java内存异常使用导致full gc频繁
目录
- 问题系统
- 现象
- 排查过程
- 分析dump
- 排查原因
- 排查差异:
- 解决问题
- 根本原因
- 问题总结
- 问题根本原因
问题系统
日常巡检发现,应用线上出现频繁full gc
现象
应用线上出现频繁full gc
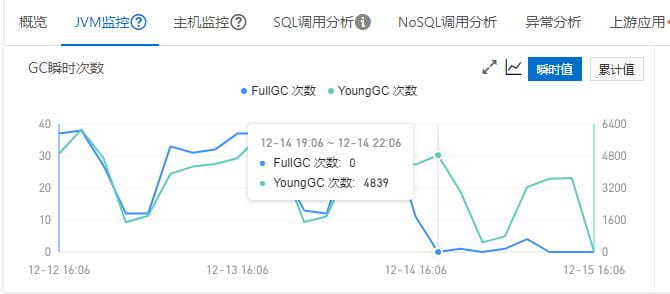
排查过程
分析dump
拉dump文件:小插曲:dump时如果指定:live,则在dump前jvm会先进行一次full gc,并且gc log里会打印dump full gc,这种对非内存泄漏导致的线上异常内存情况排查反而会带来不便,导致我们多dump了好几次。
分析dump文件:
a. 发现大量long[]数组占用最大空间,有异常情况

b. 查看gc根节点,发现这些long[]数据大部分是被org.HdrHistogram.Histogram持有,每个Histogram对象会持有一个2048size的long[]
c. 查看Histogram实例的数量,竟然有5w个,对比下正常项目的堆栈,大约是100倍

d. 这里又有一个插曲,一开始习惯用mat分析,但是mat生成的报告对分析泄露比较有用,对于分析异常的内存没有jvisualvm.exe和idea的profiler好用
排查原因
本地启动,可以复现这个类的内存使用情况,于是本地起一个其他内存正常的服务与有问题的应用,分析内存对比
这里用的是idea的profiler,很方便
发现差异:
对比正常的应用,发现异常应用的引用存在异常的来自

● rx.internal.operators.OnSubscribeReduceSeed$ReduceSeedSubscriber的引用,怀疑就是这个异常引用就是导致这些实例无法在新生代回收而是堆积到了老年代触发full gc的原因
排查差异:
简单看了下相关代码,看不出个所以然,直接debug对比
系统确实走进了相关的代码,增加了对Histogram的引用,而正常应用没有
但是光这样也看不出来为什么,此时关注到了左下角的线程池,这个线程池比较奇怪,是Metric的线程池
Metric是Hystrix用来统计相关指标,来供自己的dashboard或者用户来获取,以此来了解系统熔断相关参数和指标的功能
再看堆栈,走到这里的逻辑是

这个流用来统计单位时间内的系统指标,导致Hystrix使用Histogram的long数组实现类似滑动窗口的效果统计单位时间内的指标
Histogram本身是Hystrix用来实现类似桶+滑动窗口的功能,来统计单位时间内的流量,但是因为开启了指标参数,导致hystrix为了统计更长时间范围内的指标,新增了对象持有更多(单位时间内)的Histogram引用来聚合,这部分引用因为是统计更长时间范围周期的,就会因为引用持有时间长而到老年代,但是本质并不是内存泄漏,所以每次full gc后又可以得到回收
解决问题
看到上面的差异和怪异的线程池,第一反应就是关闭metric使应用不走到这段逻辑中增加引用,看官方文档,该配置默认是打开的,并且确认该功能只影响指标统计不影响断路器本身功能,使用配置hystrix.metrics.enabled=false配置来关闭
新增配置后,验证并查看堆栈,引用恢复正常,并且系统在一段时间后并没有新增更多的Histogram实例,发布线上后观察一段时间,full gc问题确实得到解决
根本原因
在当时发现解决的办法并验证后,并没有时间去研究hystrix.metrics.enabled默认配置就是true但是其他应用没有出现这个full gc问题的原因, 先解决了之后后续再继续跟进排查根本原因防止其他项目也出现相同问题
之前发现可疑的线程池是HystrixMetricsPoller ,经过查看,该线程池由HystrixMetricsPollerConfiguration
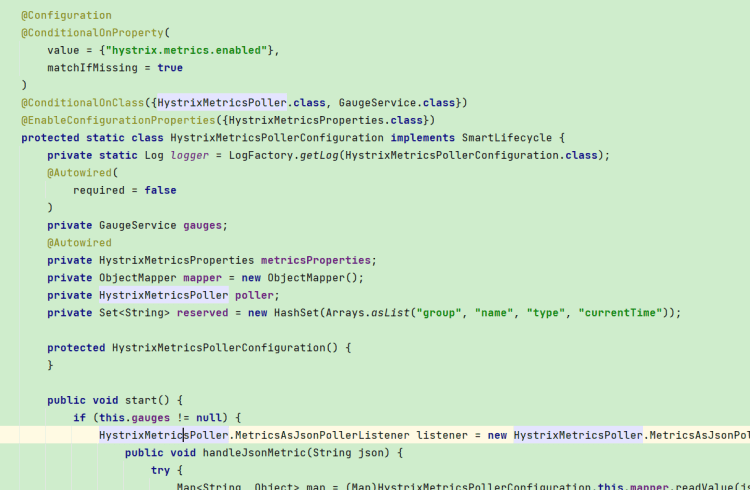
类开启,主要依靠hystrix.metrics.enabled开启,但是默认是true,为什么其他项目没有开启呢?
搜了下源码,这个类的开启还和一个注解有关

对比了一下代码,果然只有异常的应用使用了这个注解,这个注解的目的是开启断路器
但是研究之后发现,不使用这个注解,熔断等功能依旧可用,原因是在spring-cloud高版本之后,spring通过使用hystrix封装openfeign的方法来使用熔断,而不是集成整个hystrix体系,可能spring-cloud也发现了hystrix内存使用上的问题
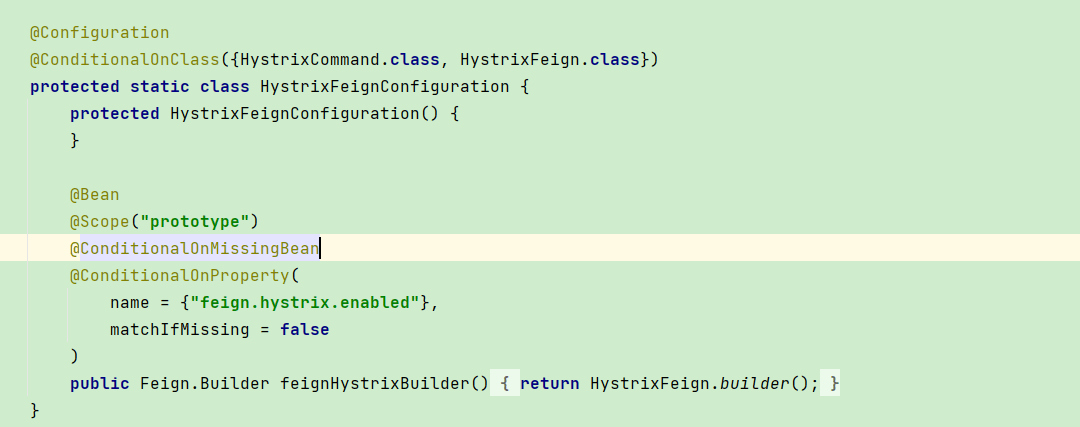
所以在较高版本(起码我们的版本),feign是通过feign.hystrix.enabled来开关断路器的(这个开关是关闭的话,单纯加@EnableCircuitBreaker注解断路器是不会生效的)
其实在更高点版本的spring-cloud中,@EnableCircuitBreaker这个注解已经被标注为废弃了,但是可能因为我们是中间版本,所以存在既没有标注废弃其实又没有什么用的情况
总而言之,feign的断路功能只通过feign.hystrix.enabled来控制,增加@EnableCircuitBreaker注解之后仅仅只是会开启Hystrix其他所有的指标等功能
问题总结
问题根本原因
本次问题产生的根本原因是因为开启了@EnableCircuitBreaker注解,开启了Hystrix指标功能,导致Histogram实例大量进入老年代,只有full gc才可以回收
Histogram本身是Hystrix用来实现类似桶+滑动窗口的功能,来统计单位时间内的流量,但是因为开启了指标参数,导致hystrix为了统计更长时间范围内的指标,新增了对象持有更多(单位时间内)的Histogram引用来聚合,这部分引用因为是统计更长时间范围周期的,在访问量上升新生代复制速度变快时,就会因为引用持有时间长而到老年代,但是本质并不是内存泄漏,所以每次full gc后又可以得到回收
后续关注点 Spring-Cloud本身体系比较复杂,因为和Netfilx套件纠缠不清加上很多历史原因,能用明白某一个版本的就很不错了 开发本身并不了解这个版本断路器到底怎么开启,没有仔细看过对应版本的官方文档就去使用注解,在老版本,断路器确实是通过这个注解才能启用的 解决方式
关闭metric功能或者去掉@EnableCircuitBreaker注解均可解决
百度spring-cloud教程和文档时,一定一定一定要看对应版本的,否则可能加一堆配置解决某个问题,结果开启一大堆乱七八糟的功能
到此这篇关于java内存异常使用导致full gc频繁的文章就介绍到这了,更多相关java内存异常导致full gc频繁内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java中内存异常StackOverflowError与OutOfMemoryError详解
Java中内存异常StackOverflowError与OutOfMemoryError详解 使用Java开发,经常回遇到内存异常的情况,而StackOverflowError和OutOfMemoryError便是最常遇见的错误. 首先,看看这两种错误的解释: 如果当前线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常. 如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常. 这里把异常分为两种情况,但是存在一些相互重
-
Java full gc触发情况实例解析
前言 近期被问及这个问题,在此记录整理一下. System.gc()方法的调用 此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数.强烈影响系建议能不使用此方法就别使用,让虚拟机自己去管理它的内存,可通过通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc. 老年代空间不足 老年代空间只有在新生代对象转入及创建为大对象.大数组时才会出现不足的现象,当执行F
-
关于HttpClient 引发的线程太多导致FullGc的问题
CloseableHttpClient httpClient = HttpClients.custom() .setConnectionManager(connectionManager) .setMaxConnTotal(400) .setMaxConnPerRoute(150) .evictExpiredConnections() .build(); evictExpiredConnections 这个配置作用: 设置一个定时线程,定时清理闲置连接,可以将这个定时时间设置为 keep ali
-
解析Java内存分配和回收策略以及MinorGC、MajorGC、FullGC
目录 对象内存分配与回收策略 对象何时进入新生代.老年代 三种GC介绍 MinorGC Major GC/Full GC: 图示GC过程 对象内存分配与回收策略 对象的内存分配,往大方向讲,就是在堆上分配[但也可能经过JIT编译后被拆散为标量类型并间接地栈上分配),对象主要分配在新生代的Eden区上,如果启动了本地线程分配缓冲,将按线程优先在TLAB上分配.少数情况下也可能会直接分配在老年代中. 对象优先分配在Eden区,当Eden区可用空间不够时会进行MinorGC 大对象直接进入老年代:大对
-
一次诡异的full gc查找问题全过程
背景 一个服务突然所有机器开始频繁full gc.而服务本身没有任何改动和发布记录.上线查看gc log日志,日志如下: 从日志来看,每次发生full gc的时候都比较奇怪,主要有两点,第一.old区域和perm的区域使用率很低,没有到达触发full gc的条件,第二.项目中配置的是CMS,为什么没有进行 CMS GC,直接进行了full gc呢. 查找过程 第一.代码会不会是调用了System.gc() 考虑在使用direct memory的时候,先判断direct memory是否足够,要是
-
Sharding Jdbc批量操作引发fullGC解决
目录 正文 内存分析 为什么有这个 LocalCache 呢? 解决方案 正文 周五晚上告警群突然收到了一条告警消息,点开一看,应用 fullGC 了. 于是赶紧联系运维下载堆内存快照,进行分析. 内存分析 使用 MemoryAnalyzer 打开堆文件 mat 下载地址:https://www.jb51.net/zt/matlab.html 下载下来后需要调大一下 MemoryAnalyzer.ini 配置文件里的-Xmx2048m 打开堆文件后如图: 发现有 809MB 的一个占用,应该问题
-
学习JVM之java内存区域与异常
一.前言 java是一门跨硬件平台的面向对象高级编程语言,java程序运行在java虚拟机上(JVM),由JVM管理内存,这点是和C++最大区别:虽然内存有JVM管理,但是我们也必须要理解JVM是如何管理内存的:JVM不是只有一种,当前存在的虚拟机可能达几十款,但是一个符合规范的虚拟机设计是必须遵循<java 虚拟机规范>的,本文是基于HotSpot虚拟机描述,对于和其它虚拟机有区别会提到:本文主要描述JVM中内存是如何分布.java程序的对象是如何存储访问.各个内存区域可能出现的异常. 二.
-
Java内存区域与内存溢出异常详解
Java内存区域与内存溢出异常 概述 对于 C 和 C++程序开发的开发人员来说,在内存管理领域,程序员对内存拥有绝对的使用权,但是也要主要到正确的使用和清理内存,这就要求程序员有较高的水平. 而对于 Java 程序员来说,在虚拟机的自动内存管理机制的帮助下,不再需要为每一个 new 操作去写配对的 delete/free 代码,而且不容易出现内存泄漏和内存溢出问题,看起来由虚拟机管理内存一切都很美好.不过,也正是因为 Java 程序员把内存控制的权力交给了 Java 虚拟机,一旦出现内存泄漏和
-
浅谈java内存管理与内存溢出异常
说到内存管理,笔者这里想先比较一下java与C.C++之间的区别: 在C.C++中,内存管理是由程序员负责的,也就是说程序员既要完成繁重的代码编写工作又要时常考虑到系统内存的维护 在java中,程序员无需考虑内存的控制和维护,而是交由JVM自动管理,这样就不容易出现内存泄漏和溢出的问题.然而,一旦出现内存泄漏和溢出方面的问题,如果不了解JVM的内存管理机制就很难找到错误所在. 1.JVM运行时数据区 JVM在运行java程序的时候会将它所管理的内存划分为若干个不同的区域,这些区域不仅有自己的用途
-
基于Java内存溢出的解决方法详解
一.内存溢出类型1.java.lang.OutOfMemoryError: PermGen spaceJVM管理两种类型的内存,堆和非堆.堆是给开发人员用的上面说的就是,是在JVM启动时创建:非堆是留给JVM自己用的,用来存放类的信息的.它和堆不同,运行期内GC不会释放空间.如果web app用了大量的第三方jar或者应用有太多的class文件而恰好MaxPermSize设置较小,超出了也会导致这块内存的占用过多造成溢出,或者tomcat热部署时侯不会清理前面加载的环境,只会将context更改
-
Java内存各部分OOM出现原因及解决方法(必看)
一,jvm内存区域 1,程序计数器 一块很小的内存空间,作用是当前线程所执行的字节码的行号指示器. 2,java栈 与程序计数器一样,java栈(虚拟机栈)也是线程私有的,其生命周期与线程相同.通常存放基本数据类型,对象引用(一个指向对象起始地址的引用指针或一个代表对象的句柄),reeturnAddress类型(指向一条字节码指令的地址) 栈区域有两种异常类型:如果线程请求的栈深度大于虚拟机所允许的深度,将抛StrackOverflowError异常:如果虚拟机栈可以动态扩展(大部分虚拟机都可动
-
快速定位Java 内存OOM的问题
Java服务出现了OOM(Out Of Memory)问题,总结了一些相对通用的方案,希望能帮助到Java技术栈的同学. 某Java服务(假设PID=10765)出现了OOM,最常见的原因为: 有可能是内存分配确实过小,而正常业务使用了大量内存 某一个对象被频繁申请,却没有释放,内存不断泄漏,导致内存耗尽 某一个资源被频繁申请,系统资源耗尽,例如:不断创建线程,不断发起网络连接 画外音:无非"本身资源不够""申请资源太多""资源耗尽"几个原因.
-
Java 内存安全问题的注意事项
前言 Java在内存管理方面是要比C/C++更方便的,不需要为每一个对象编写释放内存的代码,JVM虚拟机将为我们选择合适的时间释放内存空间,使得程序不容易出现内存泄漏和溢出的问题 不过,也正是因为Java把内存控制的权利交给了Java虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎么使用内存的,那排查错误将会成为一项异常艰难的工作 下面先看看JVM如何管理内存的 内存管理 根据Java虚拟机规范(第3版) 的规定,Java虚拟机所管理的内存将会包括以下几个运行内存数据区域: 线程隔
-
浅谈Java内存区域与对象创建过程
一.java内存区域 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有的区域则依赖用户线程的启动和结束而建立和销毁.根据<Java虚拟机规范(JavaSE7版)>的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域. 1.程序计数器(线程私有) 程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码
-
浅析Java内存模型与垃圾回收
1.Java内存模型 Java虚拟机在执行程序时把它管理的内存分为若干数据区域,这些数据区域分布情况如下图所示: 程序计数器:一块较小内存区域,指向当前所执行的字节码.如果线程正在执行一个Java方法,这个计数器记录正在执行的虚拟机字节码指令的地址,如果执行的是Native方法,这个计算器值为空. Java虚拟机栈:线程私有的,其生命周期和线程一致,每个方法执行时都会创建一个栈帧用于存储局部变量表.操作数栈.动态链接.方法出口等信息. 本地方法栈:与虚拟机栈功能类似,只不过虚拟机栈为虚拟机执行J