Golang如何读取单行超长的文本详解
目录
- 前言:
- 1.问题复现
- 2.问题探究
- 3.问题解决
- 4.扩展
- 总结
前言:
最近在探索用Go来读取文件,读取文本时发现,对于单行超长的文本,我的Go代码无法处理。经过查阅才发现,Go提供的Scanner无法读取单行超长文本文件。我这里就来总结一下问题的发现和解决过程。
1.问题复现
首先注释main函数里面的内容,执行 CreateBigText 函数,它会创建一个含有3行内容的文件,第一行是一个长度超过100KB的行。然后解决main函数的注释,尝试执行代码,会发现只有一行错误信息:

package main
import (
"bufio"
"bytes"
"log"
"os"
"strconv"
)
func main() {
file, err := os.Open("./read/test.txt")
if err != nil {
log.Fatal(err)
}
ReadBigText(file)
}
func ReadBigText(file *os.File) {
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
println(scanner.Text())
}
// 输出错误
println(scanner.Err().Error())
}
func CreateBigText() {
file, err := os.Create("./read/test.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
data := make([]byte, 0, 32*1024)
buffer := bytes.NewBuffer(data)
// 构造一个大的单行数据
for i := 0; i < 50000; i++ {
buffer.WriteString(strconv.Itoa(i))
}
// 写入一个换行符
buffer.WriteByte('\n')
buffer.WriteString("I love you yesterday and today!\n")
buffer.WriteString("有一美人兮,见之不忘。\n")
// 将3行写入文件
file.Write(buffer.Bytes())
log.Println("创建文件成功")
}
2.问题探究
让我们来探究一下这个问题的原因,首先看一下Scan()方法的注释,这个方法就是每次扫描到下一个token,然后就可以通过获取字节或者文本的方法来获取扫描过的token。如果它返回值是false,就会返回扫描期间遇到的错误,除了io.EOF.
Scan advances the Scanner to the next token, which will then be available through the Bytes or Text method. It returns false when the scan stops, either by reaching the end of the input or an error. After Scan returns false, the Err method will return any error that occurred during scanning, except that if it was io.EOF, Err will return nil. Scan panics if the split function returns too many empty tokens without advancing the input. This is a common error mode for scanners.
所以Scan()和Text()函数是这样结合起来使用的,首先Scan()会扫描出一个token,然后Text()将其转成文本(或者其它方法转成字节),循环执行这种操作就可以按行读取一个文件。
通过阅读Scan()函数的源码,我们可以发现这样一个判断,如果buf的长度大于了最大token长度,那就会报错,见下图。
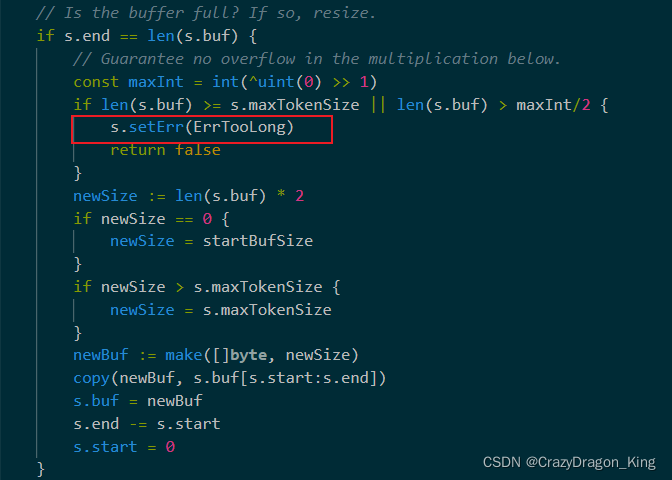
继续查找,可以看到最大长度已经定义好了,它的长度是 64*1024 byte,即64KB,所以一行文本超过了这个最大长度,那么就会报错!

3.问题解决
其实大部分情况下我们都应该使用Scan()函数结合Text()或者Bytes()函数来读取文件的,这个也是官方推荐的,因为它们是 high-level 方法,用起来很方便。但是如果我们有一些极端的情况,例如单行超过64KB,那么怎么办呢?(这种情况是很少的,但是又有可能会遇到这种需求的,例如文件里面存储了一串Base64编码)
这里可以这样来使用,这个方法不会受到64KB的限制,ReaderString方法会按照指定的定界符来读取一个完整的行,返回值是字符串和读取遇到的错误。如果想要读取返回值为字节的话,可以使用 ReadBytes 方法。
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
log.Fatal(err)
}
fmt.Printf("%d %s", len(line), line)
}
}

通过阅读源码可知,其实这个方法也是会遇到行太长的问题,只不过它忽略了这种情况。
ErrBufferFull就是这个缓冲区溢出错误。

我们继续进入内容其实也可以知道,它默认的缓冲区大小是4KB。

4.扩展
上面都说相对高层的方法,我们来看一下相对底层的方法。
ReadLine is a low-level line-reading primitive. Most callers should use ReadBytes('\n') or ReadString('\n') instead or use a Scanner.
ReadLine是读取一行,但是它是一个 low-level 方法,它会返回三个值:[]byte、isPrefix bool和err error。
其中最令人好奇的是第二个参数,它如果是true,则表示当前行没有读取完毕,但是缓冲区满了,可以看下面这段注释。
If the line was too long for the buffer then isPrefix is set and the beginning of the line is returned. The rest of the line will be returned from future calls.
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
bline, isPrefix, err := reader.ReadLine()
if err == io.EOF {
break // 读取到文件结束才退出
}
// 读取到超长行,即单行超过4k字节,直接写入文件,不对此行做处理
if isPrefix {
fmt.Print(string(bline))
continue
}
fmt.Println(string(bline))
}
}
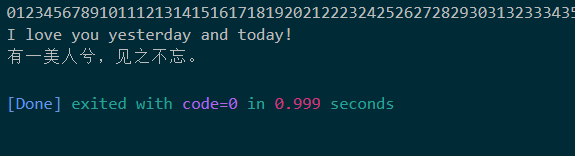
不过需要注意这个方法读取出来的数据是不包括换行符的,所以我是用的println打印输出的。
如果你也去看了 ReadString、ReadBytes 和 ReadLine 方法,会发现两种都依赖于一个底层的方法——ReadSlice方法。这个方法很原始,一般不会直接使用它。如果它遇到了超长行,它就会直接返回读取到的字节和一个ErrBufferFull,那这样我们就可以根据这个错误来继续读取数据了。这种方式还是相对麻烦了一些,不过如果你可以理解的话,对于上面的方法也就不是问题了。学习嘛,还是有必要一探究竟的。不过阅读源码感觉有些还是理解起来很困难,特别是这些英语注释,不过也能看一个七七八八了。还不行的话,那就再借助一些翻译软件,不过我个人觉得提高自己的英语能力还是非常必要的。
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
byt, err := reader.ReadSlice('\n')
if err != nil {
if err == bufio.ErrBufferFull {
fmt.Print(string(byt))
continue
}
log.Fatal(err)
}
fmt.Print(string(byt))
}
}

总结
到此这篇关于Golang如何读取单行超长的文本的文章就介绍到这了,更多相关Golang读取超长文本内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Golang如何读取单行超长的文本详解
目录 前言: 1.问题复现 2.问题探究 3.问题解决 4.扩展 总结 前言: 最近在探索用Go来读取文件,读取文本时发现,对于单行超长的文本,我的Go代码无法处理.经过查阅才发现,Go提供的Scanner无法读取单行超长文本文件.我这里就来总结一下问题的发现和解决过程. 1.问题复现 首先注释main函数里面的内容,执行 CreateBigText 函数,它会创建一个含有3行内容的文件,第一行是一个长度超过100KB的行.然后解决main函数的注释,尝试执行代码,会发现只有一行错误信息: pa
-
Golang实现简单http服务器的示例详解
目录 一.基本描述 二 .具体方法 2.1 连接的建立 2.2 http请求解析 2.3 http请求处理 2.4 http请求响应 三.完整示例 一.基本描述 完成一个http请求的处理和响应,主要有以下几个步骤: 监听端口 建立连接 解析http请求 处理请求 返回http响应 完成上面几个步骤,便能够实现一个简单的http服务器,完成对基本的http请求的处理 二 .具体方法 2.1 连接的建立 go中net包下有提供Listen和Accept两个方法,可以完成连接的建立,可以简单看下示例
-
Golang配置解析神器go viper使用详解
目录 前言 viper简介 功能 viper配置优先级 安装viper 支持哪些文件格式 key大小写问题 使用指南 如何访问viper的功能 配置默认值 读取配置文件 写配置文件 WriteConfig SafeWriteConfig WriteConfigAs SafeWriteConfigAs 监听配置文件 从io.Reader读取配置 显示设置配置项 注册和使用别名 读取环境变量 与命令行参数搭配使用 pflag 扩展其他flag 远程key/value存储支持 访问配置 直接访问 序列
-
Golang中的错误处理的示例详解
目录 1.panic 2.包装错误 3.错误类型判断 4.错误值判断 1.panic 当我们执行panic的时候会结束下面的流程: package main import "fmt" func main() { fmt.Println("hello") panic("stop") fmt.Println("world") } 输出: go run 9.go hellopanic: stop 但是panic也是可以捕获的,我们可
-
Golang拾遗之实现一个不可复制类型详解
目录 如何复制一个对象 为什么要禁止复制 运行时检测实现禁止复制 初步尝试 更好的实现 性能 优点和缺点 静态检测实现禁止复制 利用Locker接口不可复制实现静态检测 优点和缺点 更进一步 利用package和interface进行封装 优点和缺点 总结 如何复制一个对象 不考虑IDE提供的代码分析和go vet之类的静态分析工具,golang里几乎所有的类型都能被复制. // 基本标量类型和指针 var i int = 1 iCopy := i str := "string" st
-
Java 读取外部资源的方法详解及实例代码
Java 读取外部资源的方法详解 在Java代码中经常有读取外部资源的要求:如配置文件等等,通常会把配置文件放在classpath下或者在web项目中放在web-inf下. 1.从当前的工作目录中读取: try { BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream("wkdir.txt"))); String str; while ((str = in.readLine())
-
Android读取properties配置文件的实例详解
Android读取properties配置文件的实例详解 因为一些配置信息,多处用到的.且以后可能变更的,我想写个.prorperties配置文件给管理起来. 我把配置文件放在了assets文件夹下 appConfig.properties: serverUrl=http://192.168.1.155 import java.io.InputStream; import java.util.Properties; import android.content.Context; /** * 读取
-
对python pandas读取剪贴板内容的方法详解
我使用的Python3.5,32版本win764位系统,pandas0.19版本,使用df=pd.read_clipboard()的时候读不到数据,百度查找解决方法,找到了一个比较靠谱的 打开site-packages\pandas\io\clipboard.py 在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8') 保存,然后就可以使用了 df=pd.read_clipboard() #变成正常的了 下次可以在其他地方复
-
对pandas写入读取h5文件的方法详解
1.引言 通过参考相关博客对hdf5格式简要介绍. hdf5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的. 使用压缩可以提磁盘利用率,节省空间. 开启压缩也没有什么劣势,只会慢一点点. 压缩在小数据量的时候优势不明显,数据量大了才有优势. 同时发现hdf读取文件的时候只能是一次写,写的时候可以append,可以put,但是写完成了之后关闭文件,就不能再写了, 会覆盖. 另外,为什么单独说pandas,主要因为本人目前对于h5py这个包的理解不是很深入,不
-
对python读取CT医学图像的实例详解
需要安装OpenCV和SimpleItk. SimpleItk比较简单,直接pip install SimpleItk即可. 代码如下: #coding:utf-8 import SimpleITK as sitk import cv2 #LKDS-00058,-102.655469971,108.188810974,438.759994507,12.2279986879 if __name__ == '__main__': filename = "F:/cancer_solution/data