浅谈Python数据处理csv的应用小结
目录
- 题目
- 代码
- 运行实例
题目
文件scores.csv包含十位学生的成绩单,表头是"姓名 语文 数学 英语"。请编程完成下述功能。
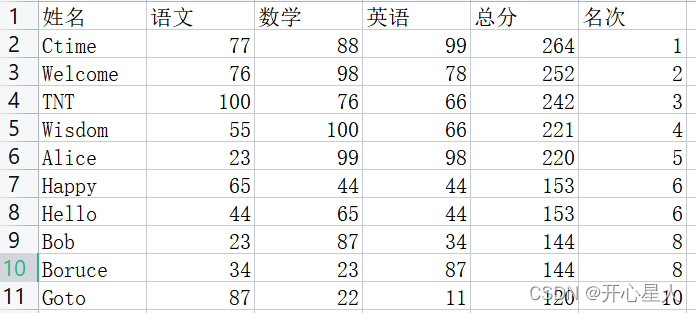
1)计算每位学生的总分与排名,并将扩充后的学生信息写入文件data.csv中,新文件表头是"姓名 语文 数学 英语 总分 名次";
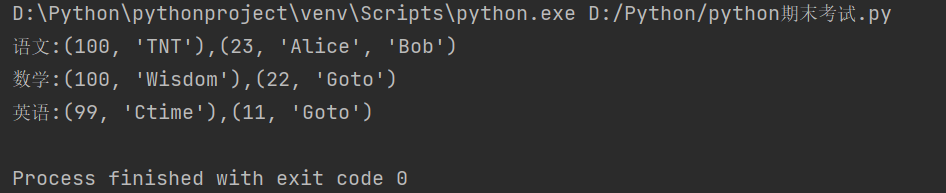
2)同时,在控制台上分行输出各门课的最高分与最低分以及对应的学生姓名,输出格式为"课程名 :(最高分,学生1,… ,学生n),(最低分,学生1,… ,学生n)";
3)如果总分相同,则同一名次下可能有多人并列,如果最高分或最低分有多人相同,则将这么多人按字母序先后写在同一个元组中。
代码
fr=open("scores.csv","r")
fw=open("data.csv","w")
ls=[]
for line in fr:
line=line.replace("\n","")
ls.append(line.split(","))
ChMax=[0,'']
ChMin=[100,'']
MaMax=[0,'']
MaMin=[100,'']
EnMax=[0,'']
EnMin=[100,'']
#当函数有list或者 dictionary 作为形参时,会改变其实参的值(在函数中若改动其值)
#但是若不想实参的值收到影响,在传参的时候可以使用[].copy方法。list和dictionary都有copy方法。
# def updateMaxMin(Max,Min,score,i):
# if(score>Max[0]):
# Max=[0,'']
# Max[0]=score
# Max[1]=ls[i][0]
# elif(score==Max[0]):
# Max.append(ls[i][0])
# if(score<Min[0]):
# Min=[100,'']
# Min[0]=score
# Min[1]=ls[i][0]
# elif(score==Min[0]):
# Min.append(ls[i][0])
for i in range(1,len(ls)):
sum=eval(ls[i][1])+eval(ls[i][2])+eval(ls[i][3])
#将总分列添加到二维列表中
ls[i].append(sum)
# updateMaxMin(Max=ChMax,Min=ChMin,score=eval(ls[i][1]),i=i)
# updateMaxMin(Max=MaMax,Min=MaMin,score=eval(ls[i][2]),i=i)
# updateMaxMin(Max=EnMax,Min=EnMin,score=eval(ls[i][3]),i=i)
#语文最高分最低分更新
chScore=eval(ls[i][1])
if (chScore > ChMax[0]):
ChMax = [0, '']
ChMax[0] = chScore
ChMax[1] = ls[i][0]
elif (chScore == ChMax[0]):
ChMax.append(ls[i][0])
if (chScore < ChMin[0]):
ChMin = [100, '']
ChMin[0] = chScore
ChMin[1] = ls[i][0]
elif (chScore == ChMin[0]):
ChMin.append(ls[i][0])
#数学最高分最低分更新
maScore=eval(ls[i][2])
if (maScore > MaMax[0]):
MaMax = [0, '']
MaMax[0] = maScore
MaMax[1] = ls[i][0]
elif (maScore == MaMax[0]):
MaMax.append(ls[i][0])
if (maScore < MaMin[0]):
MaMin = [100, '']
MaMin[0] = maScore
MaMin[1] = ls[i][0]
elif (maScore == MaMin[0]):
MaMin.append(ls[i][0])
#英语最高分最低分更新
enScore=eval(ls[i][3])
if (enScore > EnMax[0]):
EnMax = [0, '']
EnMax[0] = enScore
EnMax[1] = ls[i][0]
elif (enScore == EnMax[0]):
EnMax.append(ls[i][0])
if (enScore < EnMin[0]):
EnMin = [100, '']
EnMin[0] = enScore
EnMin[1] = ls[i][0]
elif (enScore == EnMin[0]):
EnMin.append(ls[i][0])
#将二维列表中每一行按照总分从大到小排序
#这里我用的是冒泡排序
for i in range(1,len(ls)):
for j in range(i+1,len(ls)):
if ls[i][4]<ls[j][4]:
ls[i],ls[j]=ls[j],ls[i]
#将名次列添加到二维列表中
ls[1].append(1)
count=2
for i in range(2,len(ls)):
if ls[i][4]==ls[i-1][4]:
ls[i].append(ls[i-1][5])
else:
ls[i].append(count)
count+=1
print("语文:{0},{1}".format(tuple(ChMax),tuple(ChMin)))
print("数学:{},{}".format(tuple(MaMax),tuple(MaMin)))
print("英语:{},{}".format(tuple(EnMax),tuple(EnMin)))
#将表中数据全部转换成字符串
for i in range(len(ls)):
for j in range(len(ls[i])):
ls[i][j]=str(ls[i][j])
#扩充表头
ls[0].append("总分")
ls[0].append("名次")
#写入data.csv
for row in ls:
fw.write(",".join(row)+"\n")
fr.close()
fw.close()
这段代码是可以正常运行的,但是更新最大最小成绩,我想把它分装成一个函数,但是运行失败了,代码我注释掉了,如果大家能看出来哪里错了的话,希望能告诉我一样。这里我只是用了最笨的方法
运行实例
scores.csv
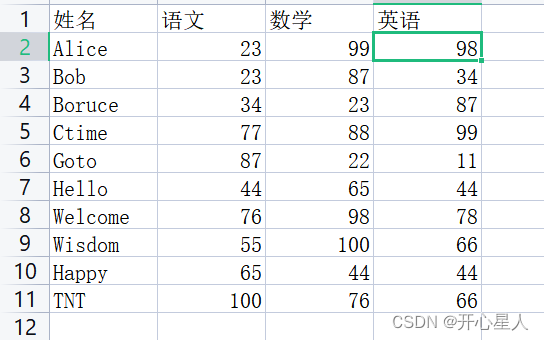
data.csv
控制台
到此这篇关于Python数据处理csv的简单应用的文章就介绍到这了,更多相关Python数据处理csv内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python处理csv数据动态显示曲线实例代码
本文研究的主要是python处理csv数据动态显示曲线,分享了实现代码,具体如下. 代码: # -*- coding: utf-8 -*- """ Spyder Editor This temporary script file is located here: C:\Users\user\.spyder2\.temp.py """ """ Show how to modify the coordinate form
-
python处理csv数据的方法
本文实例讲述了python处理csv数据的方法.分享给大家供大家参考.具体如下: Python代码: 复制代码 代码如下: #coding=utf-8 __author__ = 'dehua.li' from datetime import * import datetime import csv import sys import time import string import os import os.path import pylab as plt rootdir='/nethome/
-
python数据处理之如何选取csv文件中某几行的数据
前言 有些人看到这个问题觉得不是问题,是嘛,不就是df.col[]函数嘛,其实忽略了一个重点,那就是我们要省去把csv文件全部读取这个过程,因为如果在面临亿万级别的大规模数据,得到的结果就是boom,boom,boom. 我们要使用一下现成的函数里面的参数nrows,和skiprows,一个代表你要读几行,一个代表你从哪开始读,这就可以了,比如从第3行读取4个 示例代码 import pandas as pd df = pd.DataFrame({'a':[1,2,3,4,5,6,7,8,9],
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-

浅谈Python数据处理csv的应用小结
目录 题目 代码 运行实例 题目 文件scores.csv包含十位学生的成绩单,表头是"姓名 语文 数学 英语".请编程完成下述功能.1)计算每位学生的总分与排名,并将扩充后的学生信息写入文件data.csv中,新文件表头是"姓名 语文 数学 英语 总分 名次";2)同时,在控制台上分行输出各门课的最高分与最低分以及对应的学生姓名,输出格式为"课程名 :(最高分,学生1,… ,学生n),(最低分,学生1,… ,学生n)";3)如果总分相同,则同一
-
浅谈Python基础之I/O模型
一.I/O模型 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口. 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别? 这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blockin
-
浅谈Python中函数的定义及其调用方法
一.函数的定义及其应用 所谓函数,就是把具有独立功能的代码块组织成为一个小模块,在需要的时候调用函数的使用包含两个步骤 1.定义函数–封装独立的功能 2.调用函数–享受封装的成果 函数的作用:在开发时,使用函数可以提高编写的效率以及代码的重用'' 函数: 函数是带名字的代码块,用于完成具体的工作 需要在程序中多次执行同一项任务时,你无需反复编写完成该任务的代码,而只需调用该任务的函数,让python运行其中的代码,你将发现,通过使用函数,程序编写,阅读,测试和修复都将更容易 1.定义函数 def
-
浅谈Python中os模块及shutil模块的常规操作
如下所示: #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表.这个列表以字母顺序. 它不包括 '.' 和'..' 即使它在文件夹中. #只支持在 Unix, Windows 下使用 import os, sys # 打开文件 path=r'C:\Users\Administrator.SKY-20180518VHY\Desktop\rx\ore' dirs = os.listdir( path ) print(dirs) # 输出所有文件和文件夹 for fil
-
浅谈Python xlwings 读取Excel文件的正确姿势
使用Python加载最新的Excel读取类库xlwings可以说是Excel数据处理的利器,但使用起来还是有一些注意事项,否则高大上的Python会跑的比老旧的VBA还要慢. 这里我们对比一下,用几种不同的方法,从一个Excel表格中读取一万行数据,然后计算结果,看看他们的耗时. 1. 处理要求: 一个Excel表格中包含了3万条记录,其中B,C两个列记录了某些计算值,读取前一万行记录,将这两个列的差值进行计算,然后汇总得出差的和. 文件是这个样子:Book300s.xlsx . 2. 处理方式
-
浅谈Python numpy创建空数组的问题
一.问题描述: 有一个shape为(308, 2)的二维数组,以及单独的一个数字,需要保存到csv文件中,这个单独的数字让其保存到第3列第一行的位置. 二.具体的实现: 首先要想把一个(308, 2)的二维数组和一个数字给拼接起来,直接拼接没办法实现,因为行数和列数都不同的两个ndarry是无法拼接的(此处按照目前我学的理解,是无法直接拼接的,如果可以的话,麻烦评论一下). 然后我首先想到的解决方法就是先建一个(308,1)的二维数组,然后令这个二维数组的第一个元素设置成那个数字,然后进行拼接,
-
浅谈Python响应式类库RxPy
一.基本概念 Reactive X中有几个核心的概念,先来简单介绍一下. 1.1.Observable和Observer(可观察对象和观察者) 首先是Observable和Observer,它们分别是可观察对象和观察者.Observable可以理解为一个异步的数据源,会发送一系列的值.Observer则类似于消费者,需要先订阅Observable,然后才可以接收到其发射的值.可以说这组概念是设计模式中的观察者模式和生产者-消费者模式的综合体. 1.2.Operator(操作符) 另外一个非常重要
-
浅谈Python数学建模之线性规划
目录 一.求解方法.算法和编程方案 1.1.线性规划问题的求解方法 1.2.线性规划的最快算法 1.3.选择适合自己的编程方案 二.PuLP库求解线性规划问题 2.1.线性规划问题的描述 2.2.PuLP 求解线性规划问题的步骤 2.3.Python例程:线性规划问题 三.小结 一.求解方法.算法和编程方案 线性规划 (Linear Programming,LP) 是很多数模培训讲的第一个算法,算法很简单,思想很深刻. 线性规划问题是中学数学的内容,鸡兔同笼就是一个线性规划问题.数学规划的题目在
-
浅谈Python数学建模之数据导入
目录 一.数据导入是所有数模编程的第一步 二.在程序中直接向变量赋值 2.1.为什么直接赋值? 2.2.直接赋值的问题与注意事项 三.Pandas 导入数据 3.1.Pandas 读取 Excel 文件 3.2.Pandas 读取 csv 文件 3.3.Pandas 读取文本文件 3.4.Pandas 读取其它文件格式 四.数据导入例程 一.数据导入是所有数模编程的第一步 编程求解一个数模问题,问题总会涉及一些数据. 有些数据是在题目的文字描述中给出的,有些数据是通过题目的附件文件下载或指定网址
-
浅谈Python中的正则表达式
Python里的正则表达式 Python里的正则表达式,无需下载外部模块,只需要引入自带模块:re: import re 官方re模块文档: https://docs.python.org/zh-cn/3.9/library/re.html 同时,Python的正则表达式是PCRE标准的,相较于广泛应用在Unix上的POSIX标准,还是有些区别的(主要是简化) 基本方法 观察re源码,其主要的接口方法有: match(-):从字符串的起始位置匹配一个模式,如果无法匹配成功,则match()就返回