JDK9为何要将String的底层实现由char[]改成了byte[]
目录
- 一、为什么要优化 String 节省内存空间
- 二、byte[] 为什么就能节省内存空间呢?
- 三、为什么用UTF-16而不用UTF-8呢?
如果你不是 Java8 的钉子户,你应该早就发现了:String 类的源码已经由 char[] 优化为了 byte[] 来存储字符串内容,为什么要这样做呢?
开门见山地说,从 char[] 到 byte[],最主要的目的是为了节省字符串占用的内存。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。
一、为什么要优化 String 节省内存空间
我们使用 jmap -histo:live pid | head -n 10 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
以我正在运行着的编程喵喵项目实例(基于 Java 8)来说,结果是这样的。
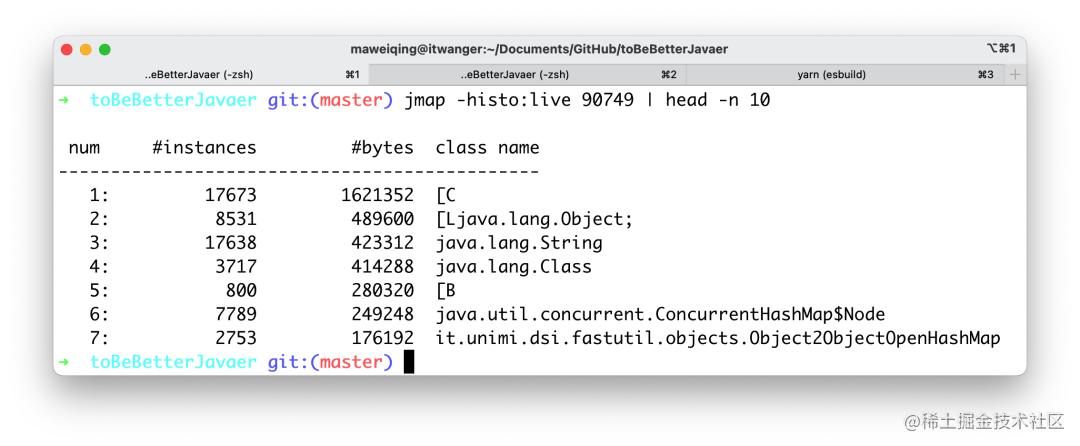
其中 String 对象有 17638 个,占用了 423312 个字节的内存,排在第三位。
由于 Java 8 的 String 内部实现仍然是 char[],所以我们可以看到内存占用排在第 1 位的就是 char 数组。
char[] 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。
那也就是说优化 String 节省内存空间是非常有必要的,如果是去优化一个使用频率没有 String 这么高的类库,就显得非常的鸡肋。
二、byte[] 为什么就能节省内存空间呢?
众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-8 编码,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
也就是说,使用 char[] 来表示 String 就导致了即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
而实际开发中,单字节的字符使用频率仍然要高于双字节的。
当然了,仅仅将 char[] 优化为 byte[] 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
换句话说,对于:
String name = "jack";
这样的,使用 Latin-1 编码,占用 4 个字节就够了。
但对于:
String name = "小二";
这种,木的办法,只能使用 UTF16 来编码。
针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;
Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
也就是说,从 char[] 到 byte[],中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节。
三、为什么用UTF-16而不用UTF-8呢?
在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
- 如果只有一个字节,那么最高的比特位为 0;
- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:一个字节;
- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
那有小伙伴可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00DFFF 之间的双字节存储。
但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
所以UTF-16在Java的世界里,就可以视为一个定长的编码。
到此这篇关于JDK9为何要将String的底层实现由char[]改成了byte[]的文章就介绍到这了,更多相关JDK9 char[]改成了byte[]内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
JDK9的新特性之String压缩和字符编码的实现方法
简介 String的底层存储是什么?相信大部分人都会说是数组.如果要是再问一句,那么是以什么数组来存储呢?相信不同的人有不同的答案. 在JDK9之前,String的底层存储结构是char[],一个char需要占用两个字节的存储单位. 据说是JDK的开发人员经过调研了成千上万的应用程序的heap dump信息,然后得出了一个结论:大部分的String都是以Latin-1字符编码来表示的,只需要一个字节存储就够了,两个字节完全是浪费. 据说他们用了大数据+人工智能,得出的结论由不得我们不信. 于是在
-
JDK9对String字符串的新一轮优化
String类可以说是Java编程中使用最多的类了,如果能对String字符串的性能进行优化,那么程序的性能必然能大幅提升. 这不JDK9就对String字符串进行了改进升级,在某些场景下可以让String字符串内存减少一半,进而减少JVM的GC次数. String的底层存储 在面试的时候我们通常会说String字符串有不可变的特性,每次都要创建新的字符串.那么,为什么String字符串是不可变的呢? 先来看一下String字符串的底层存储结构: public final class Strin
-
![JDK9为何要将String的底层实现由char[]改成了byte[]](/assets/blank.gif)
JDK9为何要将String的底层实现由char[]改成了byte[]
目录 一.为什么要优化 String 节省内存空间 二.byte[] 为什么就能节省内存空间呢? 三.为什么用UTF-16而不用UTF-8呢? 如果你不是 Java8 的钉子户,你应该早就发现了:String 类的源码已经由 char[] 优化为了 byte[] 来存储字符串内容,为什么要这样做呢? 开门见山地说,从 char[] 到 byte[],最主要的目的是为了节省字符串占用的内存.内存占用减少带来的另外一个好处,就是 GC 次数也会减少. 一.为什么要优化 String 节省内存空间 我
-
Go语言模型:string的底层数据结构与高效操作详解
Golang的string类型底层数据结构简单,本质也是一个结构体实例,且是const不可变. string的底层数据结构 通过下面一个例子来看: package main import ( "fmt" "unsafe" ) // from: string.go 在GoLand IDE中双击shift快速找到 type stringStruct struct { array unsafe.Pointer // 指向一个 [len]byte 的数组 length in
-
Java编程中的性能优化如何实现
String作为我们使用最频繁的一种对象类型,其性能问题是最容易被忽略的.作为Java中重要的数据类型,是内存中占据空间比较大的一个对象.如何高效地使用字符串,可以帮助我们提升系统的整体性能. 现在,我们就从String对象的实现.特性以及实际使用中的优化这几方面来入手,深入理解以下String的性能优化. 在这之前,首先看一个问题.通过三种方式创建三个对象,然后依次两两匹配,得出的结果是什么?答案留到最后揭晓. String str1 = "abc"; String str2 =
-
详解Java中String,StringBuffer和StringBuilder的使用
目录 1.String类 2.String对象创建的两种方式 3.String常用方法 4.StringBuffer String和StringBuffer的转换 StringBuffer的常用方法 5.StringBuilder 1.String类 字符串广泛应用 在 Java 编程中,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串. String对象实现了Serializable接口,说明String对象可以串行化(在网络中进行传输),同时实现了Comp
-
C++中CString string char* char 之间的字符转换(多种方法)
首先解释下三者的含义 CString 是一种很有用的数据类型.它们很大程度上简化了MFC中的许多操作(适用于MFC框架),使得MFC在做字符串操作的时候方便了很多.需要包含头文件#include <afx.h> C++是字符串,功能比较强大.要想使用标准C++中string类,必须要包含#include <string>// 注意是<string>,不是<string.h>,带.h的是C语言中的头文件.Char * 专门用于指以'\0'为结束的字符串. 以下
-
浅谈JVM中的JOL
JOL简介 JOL的全称是Java Object Layout.是一个用来分析JVM中Object布局的小工具.包括Object在内存中的占用情况,实例对象的引用情况等等. JOL可以在代码中使用,也可以独立的以命令行中运行.命令行的我这里就不具体介绍了,今天主要讲解怎么在代码中使用JOL. 使用JOL需要添加maven依赖: <dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-co
-
详解Java代码常见优化方案
首先,良好的编码规范非常重要.在 java 程序中,访问速度.资源紧张等问题的大部分原因,都是代码不规范造成的. 单例的使用场景 单例模式对于减少资源占用.提高访问速度等方面有很多好处,但并不是所有场景都适用于单例. 简单来说,单例主要适用于以下三个方面: 多线程场景,通过线程同步来控制资源的并发访问. 多线程场景,控制数据共享,让多个不相关的进程或线程之间实现通信(通过访问同一资源来控制). 控制实例的产生,单例只实例化一次,以达到节约资源的目的: 不可随意使用静态变量 当某个对象被定义为 s
-
asp.net登录验证码实现方法
前端添加的标签和方法: 验证码: 复制代码 代码如下: <input id="txtVerifyCode" type="text" maxlength="5" style="line-height: 30px; height: 30px; width: 80px;border:solid 1px #d4d4d4;" class="input"/> <img src=&qu
-
使用PBFunc在Powerbuilder中支付宝当面付款功能
在PB实现支付宝当面付的功能,需要先在支付宝进行商户签约,并设置相关的公钥信息(具体参考支付宝文档). 然后使用对应的私钥文件对参数进RSAWithSha1前面计算.具体代码如下: string ls_pubFileName,ls_priFileName n_pbfunc_cryp lnv_cryp ls_priFileName ="D:\pbfunclib_pri.pem"//私钥文件 string ls_str string ls_appId,ls_secret,ls_biz_co
-
在.NET Core类库中使用EF Core迁移数据库到SQL Server的方法
前言 如果大家刚使用EntityFramework Core作为ORM框架的话,想必都会遇到数据库迁移的一些问题. 起初我是在ASP.NET Core的Web项目中进行的,但后来发现放在此处并不是很合理,一些关于数据库的迁移,比如新增表,字段,修改字段类型等等,不应该和最上层的Web项目所关联,数据的迁移文件放到这里也感觉有点多余,有点乱乱的感觉,所以才想着单独出来由专门的项目进行管理会比较好,也比较清晰! 注意目标框架选择的是.NET Core 2.0而不是.NET Standard 2.0.