常使用的工具等. 为什么Python比MATLAB.R语言好呢? 其实,这三种语言都很多数据分析师在用,但更推荐python,主要是有以下几点: 1.python易学.易读.易维护,处理速度也比R语言要快,无需把数据库切割: 2.python势头猛,众多大公司需要,市场前景广阔:而MATLAB语言比较局限,专注于工程和科学计算方
-
Python与R语言的简要对比
数据挖掘技术日趋成熟和复杂,随着互联网发展以及大批海量数据的到来,之前传统的依靠spss.SAS等可视化工具实现数据挖掘建模已经越来越不能满足日常需求,依据美国对数据科学家(data scientist)的要求,想成为一名真正的数据科学家,编程实现算法以及编程实现建模已经是必要条件:目前很多从事数据挖掘工作的人,大多都是出身非计算机专业,本身对编程基础比较低,所以找到一门快速上手而又高效的编程语言是至关重要的,好的工具和编程语言可以起到事半功倍的效果. 目前在数据挖掘算法方面用的最多的编程语言有
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
R语言利用loess如何去除某个变量对数据的影响详解
R语言介绍 R语言是用于统计分析,图形表示和报告的编程语言和软件环境. R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建,目前由R语言开发核心团队开发. R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程. R语言允许与以C,C ++,.Net,Python或FORTRAN语言编写的过程集成以提高效率. R语言在GNU通用公共许可证下免费提供,并为各种操作系统(如Linux,Windows和Mac)提供预编译的二进制版本. R是一个在GNU
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解
R语言dplyr包的数据整理.分析函数用法文章连载NO.01 在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割.筛选.合并等实在是大快人心! 利用dplyr包中的函数更高效的数据清洗.数据分析,及为后续数据建模创造环境:本篇涉及到的函数为filter.filter_all().filter_if().filter_at().mutate.group_by.select.summarise. 1.数据筛选函数: #可使用filter()函数筛选/查找特定条件的行或者样本 #filte
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
R语言是什么 R语言简介
R是由Ross Ihaka和Robert Gentleman在1993年开发的一种编程语言,R拥有广泛的统计和图形方法目录.它包括机器学习算法.线性回归.时间序列.统计推理等.大多数R库都是用R编写的,但是对于繁重的计算任务,最好使用C.c++和Fortran代码. R不仅在学术界很受欢迎,很多大公司也使用R编程语言,包括Uber.谷歌.Airbnb.Facebook等.用R进行数据分析需要一系列步骤:编程.转换.发现.建模和交流结果 R 语言是为数学研究工作者设计的一种数学编程语言,主要用于统